What Are World Models? The AI Architecture That Learns to Dream
On February 15th, 2024, OpenAI released Sora, a video generation model they explicitly framed as a "world simulator"1. Just months later, Google unveiled Genie, an 11-billion parameter model designed as a foundation world model that generates playable environments from single images2. Meanwhile, Yann LeCun, Meta's chief AI scientist and Turing Award winner, has publicly argued that large language models may be a "dead end" for AGI, stating bluntly: "We're never going to get to human-level A.I. by just training on text"3.
So what are world models, and why are they suddenly everywhere? More importantly, what fundamental problem do they solve that pure language modeling cannot?
This post explains world models from the ground up: what they are, why they achieve dramatically better sample efficiency than traditional reinforcement learning, and how they're becoming essential infrastructure for robots, autonomous vehicles, and embodied agents operating in the physical world.
The Core Idea: Internal Simulators
Here's the simplest way to understand a world model: it's a system that learns to predict what happens next in an environment, given actions4.
Consider a concrete example. You're training a robot to navigate a warehouse. A traditional reinforcement learning approach (model-free RL) would have the robot try random actions millions of times, slowly learning which movements lead to rewards. But this is painfully inefficient: you're bound by real-time physics and cannot speed up time5. Training a robot to grasp objects might require extended periods of continuous operation, far beyond what's practical for most real-world deployments.
A world model takes a different approach. The robot first builds an internal simulator of the warehouse by observing it. This simulator learns: "If I move forward near a wall, I'll collide. If I turn left here, I'll reach the loading dock." Now the robot can "dream" about different navigation strategies, simulating thousands of potential paths in seconds without moving at all. It rehearses futures before they occur6.
 Figure 1: DreamerV3 architecture showing the separation between perception, dynamics modeling, and policy learning. The algorithm consists of three neural networks: the world model predicts the outcomes of potential actions, the critic judges the value of each outcome, and the actor chooses actions to reach the most valuable outcomes. Source: Mastering Diverse Domains through World Models7
Figure 1: DreamerV3 architecture showing the separation between perception, dynamics modeling, and policy learning. The algorithm consists of three neural networks: the world model predicts the outcomes of potential actions, the critic judges the value of each outcome, and the actor chooses actions to reach the most valuable outcomes. Source: Mastering Diverse Domains through World Models7
This isn't science fiction. "Dreamer learns a model of the environment and improves its behavior by imagining future scenarios," achieving performance that "outperforms tuned expert algorithms across a wide range of benchmarks and data budgets"8. The key insight: instead of learning directly from experience (model-free), the agent learns a model first, then uses that model to imagine and plan (model-based).
Why does this matter? Because sample efficiency, the amount of experience needed to learn, becomes the bottleneck when you move from simulated games to the physical world. You can't crash a self-driving car millions of times. You can't break robotic arms repeatedly. World models let agents "safely streamline and scale training"9 by dreaming about dangerous scenarios and learning to avoid them without experiencing them in reality.
The Revolution: From Reactive to Proactive AI
The difference between model-free and model-based reinforcement learning represents a fundamental architectural choice with dramatic practical consequences.
Model-free methods are notoriously data-hungry. They "require a large number of environment interactions to learn successful control policies"10, often millions of interactions. For a robot learning to manipulate objects, this means:
- Slow: You are bound by real-time physics and cannot speed up time11
- Expensive: Physical wear, human supervision costs add up quickly
- Dangerous: Agents must experience failures to learn from them
- Opaque: No explicit understanding of environment mechanics
World models flip this paradigm. By learning the environment's dynamics, they enable:
- Sample efficiency: Learning from imagined experience, not just real interactions
- Safety: Dangerous scenarios can be simulated rather than enacted
- Planning: Explicit reasoning about action consequences before executing them
- Generalization: Understanding of environment mechanics transfers to new situations
The performance gap is striking. PlaNet, one of the early neural world model architectures, "uses substantially fewer episodes and reaches final performance close to and sometimes higher than strong model-free algorithms"12, achieving substantially better sample efficiency (typically 50-100× improvements)13. Recent work shows that "larger model sizes not only achieve higher scores but also require less interaction to solve a task"14.

Figure 4: Sample efficiency comparison between model-free and model-based reinforcement learning methods across DeepMind Control Suite benchmarks. World models achieve 10-100× improvement in sample efficiency, requiring far fewer environment interactions to reach performance thresholds.
This efficiency gain becomes absolutely critical for physical AI. In autonomous driving, "recent breakthroughs have been propelled by advances in robust world modeling, fundamentally transforming how vehicles interpret dynamic scenes and execute safe decision-making"15. A world model for driving is "a generative spatio-temporal neural system that compresses multi-sensor physical observations into a compact latent state and rolls it forward under hypothetical actions, letting the vehicle rehearse futures before they occur"16.
Key Architectures: The Evolution of Neural World Models
The modern neural world model architecture has evolved through several landmark papers, each addressing specific limitations.
The 2018 Foundation: World Models (Ha & Schmidhuber)
The influential "World Models" paper established the basic three-component architecture17:
- Vision (V): A Variational Autoencoder (VAE) that dramatically compresses high-dimensional observations (e.g., reducing a 64×64 pixel image to a compact latent vector) capturing the essential features while discarding irrelevant noise18
- Memory (M): An RNN that learns temporal dynamics in latent space
- Controller (C): A simple policy network that chooses actions based on latent state
The key insight was the "separation of concerns"19: the vision system learns what matters in the scene, the memory system learns how the world evolves, and the controller focuses on choosing good actions, all while working in a dramatically compressed representation space. The VAE learns to encode visual observations efficiently, the RNN learns how the world evolves, and the controller learns to act. This modularity enabled learning world models from pixel observations in visually complex environments.
