When AI Writes the Code, Verification Becomes the Job
Over 80% of developers now regularly use AI assistants for code generation 1. GitHub's CEO predicts that Copilot will soon write 80% of all code 2. These numbers sound like productivity gains. Here's what keeps me up at night: at least 62% of AI-generated code contains vulnerabilities 3.
We're approaching a moment where AI generates code faster than humans can review it. Traditional code review assumed a human wrote the code and understood it. Testing assumed someone anticipated the failure modes. Neither assumption holds when a model produces thousands of lines in seconds.
The implication is stark. If AI writes most of your code and most of that code is vulnerable, then your primary job as an engineer is no longer writing code. It is verifying code.
The Testing Trap
The natural response is more testing. Write more unit tests. Add integration tests. Run static analysis. The problem is that testing can only prove the presence of bugs, never their absence.
Consider what happens when developers iteratively refine AI-generated code. You might expect quality to improve with each pass. The opposite occurs. Research shows a 37.6% increase in critical vulnerabilities after just five iterations of AI-assisted refinement 4. First iterations showed an average of 2.1 vulnerabilities per sample. By iterations 8-10, that number climbed to 6.2 vulnerabilities per sample 56.
This is not intuitive. We expect iteration to improve quality. But AI models do not reason about security invariants the way human experts do. They optimize for what looks correct, not what is provably correct.
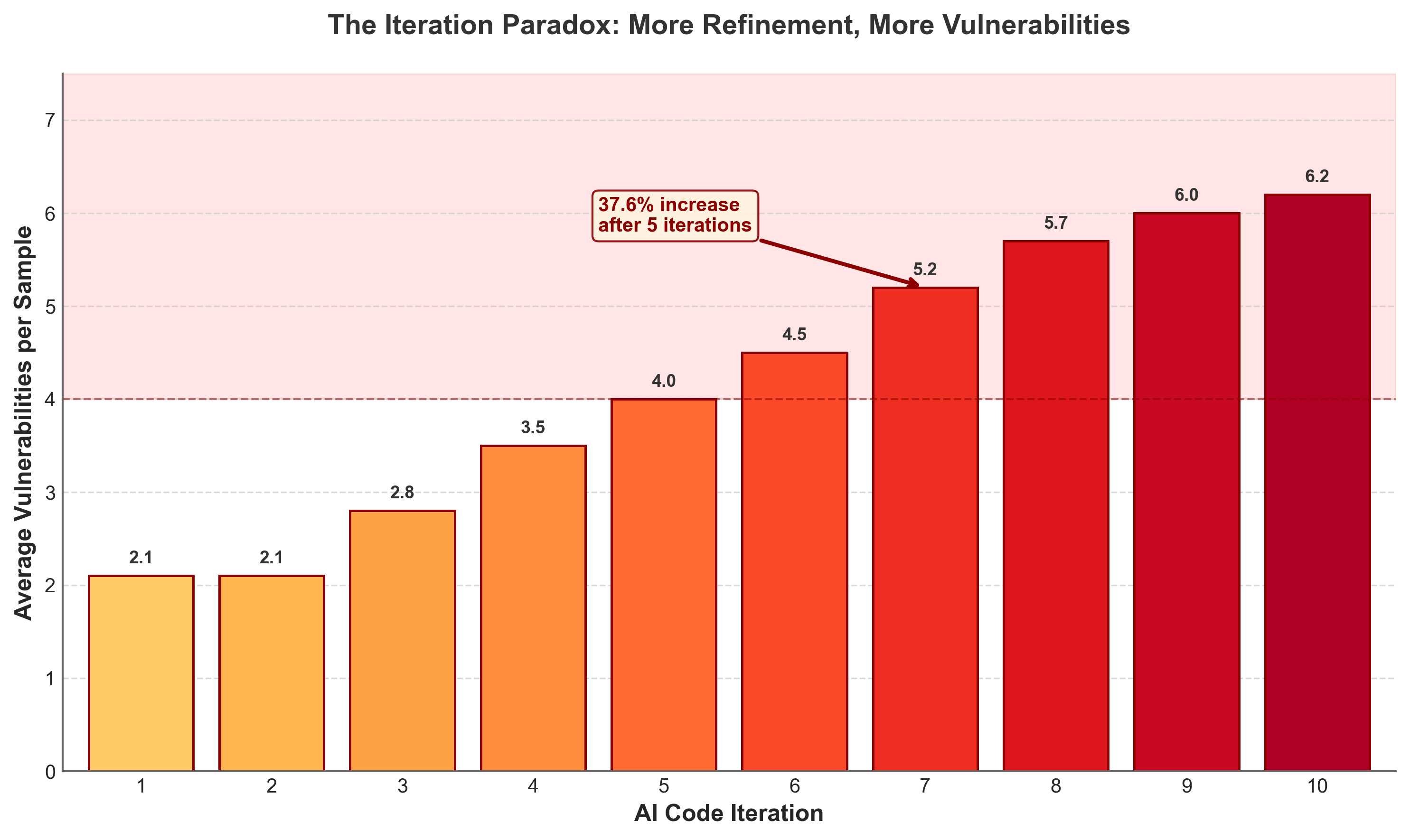 Figure 1: Security degradation across AI code iterations. Data source: Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025 456.
