Most 'AI Agents' Aren't Actually Agents: A Framework for Cutting Through the Hype
Last month, I watched a VP of Engineering get burned by what I call the "demo-to-production gap." His team evaluated an "autonomous AI agent" that flawlessly generated SQL queries, created reports, and even suggested optimizations—all in a 45-minute demo. They signed a six-figure contract. Three months later, the system still can't run unsupervised because it fails unpredictably and can't explain why.
After evaluating dozens of "AI agent" products over the past year, I noticed a consistent pattern: demos succeed at 95%+ rates, but production deployments struggle to hit 60-80% for anything beyond simple tasks. The vendors all claim "full autonomy" and "no human intervention needed," yet every successful deployment I've seen requires extensive human oversight and narrow domain constraints.
The problem isn't that the technology is failing; we're calling the wrong things "agents." Most products marketed as "autonomous AI agents" operate at what I'll call Level 2 (L2) autonomy: sophisticated assistants that execute narrowly scoped tasks. The truly autonomous systems vendors promise (capable of independent problem-solving and self-correction) live at Level 3 (L3) and above. That transition from L2 to L3 represents a fundamental capability gap that most vendors either don't understand or choose to ignore.
This matters because the gap between L2 and L3 isn't just a feature checklist. It's an architectural chasm requiring meta-reasoning capabilities, robust error recovery, and feedback incorporation—capabilities that current LLMs struggle with precisely when you need them most. Understanding where this gap exists will save you from expensive pilots that were never going to reach production.
What We Actually Mean by "Agent"
Before going further, let's clarify what we're talking about. The market uses "AI agent" to describe everything from rule-based chatbots to multi-agent orchestration systems, creating massive confusion.
Traditional chatbots (L0-L1) follow decision trees and keyword matching. They respond to inputs but make no autonomous decisions.
Conversational AI (L1-L2) uses NLP to understand intent and context. These systems can hold natural conversations and make recommendations, but they wait for your approval before taking action.
AI Agents (L2-L4) take autonomous action using tools and APIs. They plan multi-step workflows and execute without constant human approval, but with very different capabilities depending on their autonomy level.
A chatbot talks; an agent acts. But how much autonomy does that action involve?
The 6-Level Framework: Borrowing from Autonomous Vehicles
