Project Silicon: What If We Could Do Gradient Descent on Assembly Code?
AlphaDev made headlines in 2023 by discovering sorting algorithms faster than any human had written in 50 years. It accomplished this by treating assembly generation as a game and using reinforcement learning to play it. But here's the thing: AlphaDev was fundamentally guessing. Every candidate instruction required billions of Monte Carlo simulations to estimate whether it was good or bad. The CPU remained a black box.
What if we could open that box? What if, instead of guessing and checking, we could compute exactly how much better one instruction sequence is than another, and follow the gradient directly to better code?
That's the premise of Project Silicon: build a neural network that simulates CPU execution so accurately that we can backpropagate through it. Turn the discrete problem of code generation into a continuous optimization problem. Do gradient descent on algorithms.
The Problem with Discrete Search
To understand why this matters, consider how AlphaDev actually works. It frames assembly optimization as a single-player game where the agent selects instructions one at a time, observing the CPU state after each choice. A deep neural network learns a policy (which instruction to try next) and a value function (how promising is this partial program). Monte Carlo Tree Search explores the space of possible programs, guided by these networks.1
This approach produced remarkable results. "Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi as well as Go."2 AlphaDev adapted this framework to assembly, treating instruction selection like choosing chess moves.
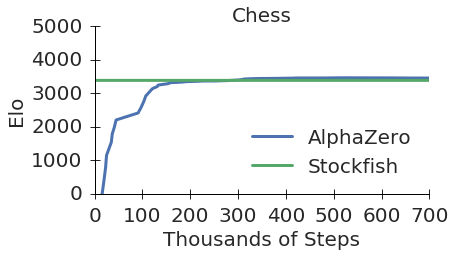 Figure 1: AlphaZero achieves superhuman chess performance through self-play, demonstrating the power of MCTS combined with neural networks. The same approach powers AlphaDev's assembly optimization. Source: Silver et al., Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, 2017
Figure 1: AlphaZero achieves superhuman chess performance through self-play, demonstrating the power of MCTS combined with neural networks. The same approach powers AlphaDev's assembly optimization. Source: Silver et al., Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, 2017
But there's a fundamental limitation. When AlphaDev considers instruction ADD EAX, 10, the immediate value 10 is a discrete choice from a predefined list. The agent cannot know that 11 might be better without explicitly sampling it. Each constant, each register choice, each memory offset must be tried individually. The search space explodes combinatorially.
"AlphaZero searches just 80 thousand positions per second in chess compared to 70 million for Stockfish."3 That 875x speed disadvantage is acceptable in chess because the neural network's position evaluation is so much more accurate than Stockfish's hand-tuned heuristics. But in assembly optimization, where the search space is vastly larger and the evaluation function (actual CPU latency) is expensive to compute, this discrete sampling becomes prohibitive.
From Neural Turing Machines to Differentiable CPUs