Figure 1: Security degradation across AI code iterations. Data source: Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025 456.
The problem compounds with prompting strategy. Efficiency-focused prompts produce code with memory safety issues 42.7% of the time 7. Feature-focused prompting was associated with the most vulnerabilities (158 in one study), while security-focused prompting produced the fewest (38), but even that baseline remains unacceptable for production systems 8.
Testing catches bugs you anticipate. It cannot find bugs you don't know exist. Verification proves their absence.
What Formal Verification Actually Means
Formal verification uses mathematical proofs to establish that code behaves correctly for all possible inputs, not just the ones you tested. Where testing says "I checked these cases and they passed," verification says "I proved these properties hold universally."
This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, eliminating the possibility of false positive reports 9. When verification finds a bug, it provides a concrete example demonstrating exactly how the code fails. When verification passes, the property is mathematically guaranteed.
Complete formal verification is the only known way to guarantee that a system is free of programming errors 10.
That's not marketing language. It is a statement about what is logically possible.
Two Existence Proofs
Theory is cheap. Deployed systems are convincing.
seL4 is a microkernel comprising 8,700 lines of C code and 600 lines of assembler 11. It is the first-ever general-purpose OS kernel fully formally verified for functional correctness 12. The functional-correctness property proved for seL4 is much stronger and more precise than what automated techniques like model checking, static analysis, or kernel implementations in type-safe languages can achieve 13.
The seL4 team invested over 20 person-years in verification 14. That sounds expensive until you consider what it bought: mathematical proof that the binary code correctly implements the specification and nothing more. No buffer overflows. No privilege escalation. No undefined behavior. Not "we tested and didn't find any" but "we proved none can exist."
CompCert demonstrates verification at a different layer: the compiler itself. CompCert is a compiler from Clight (a large subset of C) to PowerPC assembly code that is accompanied by a machine-checked proof of semantic preservation 15. The generated machine code behaves exactly as prescribed by the semantics of the source program 16.
Why does this matter? The compiler could appear as a weak link in the chain that goes from specifications to executables 17. You can verify your source code perfectly, but if the compiler introduces a bug during translation, your guarantees evaporate. CompCert closes that gap.
Both remain actively maintained and deployed in production systems. Both prove that full formal verification of substantial software is achievable.