Agent autonomy becomes clearer when adapted from the automotive industry's SAE J3016 standard: a six-level taxonomy (L0-L5) that defines autonomous vehicle capabilities.
SAE J3016 works because it focuses on responsibility allocation: who's in control at each level, who monitors the system, and who handles failures. These same questions apply directly to data agents.
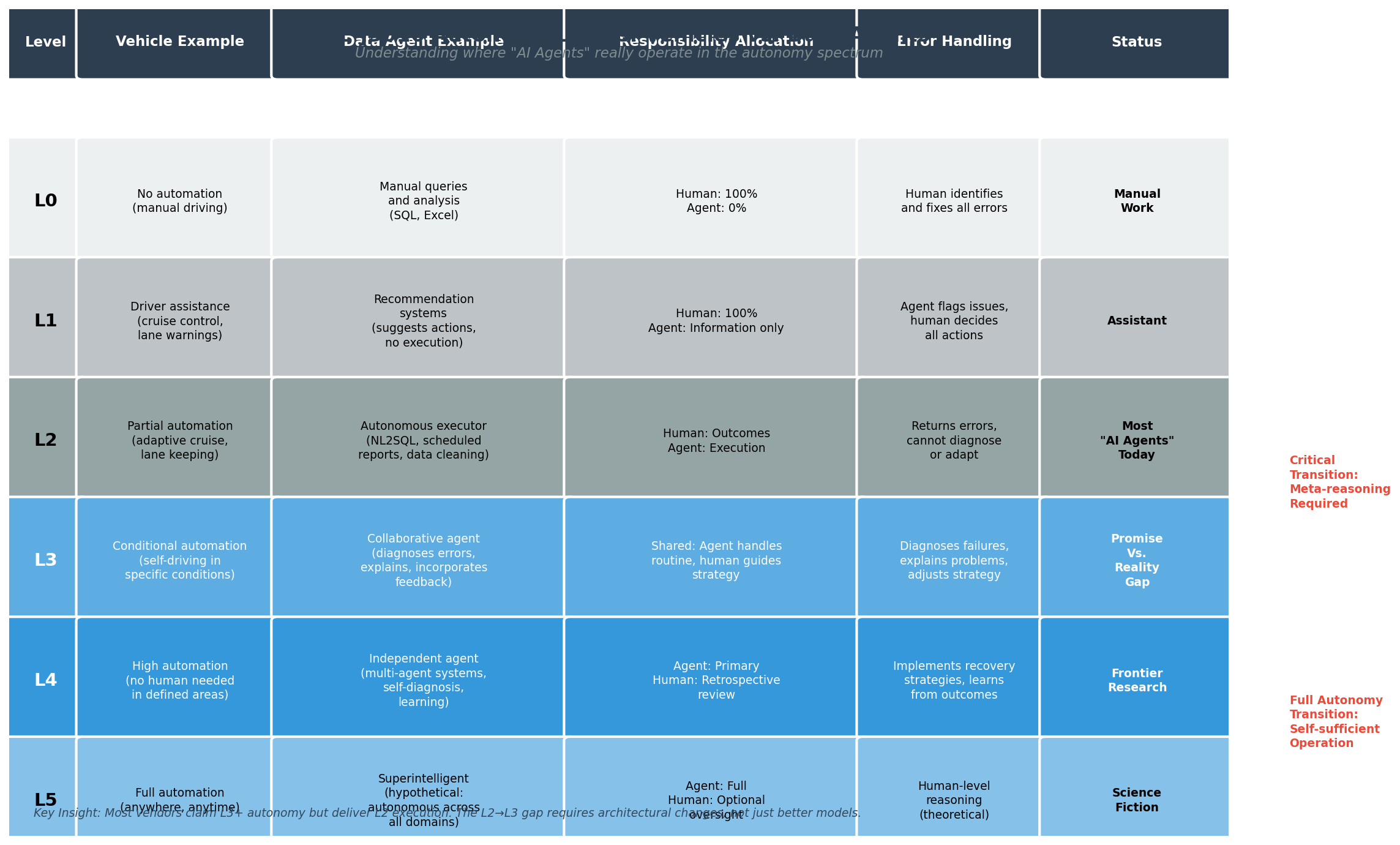 Table 1: SAE J3016 vehicle autonomy levels mapped to data agent autonomy levels, showing responsibility allocation and error handling approaches at each level. The critical L2→L3 transition (highlighted) represents the shift from procedural execution to meta-reasoning.
Table 1: SAE J3016 vehicle autonomy levels mapped to data agent autonomy levels, showing responsibility allocation and error handling approaches at each level. The critical L2→L3 transition (highlighted) represents the shift from procedural execution to meta-reasoning.
Level 0: No Autonomy
Vehicles: No automation. Human does everything. Data Agents: Manual queries and analysis. No AI involvement beyond basic search. Example: Traditional SQL queries, Excel spreadsheets. Responsibility: 100% human
Level 1: Recommender Systems
Vehicles: Driver assistance (cruise control, lane warnings). Human remains fully in control. Data Agents: AI suggests actions but takes none autonomously. User must execute recommendations. Example: "I found three potential data quality issues in this table. Would you like to see them?" Responsibility: 100% human. Agent provides information only.
Level 2: Autonomous Executor
Vehicles: Partial automation (adaptive cruise control, lane keeping). Human must monitor constantly. Data Agents: Executes predefined tasks autonomously within narrow, well-understood domains. No human approval per action, but can't explain failures or adapt strategies. Example: Automated data cleaning for known patterns, scheduled report generation, NL2SQL for routine queries. Responsibility: Human responsible for outcomes. Agent executes but doesn't reason about failures.
This is where most "AI agent" products actually live, despite marketing claims of "full autonomy."
Level 3: Collaborative Agent
Vehicles: Conditional automation. Driver can disengage briefly but must be ready to intervene. Data Agents: Autonomous task execution with collaborative feedback loops. When errors occur, the agent can explain what went wrong, accept corrections, and adjust its strategy. Requires human oversight but handles routine failures independently. Example: Data analysis agent that encounters ambiguous columns, asks clarifying questions, incorporates your answer, and adjusts its approach. Responsibility: Shared. Agent handles routine cases; human handles edge cases and provides strategic guidance.