The idea of differentiable computation is not new. In 2014, Graves, Wayne, and Danihelka demonstrated that you could augment neural networks with external memory accessed through differentiable read and write operations.4 Instead of a hard address lookup, Neural Turing Machines (NTMs) use soft attention: the network produces a probability distribution over memory locations, and the read operation returns a weighted sum of all values.
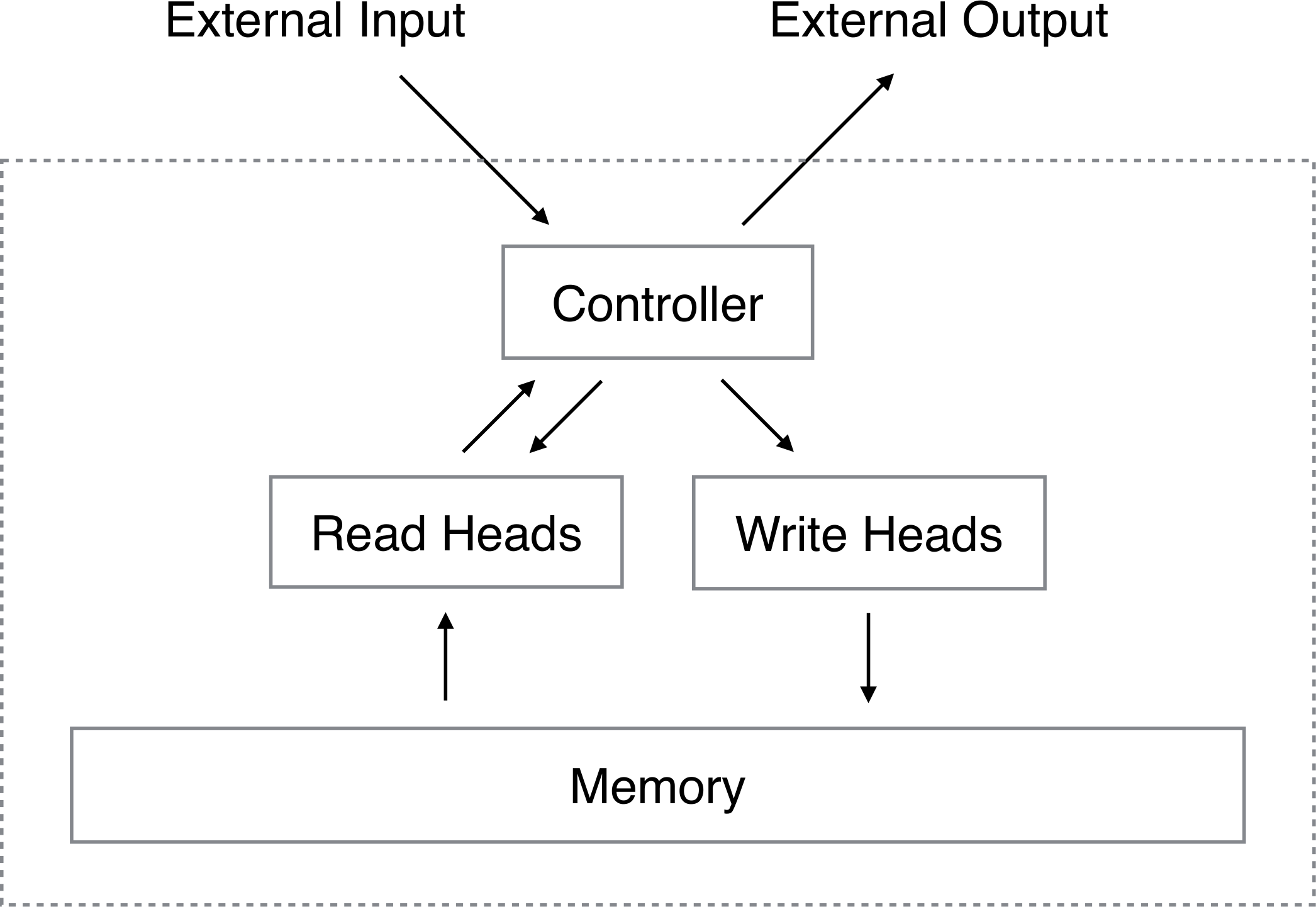 Figure 2: Neural Turing Machine architecture with differentiable read/write heads. The controller interacts with external memory through soft attention mechanisms, enabling gradient-based training on algorithmic tasks. Source: Graves et al., Neural Turing Machines, 2014
Figure 2: Neural Turing Machine architecture with differentiable read/write heads. The controller interacts with external memory through soft attention mechanisms, enabling gradient-based training on algorithmic tasks. Source: Graves et al., Neural Turing Machines, 2014
This approach enables gradient flow through what would otherwise be discrete memory operations. The NTM paper demonstrated something remarkable: "Preliminary results demonstrate that Neural Turing Machines can infer simple algorithms such as copying, sorting, and associative recall from input and output examples."5
"The combined system is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent."6
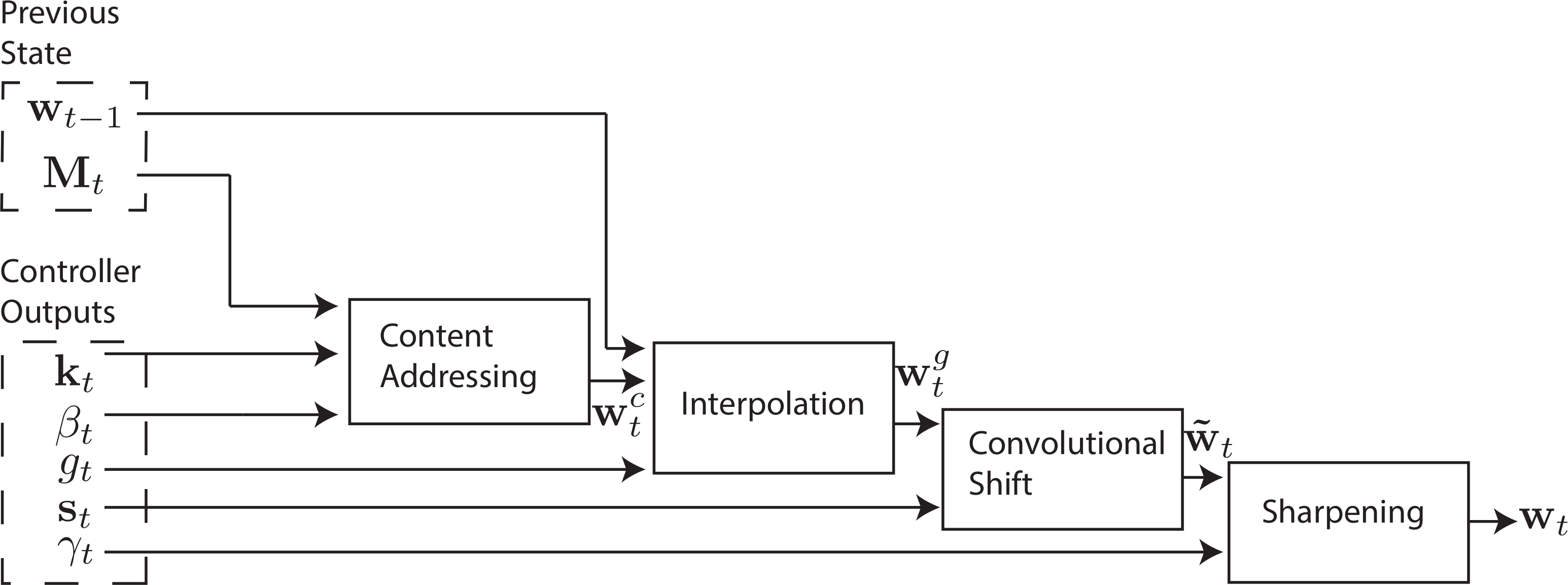 Figure 3: Differentiable addressing mechanism showing Content Addressing, Interpolation, Convolutional Shift, and Sharpening. This flowchart demonstrates how soft attention enables gradient flow through memory operations. Source: Graves et al., Neural Turing Machines, 2014
Figure 3: Differentiable addressing mechanism showing Content Addressing, Interpolation, Convolutional Shift, and Sharpening. This flowchart demonstrates how soft attention enables gradient flow through memory operations. Source: Graves et al., Neural Turing Machines, 2014
The addressing mechanism combines content-based and location-based approaches: "Two addressing mechanisms are combined to facilitate both content-based and location-based addressing: content-based addressing focuses attention on locations based on the similarity between their current values and values emitted by the controller."7
If neural networks can learn to implement sorting through differentiable memory operations, what's stopping us from scaling this idea to simulate an entire CPU?
The SiliconTransformer Architecture
Project Silicon proposes a different approach: "construct a Differentiable CPU, a neural network architecture that internalizes the deterministic logic of a processor (registers, flags, arithmetic units, and memory) into a continuous, differentiable latent space."8
The core idea is straightforward. If we train a neural network to predict CPU state transitions with sufficient accuracy, we get two things for free:
- Fast simulation: The network can evaluate thousands of candidate instruction sequences in parallel on a GPU, much faster than actual execution.
- Gradients: Because the simulation is differentiable, we can compute how the output changes with respect to the input. We can ask "which direction should I change this constant to get closer to my target output?" and get an exact answer.