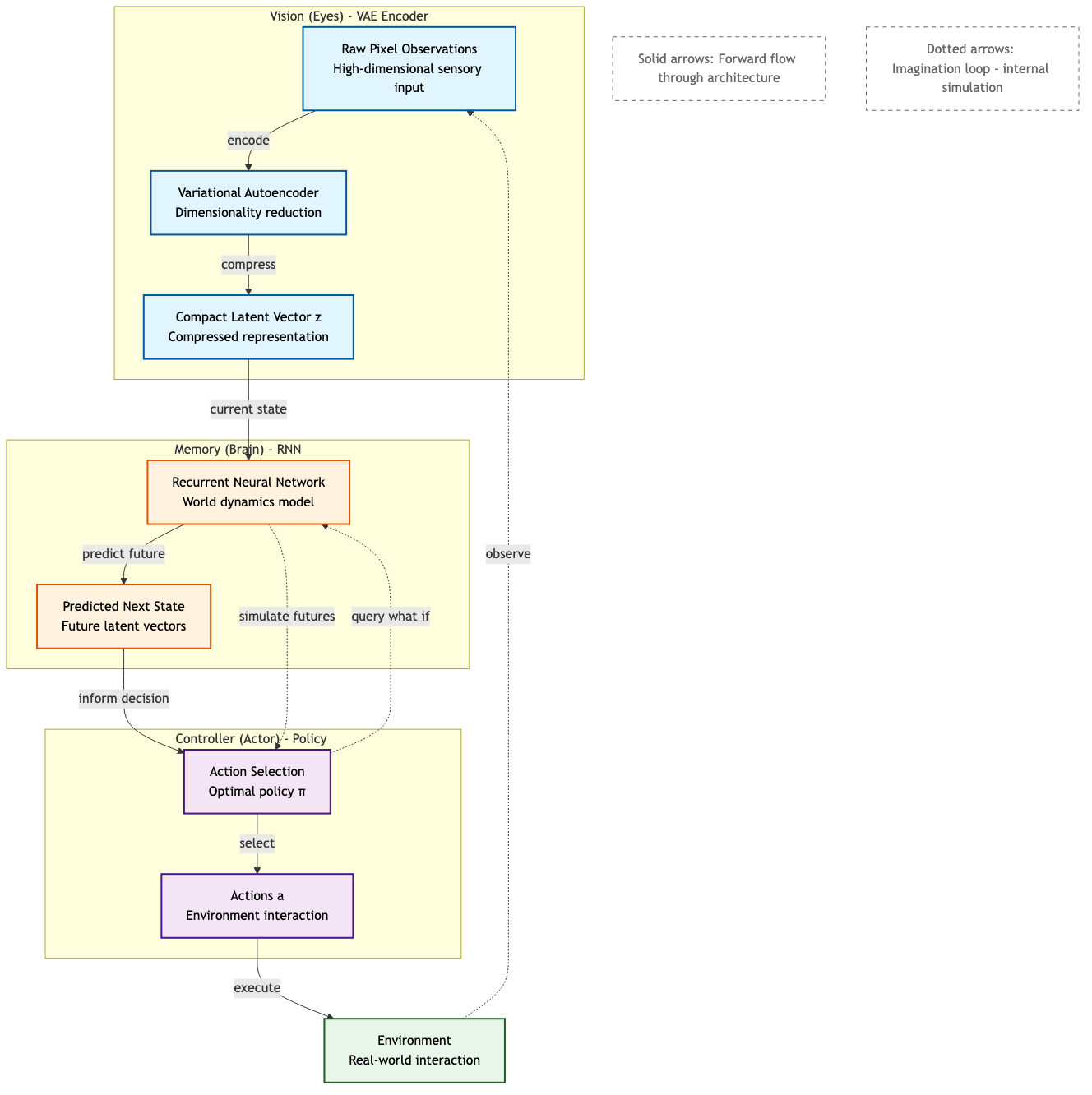
Figure 5: The Vision-Memory-Controller (V-M-C) architecture showing the flow from observations through learned representations to actions. The imagination loop (dotted arrows) enables the controller to query the memory model and simulate future scenarios without environment interaction, dramatically improving sample efficiency.
However, the V-M-C architecture had limitations: the RNN-based memory suffered from error accumulation during inference, gradient vanishing, and slow training speeds20.
PlaNet: Planning in Latent Space (2019)
PlaNet advanced the field by using its learned dynamics model directly for planning at decision time21. Rather than learning a fixed policy, PlaNet performed fast online planning in latent space using model predictive control (MPC). This enabled "planning with learned models" from pixel observations while achieving remarkable sample efficiency22.
Early neural world models like "PlaNet (Hafner et al., 2019) and the Dreamer series (Hafner et al., 2020; 2021; 2025), showed that latent dynamics can replace explicit simulators"23. The breakthrough was showing that you could achieve strong performance without ever training an explicit policy, just keep replanning at each timestep using your continually-improving world model.
The Dreamer Series: Scaling Through Simplicity
The Dreamer line of work (DreamerV1, V2, V3) refined world model learning into a robust, general-purpose algorithm. Rather than planning at every step (which is computationally expensive), Dreamer learns a permanent actor network through backpropagation from the model's predictions24, effectively training the policy on imagined experience generated by the world model.
"The algorithm consists of three neural networks: the world model predicts the outcomes of potential actions, the critic judges the value of each outcome, and the actor chooses actions to reach the most valuable outcomes"25. This clean separation enables end-to-end learning from pixels to actions.
The breakthrough came with DreamerV3, which demonstrated unprecedented generality. As stated in the abstract: "DreamerV3, a general algorithm that outperforms specialized methods across over 150 diverse tasks, with a single configuration"26. More remarkably, it achieved the landmark result of being "the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula"27.
This Minecraft achievement is significant because it requires "exploring far-sighted strategies from pixels and sparse rewards in an open world"28. Previous approaches "resorted to using human expert data and domain-specific curricula"29. The MineRL Diamond Competitions were held in 2019, 2020, and 2021, providing datasets of human expert trajectories30 precisely because researchers assumed the task was impossible without human guidance. DreamerV3 solved it through pure model-based learning.