This is the level most vendors promise but few deliver.
Level 4: Independent Agent
Vehicles: High automation. No human needed in defined conditions. Data Agents: Fully autonomous in specialized domains. Self-diagnoses errors, implements recovery strategies, learns from outcomes. Only escalates genuinely novel situations. Example: Multi-agent data pipeline that monitors quality, detects drift, implements corrections, and explains decisions post-hoc. Responsibility: Primarily agent. Human reviews decisions retrospectively.
Almost no production systems operate here today.
Level 5: Superintelligent
Vehicles: Full automation anywhere, anytime. Data Agents: Hypothetical. Autonomous across all data domains with human-level reasoning. Responsibility: Theoretical. Not achievable with current technology.
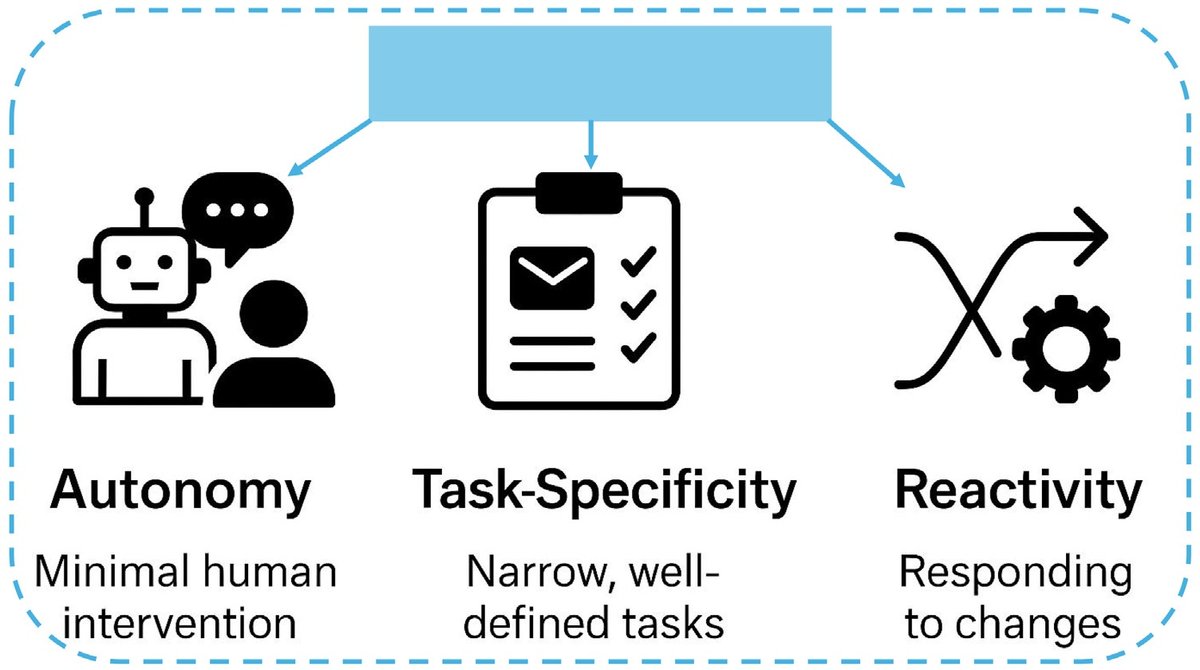 Figure 1: Three key dimensions for understanding agent autonomy: task-specificity, reactivity, and autonomy level. Most "AI agents" cluster in the low-autonomy, high-reactivity quadrant. (Source: AI Agents vs. Agentic AI Taxonomy, arXiv:2505.10468)
Figure 1: Three key dimensions for understanding agent autonomy: task-specificity, reactivity, and autonomy level. Most "AI agents" cluster in the low-autonomy, high-reactivity quadrant. (Source: AI Agents vs. Agentic AI Taxonomy, arXiv:2505.10468)
Why the L2→L3 Gap Matters Most
In autonomous vehicles, L2→L3 marks the critical transition from "driver support systems" to "automated driving systems." At L2, you're still driving; the car just helps. At L3, the car drives, and you're allowed to look away (briefly). That responsibility shift requires fundamentally different engineering.