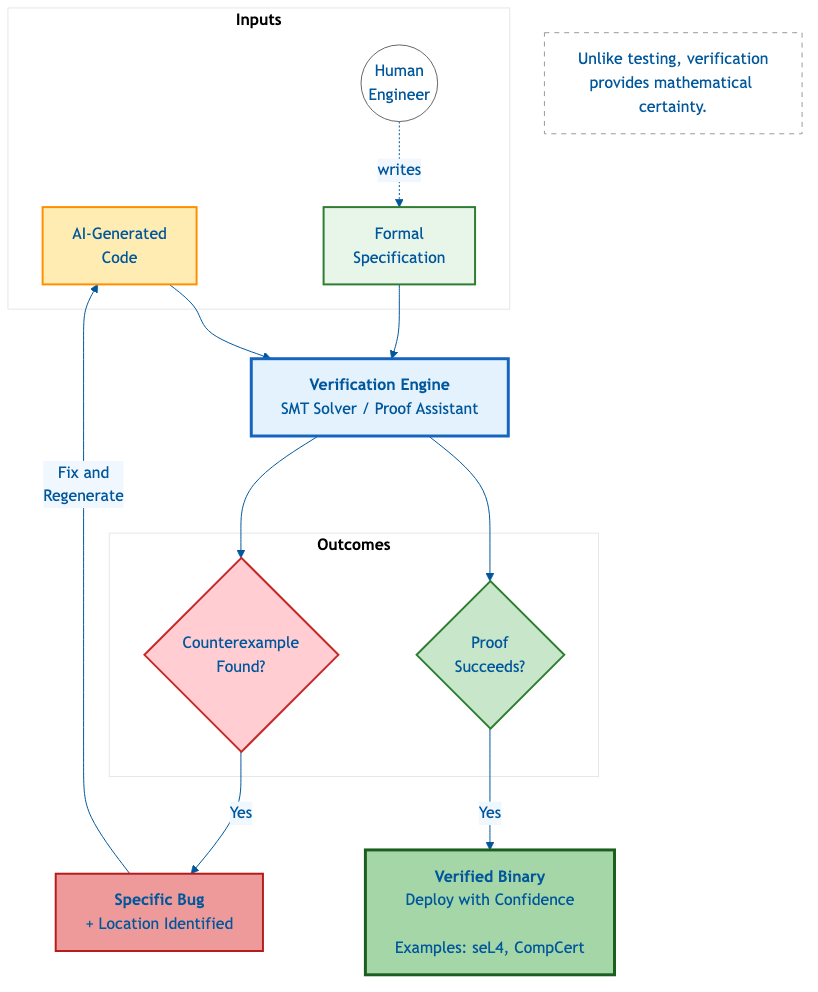 Figure 2: Unlike testing, verification provides mathematical certainty. seL4 and CompCert demonstrate this approach works at scale.
Figure 2: Unlike testing, verification provides mathematical certainty. seL4 and CompCert demonstrate this approach works at scale.
The AI Verification Gap
Here's where it gets interesting. Current LLMs can generate code that compiles and runs. They cannot generate code they can prove works.
The CLEVER benchmark presents 161 formal verification problems in Lean. State-of-the-art LLMs can solve only 1 of 161 end-to-end verified code generation problems 18. GPT-4o achieves 84.5% compilation rate but only 0.6% proof success 19. Claude-3.7 shows similar numbers: 87% compiled, 0.6% proved 20.
These models write code that works. They cannot write code that is provably correct.
GPT-3.5 struggles to pinpoint the specific vulnerability accurately, let alone if multiple are present 21. The models lack the reasoning capacity to construct invariants, prove terminations, or establish the preconditions that formal verification requires.
This gap is the opportunity. If AI generates vulnerable code at scale and cannot verify its own output, verification becomes the human contribution. The skill isn't producing code; the skill is specifying what correct code looks like and proving the generated code matches.
The Virtuous Cycle
The pessimistic reading: AI creates vulnerabilities faster than humans can find them.
The optimistic reading: AI makes verification practical by removing the bottleneck.
Creating formal specifications took annotators an average of 25 minutes per problem in the CLEVER benchmark 22. That's the human input. The machine can attempt proofs indefinitely. When verification feedback guides code regeneration, models learn to avoid vulnerability patterns. The cycle becomes: generate, verify, reject or accept, regenerate if needed.