The proposed architecture, called SiliconTransformer, is "a large-scale neural network designed to approximate the state transition function of an x86-64 processor."9 The specification is substantial: "Parameters: ~7 Billion. Layers: 32-48. Heads: 32. Context Window: 8,192 tokens."10
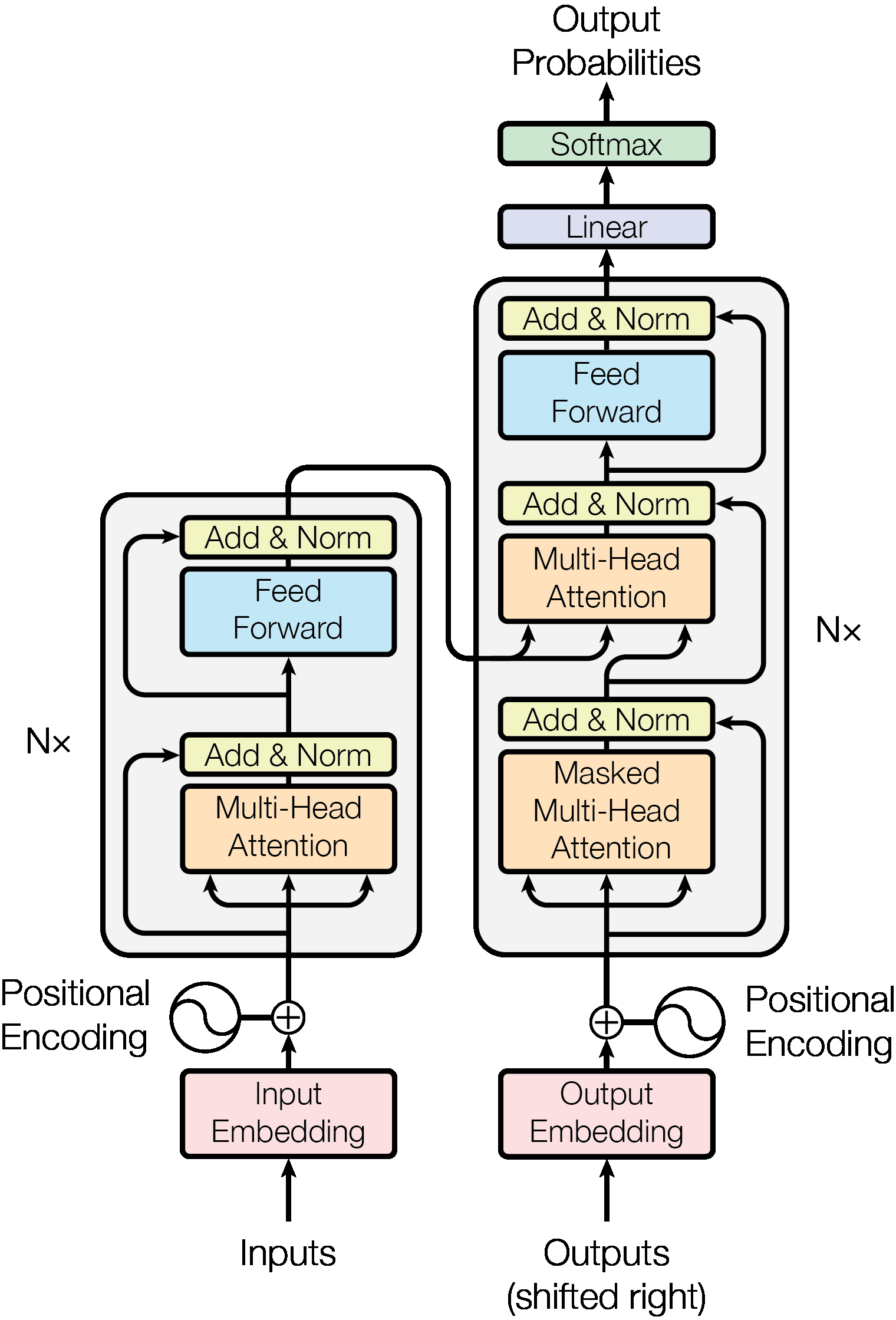 Figure 4: Transformer architecture showing encoder-decoder structure with multi-head attention. This architecture has become the backbone of modern neural approaches to code understanding and generation. Source: Vaswani et al., Attention Is All You Need, 2017
Figure 4: Transformer architecture showing encoder-decoder structure with multi-head attention. This architecture has become the backbone of modern neural approaches to code understanding and generation. Source: Vaswani et al., Attention Is All You Need, 2017
Why a Transformer? Because "the Transformer model relies entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution."11 This matters critically for differentiable CPUs. RNNs suffer from vanishing gradients over long sequences. A 100-instruction program would require gradients to flow through 100 sequential hidden state updates. Transformers, by contrast, can attend directly to any position in the sequence, enabling gradient flow even between distant instructions.
The Numerical Challenge
One tricky aspect: how do you represent arbitrary 64-bit integers to a neural network? Standard tokenization fragments numbers into meaningless pieces. The constant 0xDEADBEEF becomes several unrelated tokens, losing the fact that it's a single numerical value.
The solution comes from work on continuous number encoding. "xVal, a continuous number encoding scheme, offers a vital solution for handling immediate values. Instead of tokenizing the number 1024 as multiple sub-word tokens, xVal scales a single learnable token embedding by the numerical value itself."12
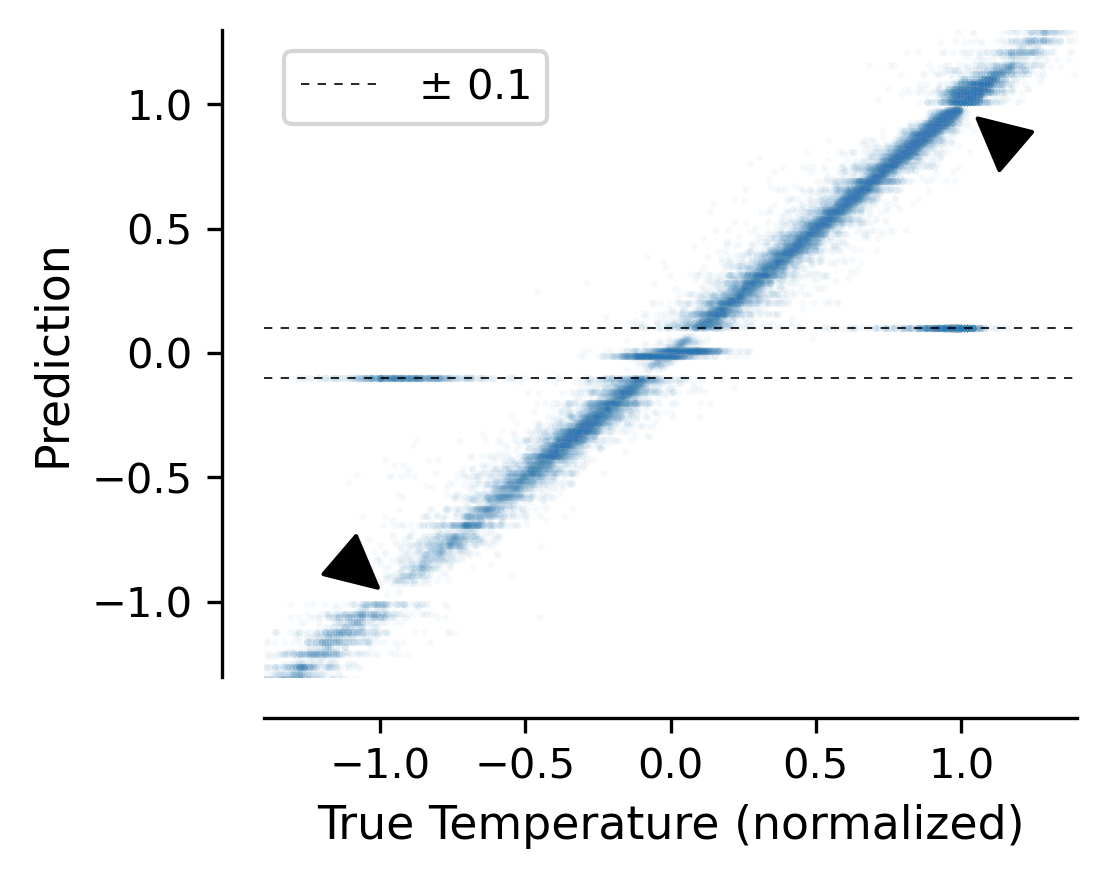 Figure 5: xVal continuous encoding enables accurate numerical predictions by representing numbers as scaled vectors rather than discrete tokens. Source: Golkar et al., xVal: A Continuous Number Encoding for Large Language Models, 2023
Figure 5: xVal continuous encoding enables accurate numerical predictions by representing numbers as scaled vectors rather than discrete tokens. Source: Golkar et al., xVal: A Continuous Number Encoding for Large Language Models, 2023
This representation makes constants differentiable. The model can output a gradient indicating that a constant should be "slightly larger" or "slightly smaller," enabling optimization of magic numbers and offsets that a discrete search would have to stumble upon.