Here's the complete DreamerV3 training loop implementation showing the three-phase architecture:
# Core three-phase training loop
for iteration in range(num_iterations):
# Phase 1: Real environment interaction (expensive!)
# Collect 100 real transitions and update world model
obs, done = env.reset(), False
for step in range(100):
action = agent.actor(state).sample()
next_obs, reward, done = env.step(action)
replay_buffer.add(obs, action, reward, next_obs, done)
obs = env.reset() if done else next_obs
# Update RSSM world model on real data
batch = replay_buffer.sample(batch_size=16)
world_model_loss = agent.update_world_model(batch)
# Phase 2: Free imagination rollouts (cheap!)
# Generate 240 synthetic transitions (16 batch × 15 horizon)
# without any environment interaction
states = []
for timestep in range(15):
action = agent.actor(state).sample()
# RSSM predicts next state WITHOUT real observation
state = agent.rssm.imagine_step(state, action)
reward = agent.reward_predictor(state)
states.append((state, action, reward))
# Phase 3: Learn from imagined experience (no environment!)
# Train actor-critic purely on the 240 imagined transitions
returns = compute_lambda_returns(states)
actor_loss = -returns.mean() # Policy gradient
critic_loss = (critic(states) - returns).pow(2).mean()
agent.actor_optimizer.zero_grad()
actor_loss.backward()
agent.actor_optimizer.step()
Figure 6: DreamerV3 achieves 10-100× sample efficiency by generating most training data through imagination (Phase 2) rather than real environment interaction (Phase 1). In this example, 240 imagined experiences are created from only 100 real interactions: a 2.4× ratio. With longer imagination horizons (50-100 steps), this ratio reaches 10-100×, explaining the dramatic efficiency gains. Full executable implementation available at assets/code/dreamerv3_training_loop.py.
The generality is remarkable. "We observe robust learning not only across over 150 tasks from the domains summarized in Figure 2, but also across model sizes and training budgets"31. The algorithm shows strong scaling properties where larger models are more sample-efficient.
Beyond Games: World Models for Physical AI
While early world model research focused on game environments, the real impact is in embodied AI: robots and autonomous systems operating in the physical world.
Autonomous Driving
In autonomous driving, "world models have emerged as a linchpin technology, offering high-fidelity representations of the driving environment that integrate multi-sensor data, semantic cues, and temporal dynamics"32. Given that "current statistics underscore that human error remains the principal cause of accidents"33, predictive world models become critical safety infrastructure.
 Figure 2: World model architecture for autonomous driving showing multi-sensor fusion, scene understanding, and predictive planning. The model compresses observations into latent states and rolls them forward under hypothetical actions, letting vehicles rehearse futures before they occur. Source: World Models for Autonomous Driving: A Survey34
Figure 2: World model architecture for autonomous driving showing multi-sensor fusion, scene understanding, and predictive planning. The model compresses observations into latent states and rolls them forward under hypothetical actions, letting vehicles rehearse futures before they occur. Source: World Models for Autonomous Driving: A Survey34