The same transition defines success in data agents, yet most systems get stuck at L2.
Architecture Differences
L2 agents follow procedural execution:
User request → Plan generation → Tool calls → Result delivery
When something fails, they return an error. They can't diagnose why it failed or what to do about it.
L3 agents require bidirectional communication:
User request → Plan generation → Tool calls → Error? →
Diagnosis → Explain problem → Get feedback → Adjust strategy → Retry
A concrete example showing the difference:
L2 Agent Query:
-- L2 agent attempts to join sales and customers
SELECT s.order_id, c.name, s.total
FROM sales s
JOIN customers c ON s.user_id = c.user_id
WHERE s.order_date > '2025-01-01';
-- Returns: 2.3M rows (expected: ~100K)
-- Error logged: "Unexpected row count"
-- Agent stops. Escalates to human.
L3 Agent Query (with diagnosis):
-- L3 agent detects anomaly, investigates:
SELECT COUNT(*), COUNT(DISTINCT s.order_id)
FROM sales s
JOIN customers c ON s.user_id = c.user_id;
-- Discovers: cartesian product from duplicate user_ids
-- Agent explains: "Join produced 2.3M rows but only 98K unique
-- orders. The customers table has duplicate user_ids (one per
-- address). Should I join on (user_id, primary_address_flag)
-- or use DISTINCT?"
-- After user confirms: Uses DISTINCT, retries, succeeds.
-- Remembers: "customers.user_id is not unique"
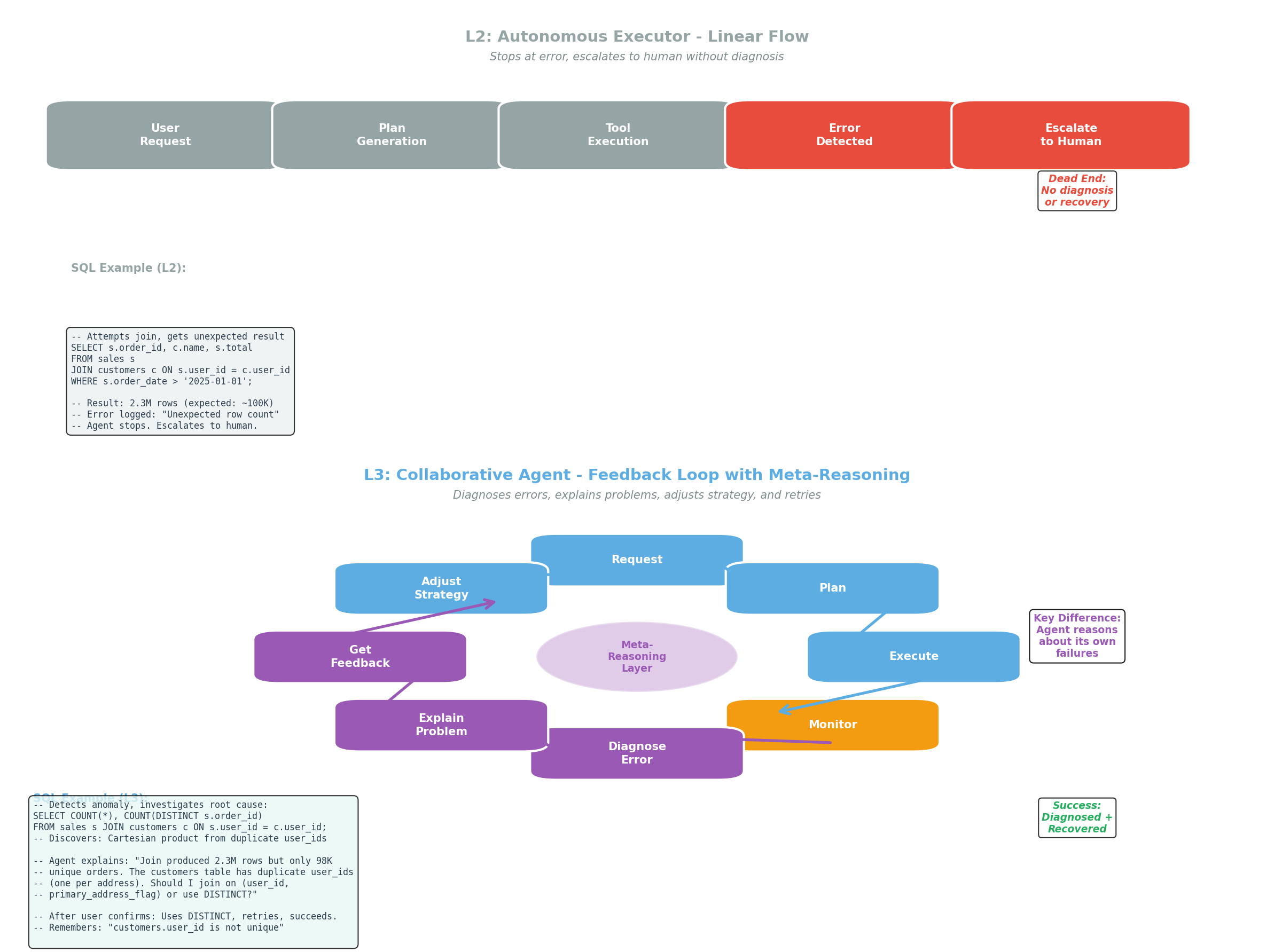 Figure 2: L2 agents follow linear procedural execution (top), stopping at errors and escalating to humans. L3 agents use cyclical feedback loops (bottom) with meta-reasoning to diagnose failures, explain problems, and adjust strategies based on user feedback.
Figure 2: L2 agents follow linear procedural execution (top), stopping at errors and escalating to humans. L3 agents use cyclical feedback loops (bottom) with meta-reasoning to diagnose failures, explain problems, and adjust strategies based on user feedback.
This means L3 systems need:
- Meta-reasoning: Thinking about their own reasoning process
- Failure taxonomy: Categorizing what went wrong (data issue, logic error, ambiguity, tool failure)
- Explanation generation: Articulating failures in user-understandable terms
- Feedback incorporation: Adjusting plans based on corrections
- Persistent memory: Remembering previous failures and solutions
The Autonomy Paradox