Multi-Task Output Heads
The SiliconTransformer doesn't predict a single value. It uses specialized heads for different aspects of CPU state:
- Register State Head: Predicts 64-bit values of modified registers using "a specialized loss function combining MSE for magnitude accuracy with Bitwise Cross-Entropy for bit-pattern fidelity."13
- Flag Prediction Head: Classifies the binary state of EFLAGS (Zero, Carry, Overflow, Sign). A single bit error in predicting the Zero Flag can completely change control flow.
- Latency Prediction Head: Scalar regression predicting cycle count, enabling optimization for actual performance, not just correctness.
- Branch Prediction Head: For conditional jumps, predicts P(Taken), creating a differentiable branch predictor.
Training Data: The Unicorn Engine
Where do you get 100 billion examples of CPU state transitions?
You generate them. The Unicorn CPU emulator provides a framework for executing arbitrary x86-64 code in a sandboxed environment, with hooks to capture the state before and after each instruction. By running a stochastic fuzzer that generates random valid basic blocks, you can observe the consequences of purely random instruction sequences.
This matters because human-written code is biased. Compilers produce idiomatic patterns. To learn the full dynamics of the CPU, including rare corner cases and unusual instruction combinations, the model needs high-entropy, random interactions.
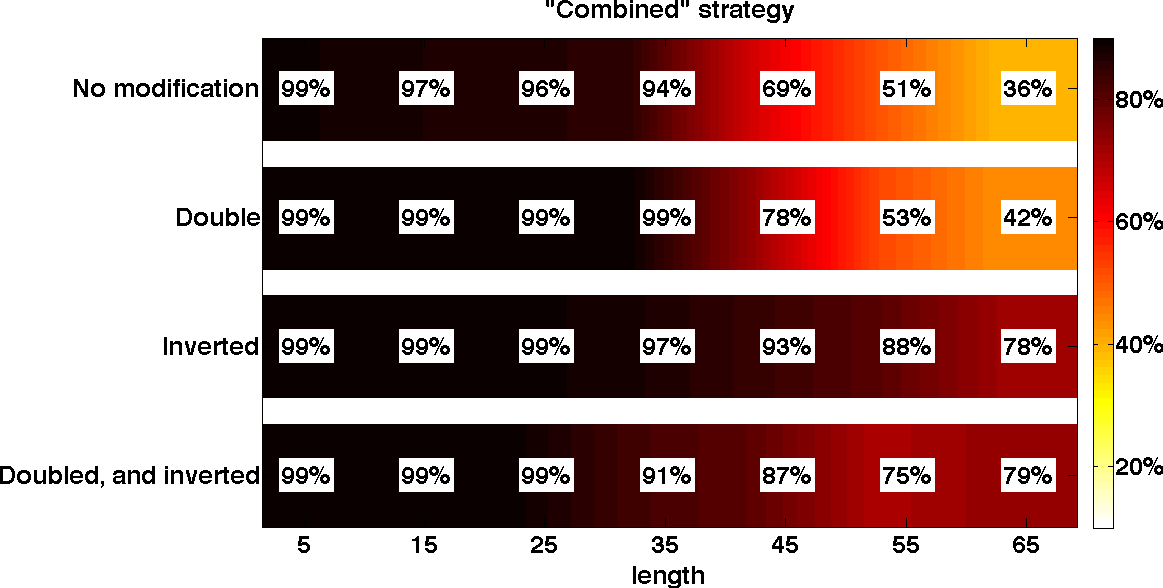 Figure 6: Training results for neural network learning to execute simple programs. Even early LSTM models achieved high accuracy on program execution tasks with the right curriculum. Source: Zaremba & Sutskever, Learning to Execute, 2015
Figure 6: Training results for neural network learning to execute simple programs. Even early LSTM models achieved high accuracy on program execution tasks with the right curriculum. Source: Zaremba & Sutskever, Learning to Execute, 2015
Early work on "Learning to Execute" demonstrated this approach could work at small scale: "making it possible to train an LSTM to add two 9-digit numbers with 99% accuracy."14 Project Silicon scales this to full x86-64 execution.
To seed realistic training data rather than purely random noise, the fuzzer draws from "execution traces from real-world binaries (SPEC CPU 2017, Linux Kernel)."15 This ensures the model sees realistic instruction patterns and memory access patterns, not just random register shuffling.
The Search Algorithm: MCTS Meets Gradient Descent
A trained SiliconTransformer is just a simulator. To actually discover algorithms, you need a search procedure. Project Silicon uses "Monte Carlo Tree Search (MCTS), specifically a variant inspired by MuZero, which is designed to search using a learned dynamics model rather than a perfect simulator."16
But here is where differentiability changes everything.
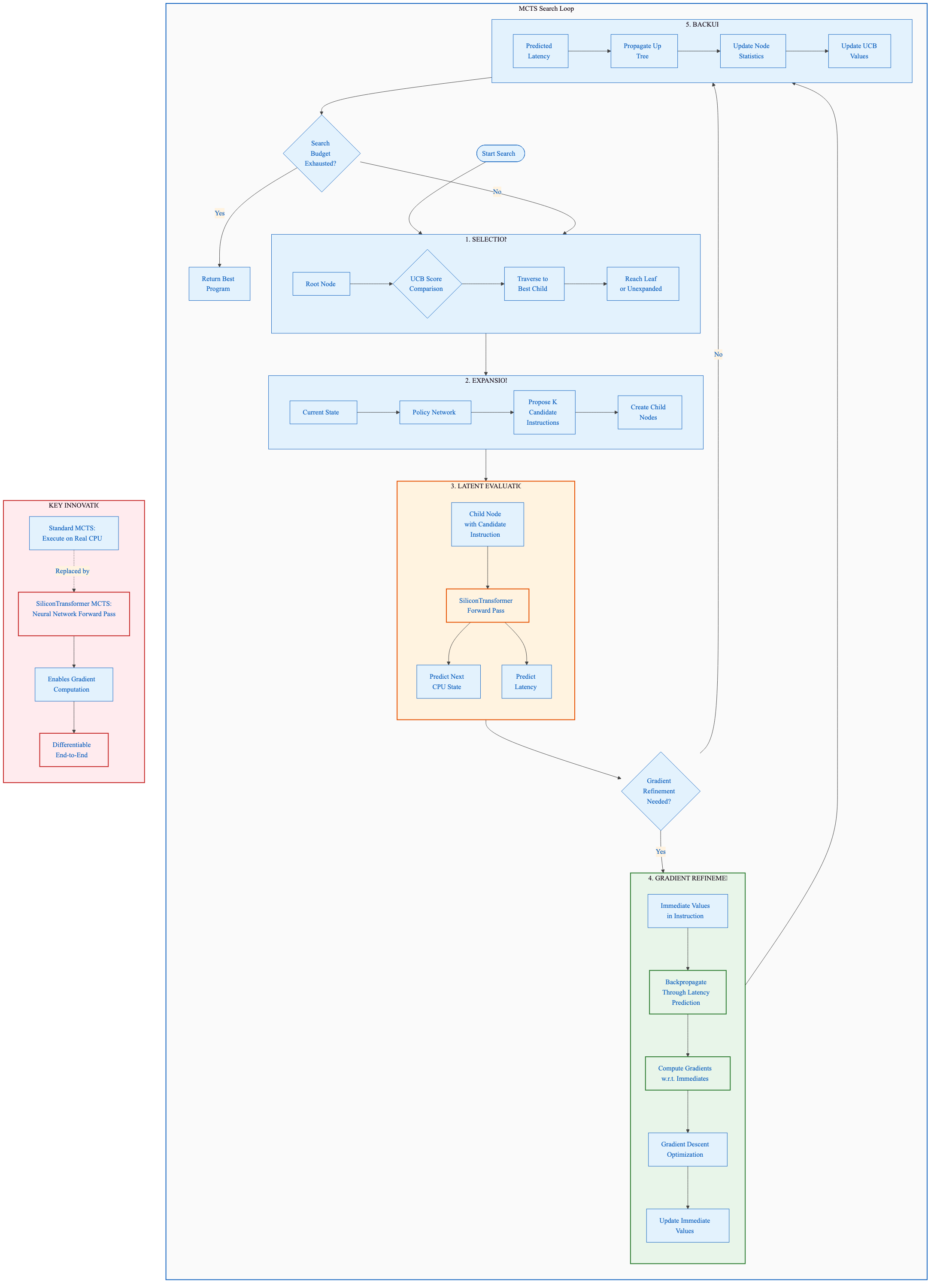 Figure 7: MCTS search with SiliconTransformer. Unlike standard MCTS which requires executing programs on a real CPU, the SiliconTransformer enables latent evaluation through neural network forward passes, allowing gradient refinement of immediate values before committing to the search tree. Source: Project Silicon proposal.