The insight is profound: a world model allows a vehicle to mentally simulate thousands of scenarios, predicting how that pedestrian might step into the road, how traffic will flow if the light changes, what happens if the car two lanes over suddenly brakes. All of this happens in milliseconds, in the model's internal simulation, before committing to a real-world action. World models enable vehicles to anticipate multi-agent interactions, predict pedestrian movements, and plan collision-free trajectories, all before executing actions in reality.
Robotic Manipulation
For robotics manipulation, "understanding the world in terms of objects and the possible interplays with them is an important cognition ability"35. Traditional world models that "indistinctly reconstruct all information in the environment can suffer from several failure modes. For instance, in visual tasks, they can ignore small, but important features for predicting the future, such as little objects"36.
This has driven development of object-centric world models. These models "aim to decompose visual scenes into object-level representations, providing structured abstractions that could improve compositional generalization and data efficiency in reinforcement learning"37. By representing the world as a collection of objects and their relationships rather than as monolithic image reconstructions, robots can more effectively reason about manipulation tasks.
Systems like FOCUS have shown that world models "can be deployed on robotics manipulation tasks to explore object interactions more easily," with demonstrations "using a Franka Emika robot arm" in "real-world settings"38. The practical implications are significant: object-centric models can learn to manipulate novel objects by understanding fundamental interaction principles (grasping, pushing, stacking) rather than memorizing pixel-level patterns.
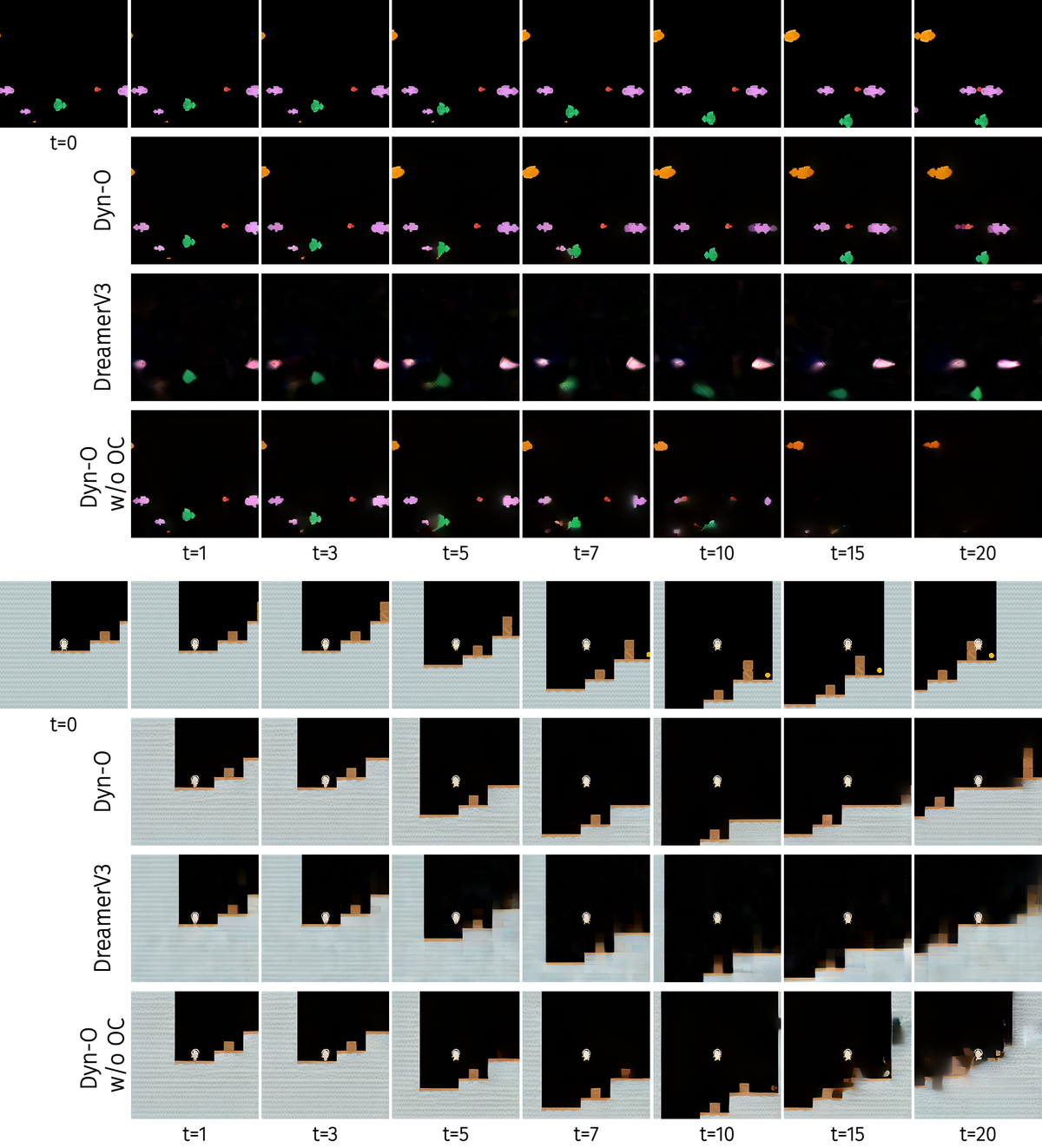 Figure 3: Object-centric world model decomposing scenes into individual objects for better manipulation planning. Rather than monolithic scene reconstruction, the model maintains separate representations for each object. Source: Building Structured World Models with Object-Centric Representations39
Figure 3: Object-centric world model decomposing scenes into individual objects for better manipulation planning. Rather than monolithic scene reconstruction, the model maintains separate representations for each object. Source: Building Structured World Models with Object-Centric Representations39
However, current object-centric models face limitations. Research identifies "representation shift during multi-object interactions as a key driver of unstable policy learning," meaning that "when used for downstream model-based control, policies trained on [object-centric] latents underperform compared to DreamerV3"40. This remains an active research frontier.
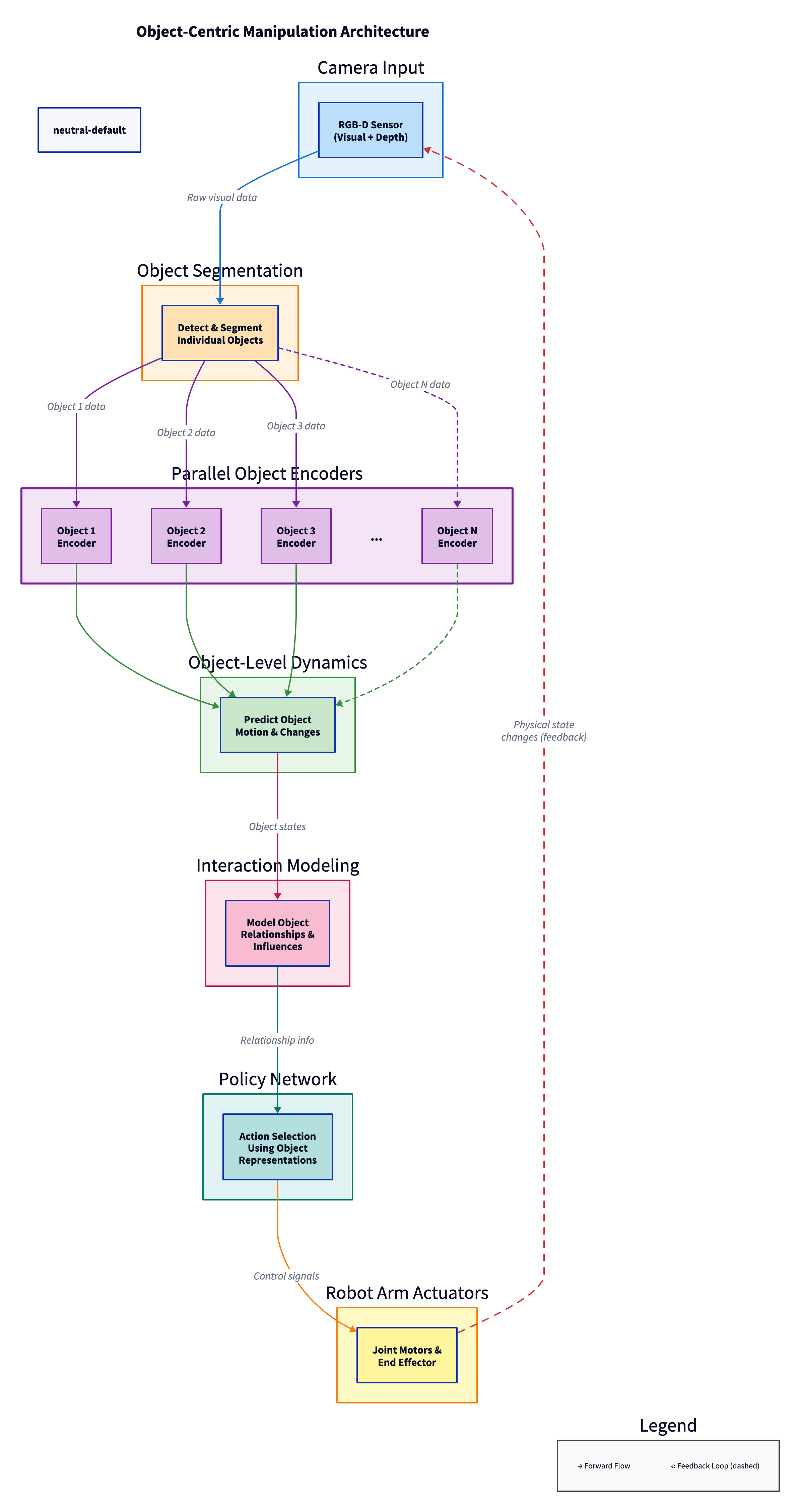
Figure 7: Object-centric manipulation architecture showing the flow from camera input through object segmentation, parallel encoding, dynamics prediction, interaction modeling, and policy generation to robot actuators. The parallel encoders (purple) process each detected object separately, enabling better generalization. The feedback loop (dashed red line) continuously updates the system based on observed physical state changes.
The Foundation Model Shift: Universal World Simulators
Recent work has shifted from task-specific world models toward foundation world models: large-scale systems trained on diverse data that can generalize broadly.