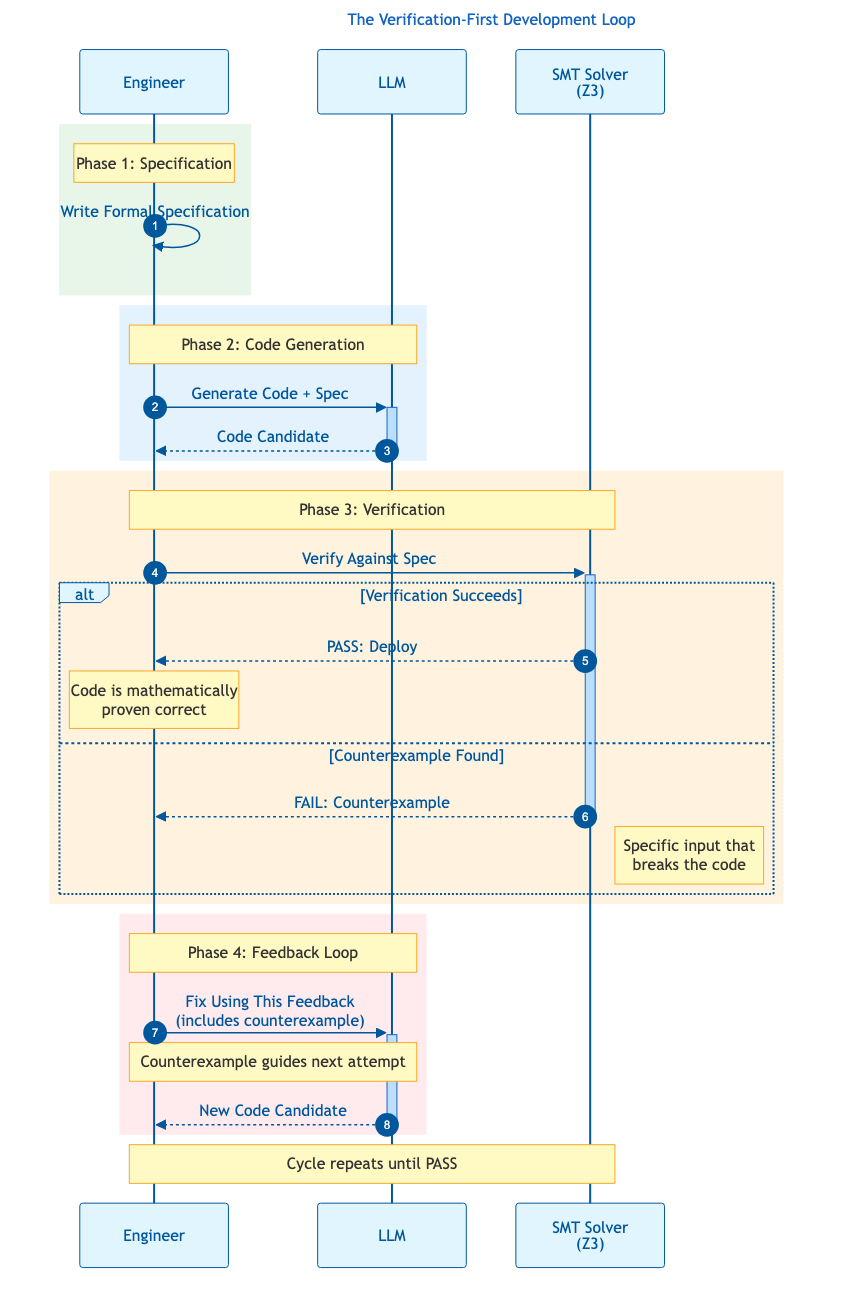 Figure 3: The verification-first development loop. Counterexamples from the SMT solver guide each iteration toward provably correct code.
Figure 3: The verification-first development loop. Counterexamples from the SMT solver guide each iteration toward provably correct code.
The practical implication: teams can choose languages and tools that make AI verification more tractable. This isn't about abandoning existing codebases but about strategic adoption for new high-risk components.
What Engineering Teams Should Do Now
Verification won't become mandatory overnight. But teams building systems where correctness matters can start now.
Start with specifications, not code. Before generating anything, write down what correct behavior looks like. Formal specifications force explicit thinking about edge cases, invariants, and failure modes. Even if you never run a proof, the specification catches errors.
Adopt verification-friendly languages for critical paths. Dafny provides the gentlest learning curve. Rust with Kani offers verification properties with mainstream language adoption. Reserve Python and JavaScript for non-critical code where velocity outweighs verification.
Build verification into CI. CBMC and similar bounded model checkers integrate with standard build systems. They catch memory safety and undefined behavior automatically. This isn't full formal verification, but it's a pragmatic step that catches categories of bugs testing misses.
Treat AI output as untrusted input. Every line of AI-generated code is a hypothesis requiring verification. This mental model changes how teams architect review processes.
Train on concepts, not just tools. Understanding invariants, preconditions, and postconditions matters more than mastering any specific proof assistant. These concepts transfer across tools and help engineers write specifications AI can work with.
The Shift Already Underway
For twenty years, we measured engineers by how fast they could write correct code. In the AI era, writing speed becomes irrelevant. Anyone with a prompt can generate code.
The differentiating skill becomes verification: the ability to specify what correct means, to recognize when generated code fails that specification, and to design systems where verification is tractable.
While LLMs offer promising capabilities for code generation, deploying their output in a production environment requires proper risk assessment and validation 23. That assessment is now the engineer's job. The validation is now the engineer's craft.