Figure 7: MCTS search with SiliconTransformer. Unlike standard MCTS which requires executing programs on a real CPU, the SiliconTransformer enables latent evaluation through neural network forward passes, allowing gradient refinement of immediate values before committing to the search tree. Source: Project Silicon proposal.
The SiliconTransformer predicts the next state and latency in a single forward pass. Because GPUs can process batches efficiently, you can evaluate thousands of candidate futures simultaneously. This is much faster than sequential emulation.
But the real advantage is gradients. When standard MCTS proposes ADD EAX, <IMM>, it must choose a specific immediate value from a discrete set. Project Silicon can instead:
- Initialize
<IMM>with a random value z - Forward pass through SiliconTransformer to get predicted state
- Compute loss: distance between predicted state and target state
- Compute gradient of loss with respect to z
- Update z via gradient descent
"This process effectively allows the system to invent constants. It can fine-tune magic numbers, loop counters, and memory offsets via gradient descent within the search tree."17
This is the key insight. Previous approaches treated instruction selection and constant selection as equally discrete decisions. Project Silicon separates them: MCTS handles the discrete choice of which instruction to use, while gradient descent handles the continuous choice of what operands to provide.
How RL Code Generation Currently Works
To appreciate what Project Silicon offers, consider the current state of RL-based code generation.
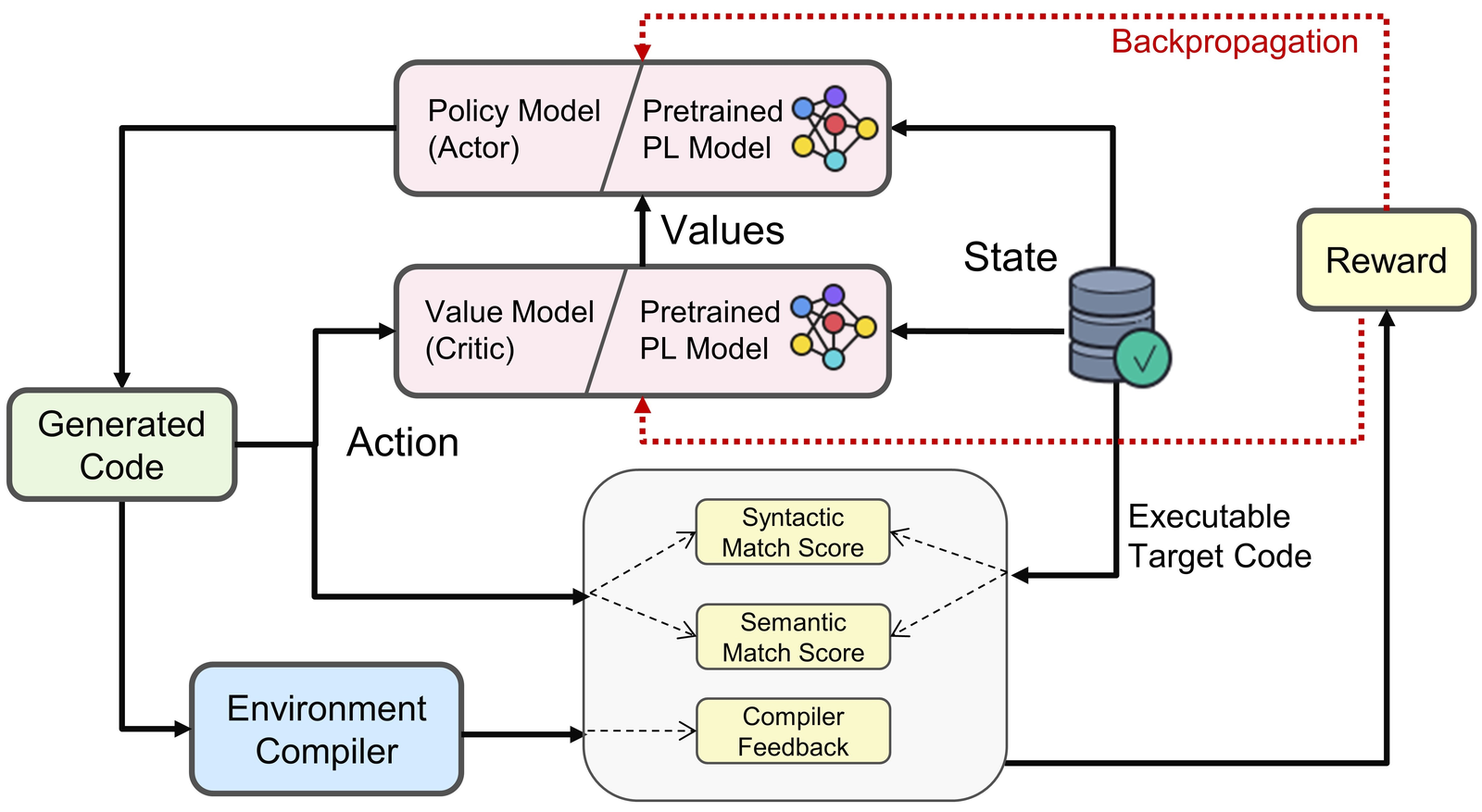 Figure 8: PPOCoder architecture using reinforcement learning for code generation. The Policy Model generates code, while the Value Model estimates expected reward. Crucially, feedback comes from actually compiling and running the code. Source: Shojaee et al., PPOCoder: Execution-based Code Generation using Deep Reinforcement Learning, 2023
Figure 8: PPOCoder architecture using reinforcement learning for code generation. The Policy Model generates code, while the Value Model estimates expected reward. Crucially, feedback comes from actually compiling and running the code. Source: Shojaee et al., PPOCoder: Execution-based Code Generation using Deep Reinforcement Learning, 2023
Systems like PPOCoder "refine CodeRL by employing the PPO algorithm for code generation"18 and "use unit test feedback as reward signals to guide the code generation process."19 This works, but requires actually compiling and executing generated code for every reward computation.