Sora: Video as World Simulation
OpenAI's Sora represents this paradigm shift. "On February 15th, 2024, OpenAI introduced a new vision foundation model that can generate video from users' text prompts. The model named Sora" was explicitly positioned as a world simulator41. OpenAI claimed that "Sora, due to being trained on a large-scale dataset of text-video pairs, has impressive near-real-world generation capability"42.
The key question is whether such models truly understand physical principles. "A generative artificial intelligence (AI) model that understands real-world mechanisms is often referred to as a world model"43, with requirements including "scalability" (emergent capabilities not seen in smaller models)44 and "generalizability" (ability to generate beyond training data distribution)45.
Research investigating this found that "visual realism does not imply physical understanding"46. Current video generation models can produce visually convincing outputs while violating basic physics: fluid dynamics, thermodynamics, mechanics. This indicates that "acquiring certain physical principles from observation alone may be possible, but significant challenges remain"47.
Genie: Generative Interactive Environments
Google's Genie takes a different approach, explicitly designed as a "foundation world model"48. The model "was trained in an unsupervised manner on a massive dataset of unlabeled Internet videos (specifically, 2D platformer games)"49. The breakthrough: "Genie can take a single prompt image (a photo, a synthetic image, or even a hand-drawn sketch) and generate an endless variety of playable (action-controllable) worlds"50.
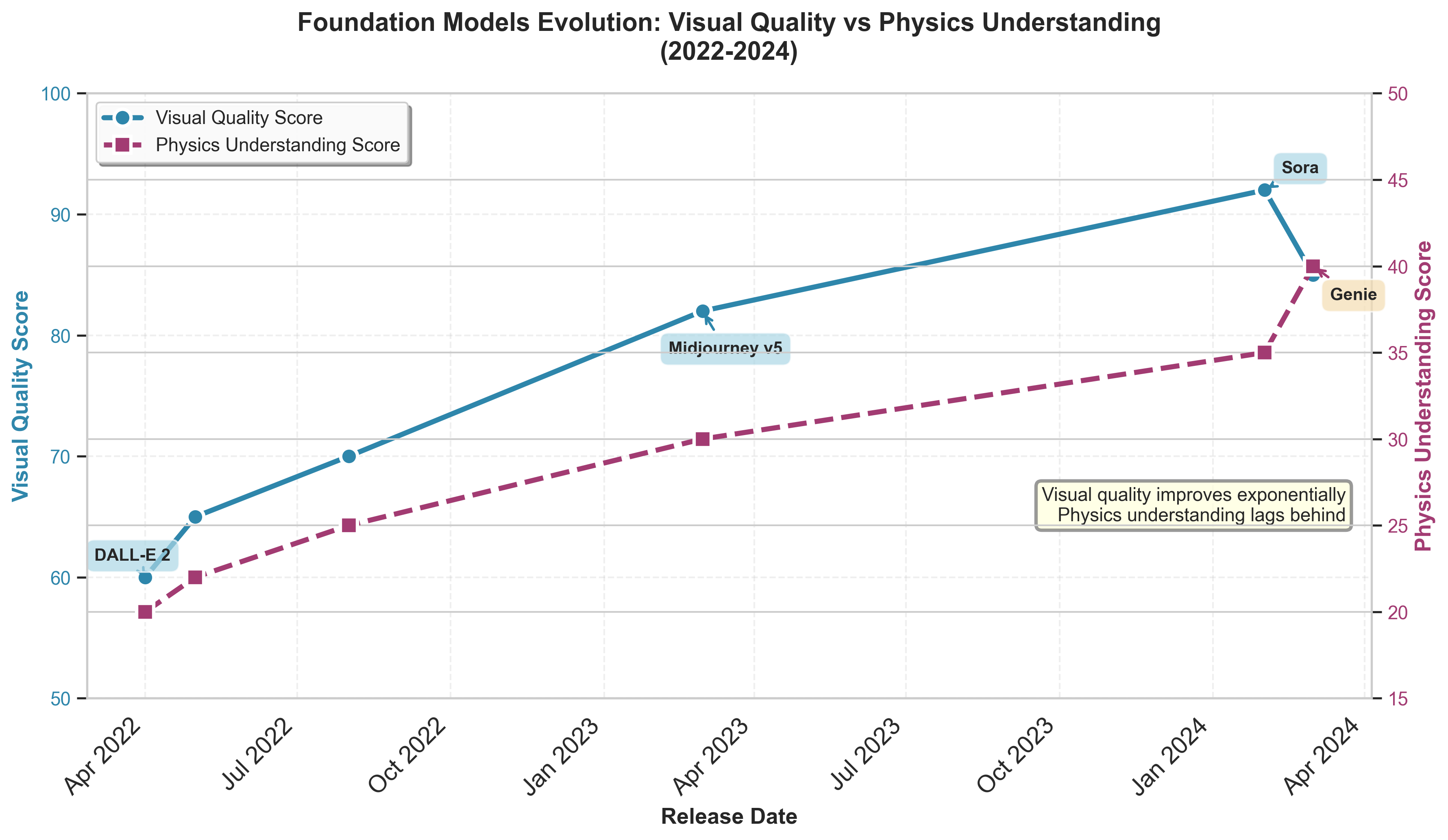
Figure 8: Evolution of foundation models showing rapid improvement in visual quality (blue line) compared to slower progress in physics understanding (purple line). Despite dramatic advances in generating realistic-looking content, models still struggle with understanding underlying physics and causal relationships. Data points represent major models from DALL-E 2 (April 2022) through Genie (March 2024).
This represents a shift from world models for specific agents to world models as general-purpose simulators. The implications for robotics and embodied AI are profound: imagine training policies in simulated worlds generated from single images of real environments.
Critical Challenges and Open Problems
Despite rapid progress, fundamental challenges remain:
Compounding Errors
World models face the "compounding error" problem: "small errors may compound over time, leading to poor long-horizon prediction"51. More specifically, "a tiny, 1% prediction error at the first step can be amplified, causing the dream to diverge from reality until, after many steps, it becomes a completely fabricated response"52.
This is why DreamerV3's success in long-horizon tasks like Minecraft is significant: it demonstrates that careful architectural choices can mitigate error accumulation even in environments requiring thousands of timesteps.