The teams that master verification will ship faster, because they'll catch entire vulnerability classes before deployment. The teams that don't will drown in security incidents, because AI-generated bugs accumulate faster than humans can manually discover them.
Twenty person-years to verify 8,700 lines of C was too expensive for most projects. When AI writes specifications and AI attempts proofs, that calculus changes. Verification becomes not the expensive luxury but the minimum viable process.
The code is going to write itself. Your job is to prove it's correct.
References
Footnotes
-
"over 80% of developers now regularly use AI assistants for code generation." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩
-
"GitHub's CEO predicting that soon, Copilot will write 80% of code." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩
-
"at least 62.07% of the generated programs are vulnerable." How Secure is AI-Generated Code: A Large-Scale Comparison of LLMs, 2024. arXiv:2404.18353 ↩
-
"37.6% increase in critical vulnerabilities after just five iterations." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩ ↩2
-
"First iterations showed relatively few vulnerabilities (average 2.1 per sample)." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩ ↩2
-
"Later iterations (8-10) showed the highest vulnerability counts (average 6.2 per sample)." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩ ↩2
-
"Efficiency-focused prompts were associated with memory safety issues (42.7%)." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩
-
"feature-focused prompting strategy was associated with the most vulnerabilities (158), while security-focused prompting was associated with the fewest (38)." Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025. arXiv:2506.11022 ↩
-
"This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports." The FormAI Dataset: Generative AI in Software Security Through Formal Verification, 2023. arXiv:2307.02192 ↩
-
"Complete formal verification is the only known way to guarantee that a system is free of programming errors." seL4: Formal Verification of an Operating-System Kernel, SOSP 2009. ↩
-
"seL4, a third-generation microkernel of L4 provenance, comprises 8,700 lines of C code and 600 lines of assembler." seL4: Formal Verification of an Operating-System Kernel, SOSP 2009. ↩
-
"seL4 is the first-ever general-purpose OS kernel that is fully formally verified for functional correctness." seL4: Formal Verification of an Operating-System Kernel, SOSP 2009. ↩
-
"The functional-correctness property we prove for seL4 is much stronger and more precise than what automated techniques like model checking, static analysis or kernel implementations in type-safe languages can achieve." seL4: Formal Verification of an Operating-System Kernel, SOSP 2009. ↩
-
"the development of seL4 was reported to take 20+ person-years." CLEVER: A Curated Benchmark for Formally Verified Code Generation, 2025. arXiv:2505.13938 ↩
-
"CompCert, a compiler from Clight (a large subset of the C programming language) to PowerPC assembly code." Formal Verification of a Realistic Compiler, Communications of the ACM, 2009. ↩
-
"By verified, we mean a compiler that is accompanied by a machine-checked proof of a semantic preservation property: the generated machine code behaves as prescribed by the semantics of the source program." Formal Verification of a Realistic Compiler, Communications of the ACM, 2009. ↩
-
"the compiler could appear as a weak link in the chain that goes from specifications to executables." Formal Verification of a Realistic Compiler, Communications of the ACM, 2009. ↩
-
"state-of-the-art LLMs can only solve up to 1/161 end-to-end verified code generation problem." CLEVER: A Curated Benchmark for Formally Verified Code Generation, 2025. arXiv:2505.13938 ↩
-
"GPT-4o: 84.472% compiled, 0.621% proved for spec certification." CLEVER: A Curated Benchmark for Formally Verified Code Generation, 2025. arXiv:2505.13938 ↩
-
"Claude-3.7: 86.957% compiled, 0.621% proved for spec certification." CLEVER: A Curated Benchmark for Formally Verified Code Generation, 2025. arXiv:2505.13938 ↩
-
"GPT-3.5 struggles to pinpoint the specific vulnerability accurately, let alone if multiple are present." The FormAI Dataset: Generative AI in Software Security Through Formal Verification, 2023. arXiv:2307.02192 ↩
-
"Creating this benchmark involved substantial manual effort. On average, writing a formal specification took annotators 25 minutes per problem." CLEVER: A Curated Benchmark for Formally Verified Code Generation, 2025. arXiv:2505.13938 ↩
-
"while LLMs offer promising capabilities for code generation, deploying their output in a production environment requires proper risk assessment and validation." How Secure is AI-Generated Code: A Large-Scale Comparison of LLMs, 2024. arXiv:2404.18353 ↩