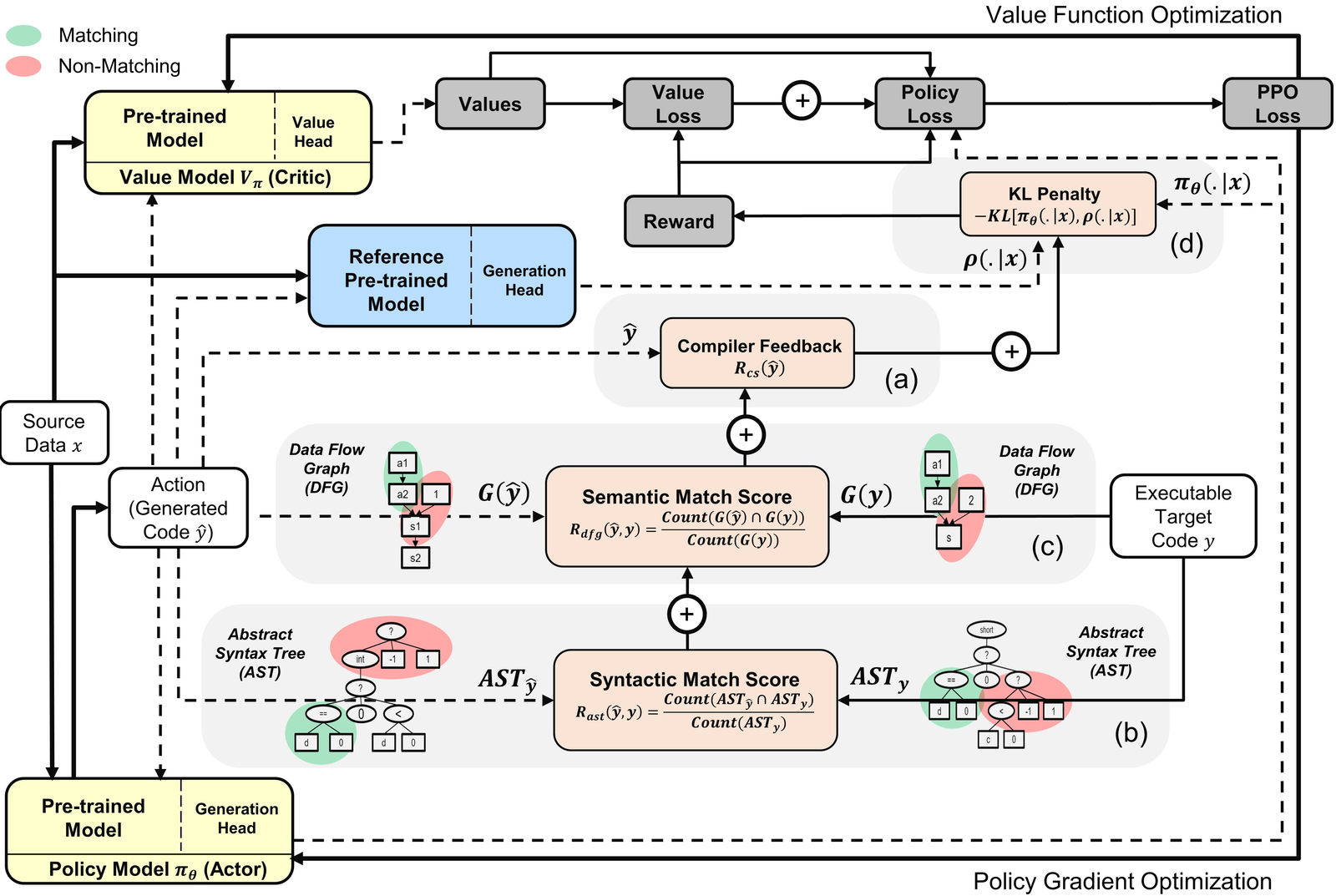 Figure 9: Detailed PPOCoder training loop with compiler feedback and semantic matching. The tight integration between neural policy and execution environment enables learning from sparse reward signals. Source: Shojaee et al., PPOCoder: Execution-based Code Generation using Deep Reinforcement Learning, 2023
Figure 9: Detailed PPOCoder training loop with compiler feedback and semantic matching. The tight integration between neural policy and execution environment enables learning from sparse reward signals. Source: Shojaee et al., PPOCoder: Execution-based Code Generation using Deep Reinforcement Learning, 2023
The execution bottleneck limits how many candidates can be evaluated. Beyond this, execution feedback is binary (pass/fail) or coarse (test cases passed). There's no gradient signal indicating why a program failed or how to fix it.
A differentiable CPU changes this calculus. Instead of "this program failed test case 7," you get "if you increased the loop counter by 3, the output array would be 0.2 closer to sorted." That's actionable information.
Prior Art in Neural CPU Modeling
Project Silicon builds on substantial prior work in neural performance prediction.