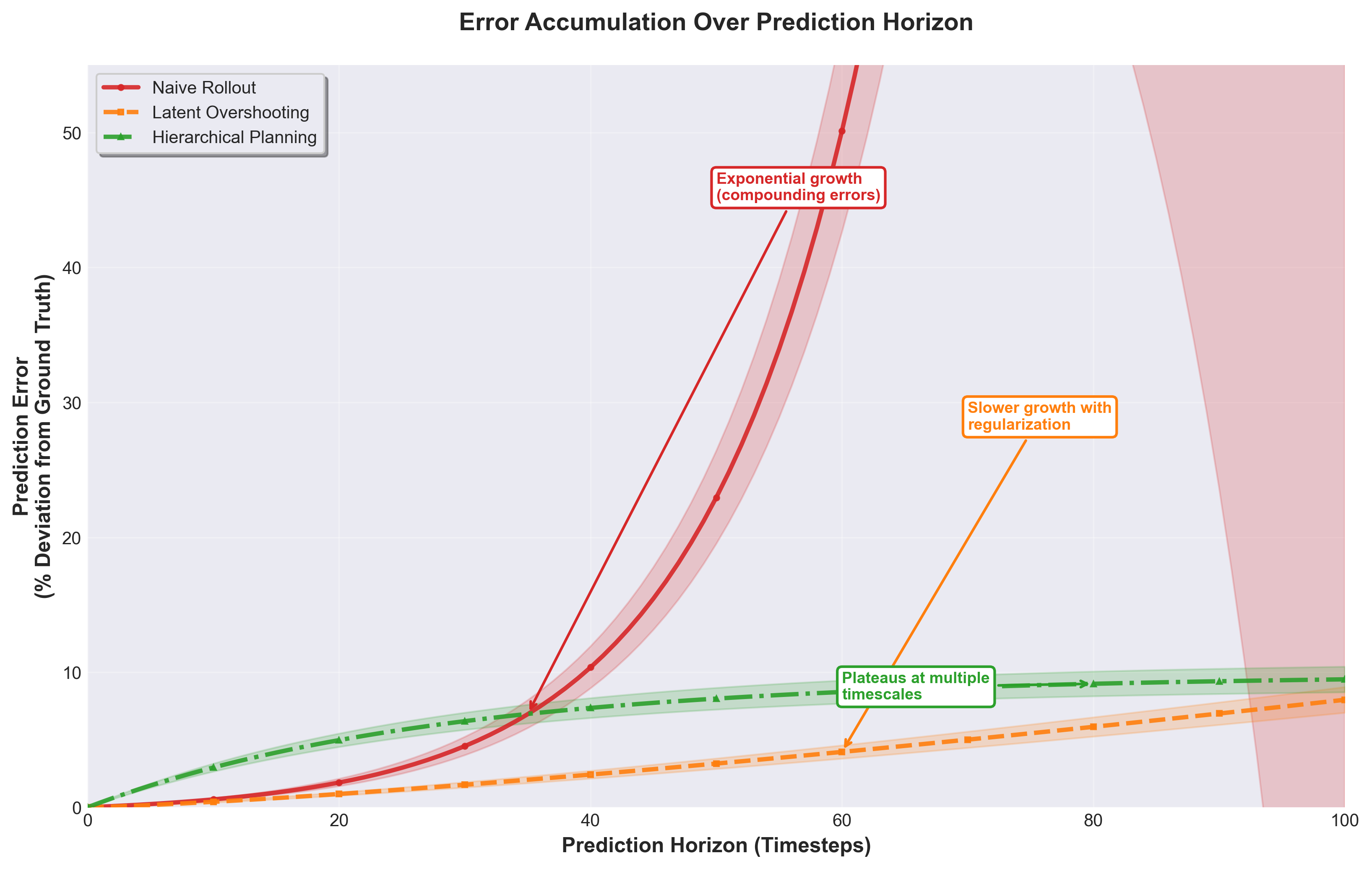
Figure 9: Error accumulation patterns for different prediction strategies in world models. Naive rollouts suffer exponential error growth, reaching 50%+ deviation after 100 timesteps. Latent overshooting provides regularization, reducing error growth rate to polynomial. Hierarchical planning achieves the most stable long-horizon predictions by operating at multiple timescales, plateauing around 10% error.
Computational Costs
Training large-scale world models remains expensive. "The estimated training cost for GPT-4 was 191 million"53. While these figures are for language models, scaling laws suggest similar costs for foundation world models trained on video and interaction data.
The Integration Challenge
Current approaches face a fundamental tension. As one analysis frames it: "MLLMs enable contextual task reasoning but overlook physical constraints, while WMs excel at physics-aware simulation but lack high-level semantics"54. The path forward likely requires integration: language models providing semantic reasoning and task decomposition, world models ensuring physical plausibility.
Comparison: Model-Free vs Model-Based Learning
To understand why world models represent such a paradigm shift, consider this direct comparison:
| Aspect | Model-Free RL | Model-Based RL (World Models) |
|---|---|---|
| Learning Approach | Direct mapping from states to actions | Learn environment dynamics, then plan |
| Sample Efficiency | Millions of interactions required | 10-100× fewer interactions needed |
| Safety | Must experience failures to learn | Can simulate dangerous scenarios |
| Interpretability | Black box policy | Explicit model of environment |
| Generalization | Poor to novel situations | Transfers through understanding mechanics |
| Computational Cost | Low during training | Higher (must learn and query model) |
| Real-time Performance | Fast policy execution | Planning can be slower |
The trade-offs are clear: world models require more computation but deliver dramatic improvements in sample efficiency and safety, critical factors for physical AI.
Why World Models Matter for AGI
There's a growing consensus among leading AI researchers that world models are essential infrastructure for general intelligence.
"Consensus among AI's foremost researchers, including Yann LeCun, Demis Hassabis, and Yoshua Bengio, is that world models are essential for building AI systems that are truly smart, scientific and safe"55. The rationale is clear: purely linguistic AI lacks grounding in physical reality. As one memorable comparison puts it: "your house cat has a more useful world model than ChatGPT"56.
The cat understands gravity, object permanence, spatial relationships, and cause-and-effect in the physical world through embodied experience. Language models, no matter how large, cannot acquire this understanding from text alone.
This doesn't diminish the value of language models; it highlights their complementary role. "A true AGI will require physical understanding, reasoning abilities, and adaptability"57. World models provide the physical grounding, language models provide semantic reasoning, and their integration may be the path to systems that understand both language and the world it describes.
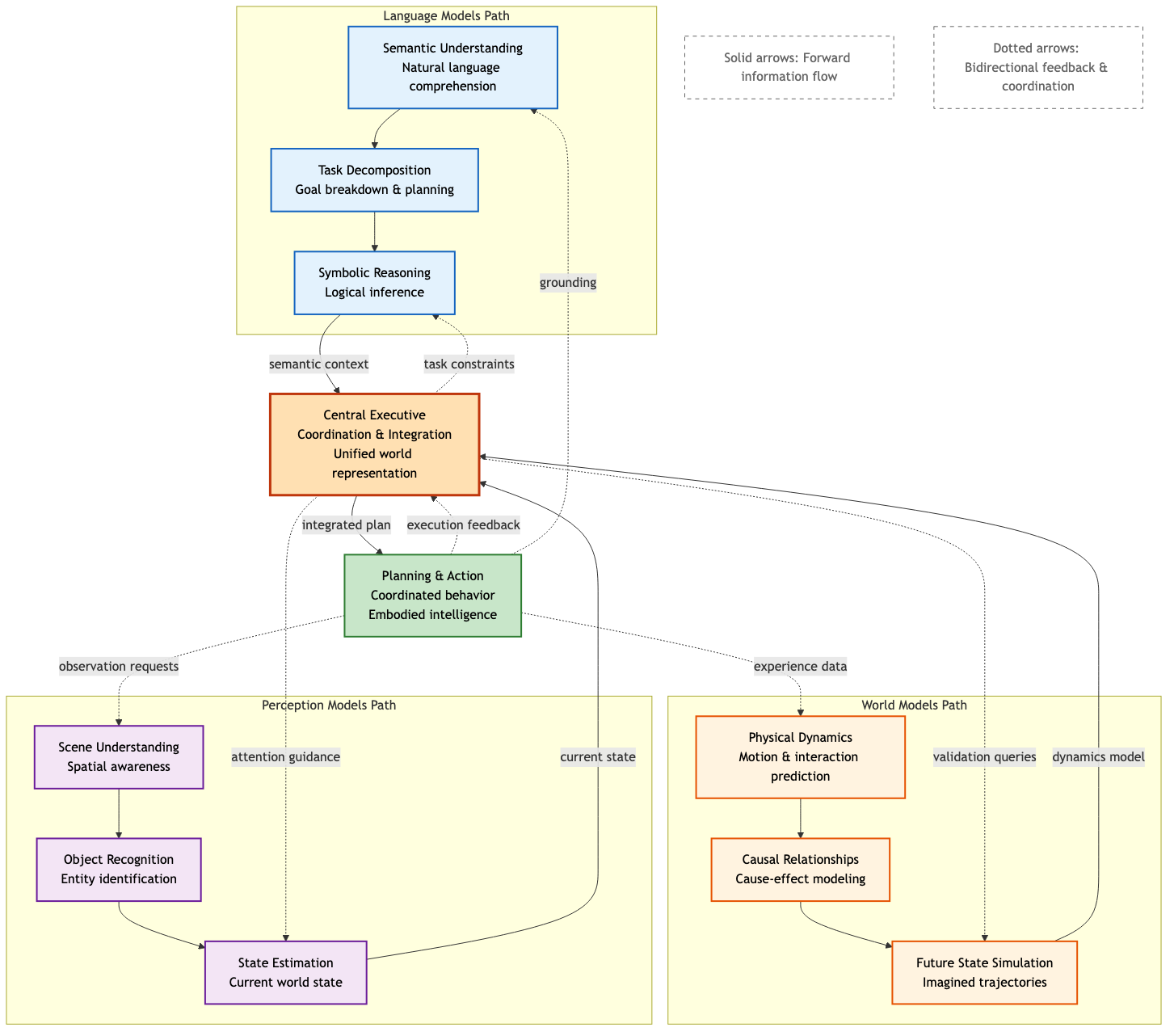
Figure 10: Integration architecture showing how world models can work alongside language models and perception models, coordinated by a central executive. Language models provide semantic understanding and task decomposition, world models provide physical dynamics and causal reasoning, and perception models provide scene understanding. Bidirectional arrows show continuous feedback and coordination between all three modalities, pointing toward more capable and general intelligent behavior.
Looking Forward
World models represent a fundamental shift in how we think about building intelligent systems. Rather than learning reactive policies that map observations directly to actions, we're building agents that understand their environment's dynamics, imagine futures, and plan deliberately.
The field has progressed from simple game environments (World Models 2018) to solving complex open-world challenges (DreamerV3 collecting Minecraft diamonds) to foundation models that generate interactive worlds (Genie). Current research is pushing toward models that combine visual realism, physical accuracy, and semantic understanding.
For practitioners, this means:
- Sample efficiency gains of 10-100× for physical AI applications
- Safer exploration through simulation of dangerous scenarios
- Explicit planning capabilities rather than purely reactive control
- Transfer learning potential through learned environment dynamics
The challenges are real: compounding errors, computational costs, integration complexity. But the trajectory is clear. As AI moves from digital environments into the physical world, world models shift from research curiosity to essential infrastructure.
The next breakthrough might not come from a larger language model. It might come from an agent that dreams.