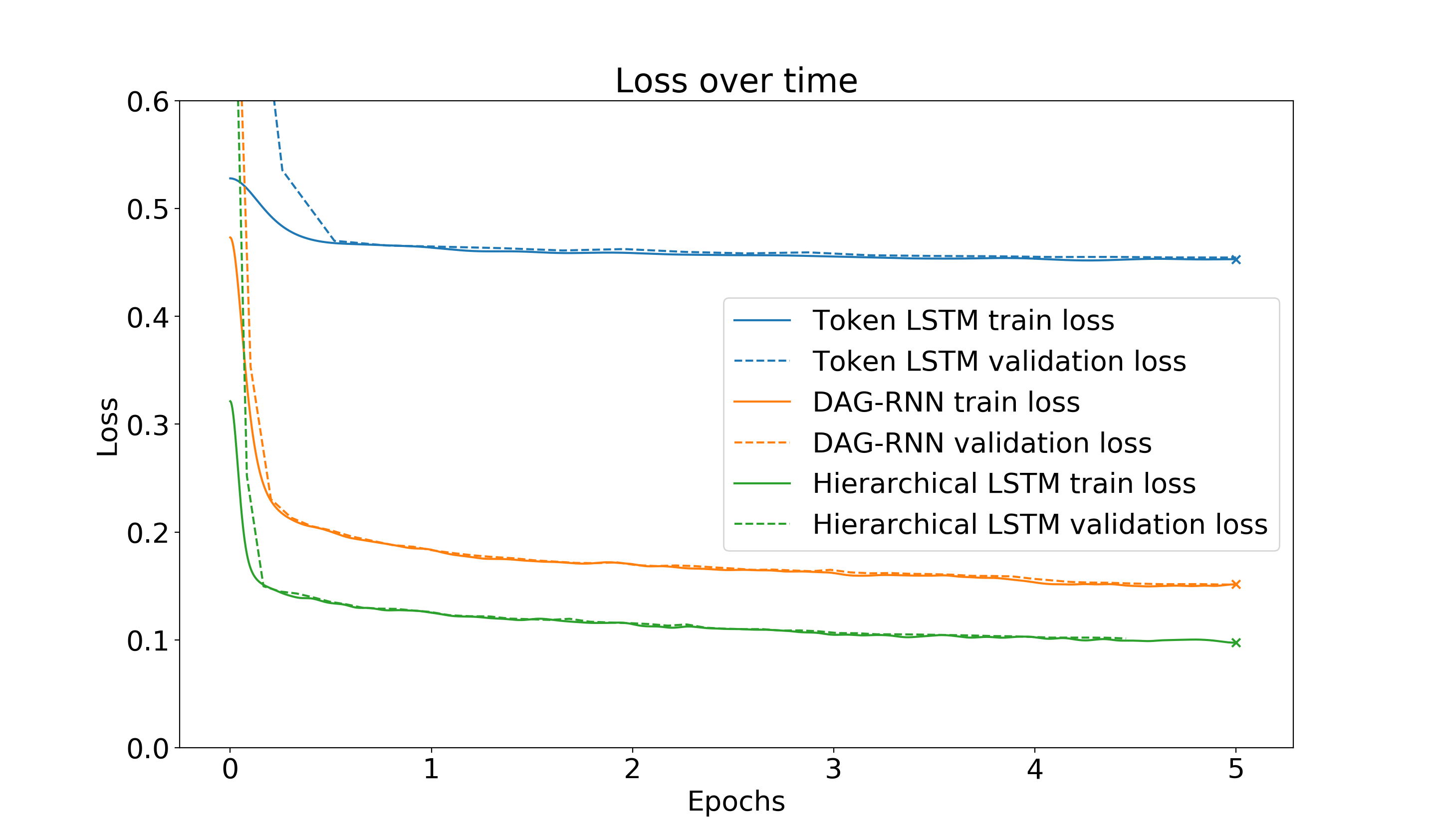 Figure 10: Neural network training for CPU throughput prediction. Different architectures (Token LSTM, DAG-RNN, Hierarchical LSTM) learn to predict execution cycles from instruction sequences. Source: Mendis et al., Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation, 2019
Figure 10: Neural network training for CPU throughput prediction. Different architectures (Token LSTM, DAG-RNN, Hierarchical LSTM) learn to predict execution cycles from instruction sequences. Source: Mendis et al., Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation, 2019
Ithemal demonstrated that "neural networks (LSTMs and Graph Neural Networks, respectively) can predict the throughput (cycles per basic block) of x86 code with higher accuracy than analytical tools like Intel's IACA or LLVM's MCA."20 It "achieves a median error of approximately 10% compared to approximately 20% for llvm-mca on Haswell."21
DiffTune took this further, showing that neural surrogates enable gradient-based optimization. "DiffTune is able to automatically learn the entire set of 11,265 microarchitecture-specific parameters within the Intel x86 simulation model of llvm-mca."22 If neural networks can learn simulator parameters, they can also learn to predict performance in a differentiable way.
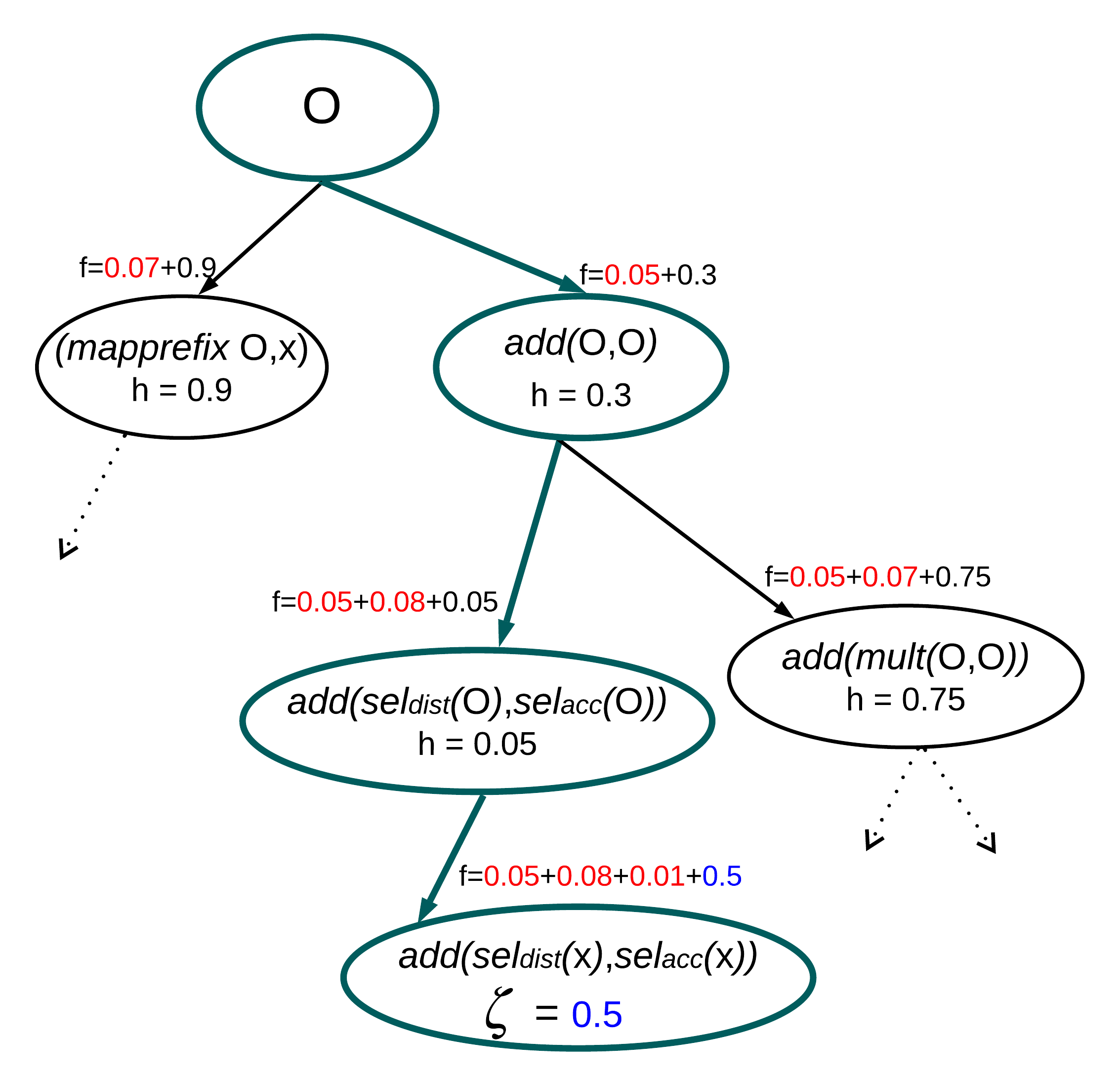 Figure 11: Search tree for differentiable program synthesis with learned heuristics. The f-values guide exploration toward promising program structures. Source: Learning Differentiable Programs with Simulated Annealing, 2023
Figure 11: Search tree for differentiable program synthesis with learned heuristics. The f-values guide exploration toward promising program structures. Source: Learning Differentiable Programs with Simulated Annealing, 2023
The differentiable Forth interpreter demonstrated that "By observing input-output pairs, the continuous parameter vectors of our neural network components are jointly optimized using gradient descent."23 This showed you could train a neural network to discover programs through gradient descent alone, without explicit search.