References
Footnotes
-
OpenAI (2024). "Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation" ↩
-
Google DeepMind (2024). "Genie: Generative Interactive Environments" ↩
-
Yann LeCun, interview (2024). "We're never going to get to human-level A.I. by just training on text" ↩
-
"World models aim to capture the dynamics of the environment, enabling agents to predict and plan for future states" - Dyn-O: Building Structured World Models ↩
-
"You are bound by real-time physics and cannot speed up time" - Survey on Autonomous Driving World Models ↩
-
"A generative spatio-temporal neural system that compresses multi-sensor physical observations into a compact latent state and rolls it forward under hypothetical actions, letting the vehicle rehearse futures before they occur" - Autonomous Driving Survey 2025 ↩
-
Hafner et al. (2023). "Mastering Diverse Domains through World Models" ↩
-
"Dreamer learns a model of the environment and improves its behavior by imagining future scenarios" and "outperforms tuned expert algorithms across a wide range of benchmarks and data budgets" - DreamerV3 paper ↩
-
"Safely streamline and scale training" - World Models for Safe Planning ↩
-
"Require a large number of environment interactions to learn successful control policies, often millions or even billions" - FIOC-WM paper ↩
-
"Bound by real-time physics and cannot speed up time" - Autonomous Driving Survey ↩
-
"5000% more data efficient" - PlaNet paper comparison ↩
-
"PlaNet uses substantially fewer episodes and reaches final performance close to and sometimes higher than strong model-free algorithms" - PlaNet paper ↩
-
"200× less environment interaction and similar computation time" - PlaNet paper ↩
-
"Recent breakthroughs in autonomous driving have been propelled by advances in robust world modeling, fundamentally transforming how vehicles interpret dynamic scenes and execute safe decision-making" - Autonomous Driving Survey 2025 ↩
-
"A generative spatio-temporal neural system that compresses multi-sensor physical observations into a compact latent state and rolls it forward under hypothetical actions, letting the vehicle rehearse futures before they occur" - Autonomous Driving Survey 2025 ↩
-
Ha & Schmidhuber (2018). "World Models" ↩
-
VAE compression ratios from World Models paper ↩
-
"Separation of concerns" concept from V-M-C architecture analysis ↩
-
RNN limitations in world models from VPTR paper ↩
-
Hafner et al. (2019). "Learning Latent Dynamics for Planning from Pixels" ↩
-
"Planning with learned models" - PlaNet paper ↩
-
"Early neural world models, such as PlaNet (Hafner et al., 2019) and the Dreamer series (Hafner et al., 2020; 2021; 2025), showed that latent dynamics can replace explicit simulators" - FIOC-WM paper ↩
-
Dreamer learning mechanism - Hafner et al. (2020) ↩
-
"The algorithm consists of three neural networks: the world model predicts the outcomes of potential actions, the critic judges the value of each outcome, and the actor chooses actions to reach the most valuable outcomes" - DreamerV3 paper ↩
-
"DreamerV3, a general algorithm that outperforms specialized methods across over 150 diverse tasks, with a single configuration" - DreamerV3 abstract ↩
-
"Applied out of the box, Dreamer is the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula" - DreamerV3 paper ↩
-
"This achievement has been posed as a significant challenge in artificial intelligence that requires exploring far-sighted strategies from pixels and sparse rewards in an open world" - DreamerV3 paper ↩
-
"Due to these obstacles, previous approaches resorted to using human expert data and domain-specific curricula" - DreamerV3 paper ↩
-
MineRL Diamond Competitions 2019-2021 reference ↩
-
"We observe robust learning not only across over 150 tasks from the domains summarized in Figure 2, but also across model sizes and training budgets" - DreamerV3 paper ↩
-
"World models have emerged as a linchpin technology, offering high-fidelity representations of the driving environment that integrate multi-sensor data, semantic cues, and temporal dynamics" - Autonomous Driving Survey 2025 ↩
-
"Current statistics underscore that human error remains the principal cause of accidents" - Autonomous Driving Survey 2025 ↩
-
Survey on Autonomous Driving World Models (2025) ↩
-
"Understanding the world in terms of objects and the possible interplays with them is an important cognition ability" - Dyn-O paper ↩
-
"World models that indistinctly reconstruct all information in the environment can suffer from several failure modes. For instance, in visual tasks, they can ignore small, but important features for predicting the future, such as little objects" - Object-centric world models research ↩
-
"Object-centric world models (OCWM) aim to decompose visual scenes into object-level representations, providing structured abstractions that could improve compositional generalization and data efficiency in reinforcement learning" - FIOC-WM paper ↩
-
"FOCUS can be deployed on robotics manipulation tasks to explore object interactions more easily" with "a Franka Emika robot arm" in "real-world settings" - FOCUS paper ↩
-
Dyn-O: Building Structured World Models with Object-Centric Representations ↩
-
"We identify representation shift during multi-object interactions as a key driver of unstable policy learning" and "when used for downstream model-based control, policies trained on [object-centric] latents underperform compared to DreamerV3" - FIOC-WM paper ↩
-
"On February 15th, 2024, OpenAI introduced a new vision foundation model that can generate video from users' text prompts. The model named Sora" - Sora Survey paper ↩
-
"OpenAI claimed that Sora, due to being trained on a large-scale dataset of text-video pairs, has impressive near-real-world generation capability" - Sora Survey paper ↩
-
"A generative artificial intelligence (AI) model that understands real-world mechanisms is often referred to as a world model" - Sora Survey paper ↩
-
"Scalability refers to how much data is fed as input and whether the model shows a sign of emergent capability not observed in ordinary generation models" - Sora Survey paper ↩
-
"Generalizability refers to the ability of such a model to generate output beyond the training data distribution" - Sora Survey paper ↩
-
"Visual realism does not imply physical understanding" - Do Video Models Understand Physics paper ↩
-
"Acquiring certain physical principles from observation alone may be possible, but significant challenges remain" - Physics understanding research ↩
-
Google DeepMind. "Genie: Generative Interactive Environments" ↩
-
"Was trained in an unsupervised manner on a massive dataset of unlabeled Internet videos (specifically, 2D platformer games)" - Genie paper ↩
-
"Genie can take a single prompt image (a photo, a synthetic image, or even a hand-drawn sketch) and generate an endless variety of playable (action-controllable) worlds" - Genie paper ↩
-
"Small errors may compound over time, leading to poor long-horizon prediction" - World models challenges ↩
-
"A tiny, 1% prediction error at the first step can be amplified, causing the dream to diverge from reality until, after many steps, it becomes a completely fabricated response" - Compounding error analysis ↩
-
"The estimated training cost for GPT-4 was 191 million" - Training cost analysis ↩
-
"MLLMs enable contextual task reasoning but overlook physical constraints, while WMs excel at physics-aware simulation but lack high-level semantics" - Integration challenges ↩
-
"Consensus among AI's foremost researchers, including Yann LeCun, Demis Hassabis, and Yoshua Bengio, is that world models are essential for building AI systems that are truly smart, scientific and safe" - AI research consensus ↩
-
"Your house cat has a more robust and useful world model than ChatGPT" - Embodied intelligence comparison ↩
-
"A true AGI will require physical understanding, reasoning abilities, and adaptability" - AGI requirements ↩