What Could Go Wrong
Let me be direct about the challenges.
The Butterfly Effect: A single bit error in predicting a flag early in an execution trace can cause control flow to diverge. The entire subsequent trace becomes invalid. This "exposure bias" problem afflicts all autoregressive models, but is especially severe when simulating deterministic computation.
State Space Explosion: x86-64 has 16 general-purpose registers, dozens of flags, and a 64-bit address space. Accurately simulating all possible states is impossible. The model must learn useful abstractions. Even with 8,192 tokens of context, complex algorithms may require longer traces.
Generalization: The model will be trained on randomly generated code and traces from SPEC CPU 2017. Will it generalize to the specific patterns that matter for optimization? Or will it memorize the training distribution and fail on novel instruction combinations?
Latency Prediction: Predicting cycle counts requires modeling cache behavior, branch prediction, and superscalar execution. These depend on microarchitectural details that vary across CPU generations. That 10% error rate compounds over long execution traces.
Verification: Even if the model discovers a program that appears optimal, how do you verify it's actually correct? SMT solvers can prove equivalence for small programs, but scale poorly. Any discovered algorithm must still be verified through traditional methods before deployment.
The Proposed Benchmark Suite
Project Silicon proposes evaluating on a tiered benchmark progression:24
| Tier | Task | Success Metric | Baseline |
|---|---|---|---|
| Tier 1 | Swap, Min, Max | 100% Functional Correctness | std::swap |
| Tier 2 | Popcount, LeadingZeros | Latency < Compiler -O3 | __builtin_popcount |
| Tier 3 | Sort3, Sort4, Sort5 | Match/Beat AlphaDev | libc++ sort |
| Tier 4 | ChaCha20 Block | Latency Reduction vs OpenSSL | OpenSSL ASM |
| Tier 5 | 4x4 Matrix Multiply | Match BLAS/Eigen | BLAS/Eigen |
Tier 3 is the direct comparison to AlphaDev. If Project Silicon can match or exceed AlphaDev's sorting networks while using orders of magnitude fewer samples (thanks to gradient information), that validates the approach.
Tier 4 and 5 push into territory where human-written assembly has been extensively optimized. Finding improvements there would be genuinely significant.
What This Means for the Future
If Project Silicon works, the implications extend beyond superoptimization.
End-to-End Differentiability: A differentiable CPU means any software function can be treated as a neural network layer. You could backpropagate through the entire software stack, from high-level loss functions down to individual assembly instructions.
Compiler Backend Replacement: Rather than hand-tuning optimization passes, train a neural model to emit optimal code directly from IR. The thousands of heuristics in LLVM become learnable parameters.
Hardware-Software Co-design: If both the CPU model and the code optimizer are differentiable, you could jointly optimize instruction set extensions and the code that uses them. Want to know if adding a new SIMD instruction would help? Differentiate through the simulator.
Automatic Vulnerability Discovery: Security vulnerabilities often arise from subtle interactions between instructions. A differentiable CPU could find inputs that cause unintended state transitions, using gradient guidance instead of blind fuzzing.
This represents what some call "Software 2.0": "a paradigm where code is not written by humans but searched for and optimized by neural networks."25
Honest Assessment
Project Silicon is ambitious. Training a 7B-parameter model to accurately simulate x86-64 execution is a significant undertaking. The approach may hit fundamental limits around state space complexity or generalization.
But the component technologies exist. Neural networks can predict CPU behavior. Transformers can track complex state. Differentiable programming works for simpler languages. MCTS with learned world models has achieved superhuman performance in multiple domains.
The question is whether these pieces can be assembled into something that outperforms discrete search on real assembly optimization tasks. That's an empirical question, and Project Silicon lays out a concrete path to answer it.
Whether it succeeds or not, the attempt is valuable. Understanding where differentiable computation breaks down for deterministic systems tells us something fundamental about the limits of gradient-based learning. And if it works, we will have transformed one of computing's oldest problems into the standard toolkit of modern machine learning: loss functions, gradients, and SGD.
AlphaDev proved machines can invent better algorithms. Project Silicon proposes they can do it with gradients.
References
Footnotes
-
Silver, D., et al. "Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm." arXiv:1712.01815, 2017. https://arxiv.org/abs/1712.01815 ↩
-
Silver, D., et al. AlphaZero paper, demonstrating 24-hour superhuman achievement across multiple games. ↩
-
Silver, D., et al. "AlphaZero searches just 80 thousand positions per second in chess compared to 70 million for Stockfish." ↩
-
Graves, A., Wayne, G., & Danihelka, I. "Neural Turing Machines." arXiv:1410.5401, 2014. https://arxiv.org/abs/1410.5401 ↩
-
Graves, A., et al. NTM demonstrating learned algorithms for copying, sorting, and associative recall. ↩
-
Graves, A., et al. "Neural Turing Machines," core differentiability claim. ↩
-
Graves, A., et al. NTM addressing mechanisms description. ↩
-
Project Silicon proposal, defining the Differentiable CPU concept. ↩
-
Project Silicon proposal, SiliconTransformer definition. ↩
-
Project Silicon proposed architecture specifications. ↩
-
Vaswani, A., et al. "Attention Is All You Need." NeurIPS 2017. https://arxiv.org/abs/1706.03762 ↩
-
Golkar, S., et al. "xVal: A Continuous Number Encoding for Large Language Models." arXiv:2310.02989, 2023. https://arxiv.org/abs/2310.02989 ↩
-
Project Silicon proposal, output head design. ↩
-
Zaremba, W., Sutskever, I. "Learning to Execute." arXiv:1410.4615, 2015. https://arxiv.org/abs/1410.4615 ↩
-
Project Silicon proposal, seeded fuzzing approach. ↩
-
Project Silicon proposal, MCTS methodology. ↩
-
Project Silicon proposal on gradient descent for constant optimization. ↩
-
Shojaee, P., et al. "PPOCoder: Execution-based Code Generation using Deep Reinforcement Learning." arXiv:2305.02766, 2023. https://arxiv.org/abs/2305.02766 ↩
-
PPOCoder using unit test feedback as reward signals. ↩
-
Project Silicon research, neural performance prediction capabilities. ↩
-
Mendis, C., et al. "Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation." ICML 2019. https://arxiv.org/abs/1808.07412 ↩
-
Renda, A., et al. "DiffTune: Optimizing CPU Simulator Parameters with Learned Differentiable Surrogates." IEEE MICRO 2020. https://arxiv.org/abs/2010.04017 ↩
-
Riedel, S., et al. "Programming with a Differentiable Forth Interpreter." ICML 2017. ↩
-
Project Silicon proposal, tiered benchmark progression methodology. ↩
-
Project Silicon proposal on Software 2.0 vision. ↩