Achieving L3 requires advanced reasoning capabilities, but reasoning models are significantly more prone to hallucination than their base model counterparts.
Testing OpenAI's o1 and Anthropic's Claude for multi-step data analysis tasks shows 95%+ accuracy on straightforward queries. But asking them to diagnose their own errors (the meta-reasoning needed for L3) drops accuracy to 60-70%. The very capability that enables autonomy increases unreliability.
Error propagation amplifies this. Even if each step has 95% accuracy—impressive for complex tasks—a 10-step workflow succeeds only 60% of the time. Math is unforgiving:
0.95¹⁰ = 0.599
In a multi-step workflow, a single hallucinated "fact" cascades through subsequent steps. A customer support chatbot that hallucinates might embarrass you. An L3 agent with API access that hallucinates can file tickets, trigger workflows, and move data based on false premises, compounding damage before anyone notices.
Why Success Rates Drop from Demo to Production
Vendor demos show cherry-picked scenarios within carefully constrained domains. "Watch our agent analyze this sales report!" works flawlessly because:
- The data is clean
- The schema is well-documented
- The question is unambiguous
- There's no edge case handling
- Failures are hidden or glossed over
Production looks different:
- Messy data with undocumented quirks
- Schema changes without notice
- Ambiguous user requests
- Legacy systems with weird behaviors
- Failure = lost time and broken trust
At L2, you mitigate this with narrow domains: "This agent only handles X type of query." It works 90%+ of the time because you've constrained the problem space.
At L3, you're promising the agent can handle novel situations—which means encountering the messy reality that breaks demos. Most current systems simply can't reason reliably enough about their own failures to deliver on that promise.
Levels 4-5: The Frontier
L4 and L5 represent the autonomous systems vendors love to tease but rarely deliver.
L4 requires self-sufficient operation within specialized domains. Multi-agent architectures show promise in this space: one agent monitors data quality, another handles transformations, a third validates results, and an orchestrator coordinates them. When something fails, the orchestrator can diagnose which agent encountered issues and implement recovery strategies.
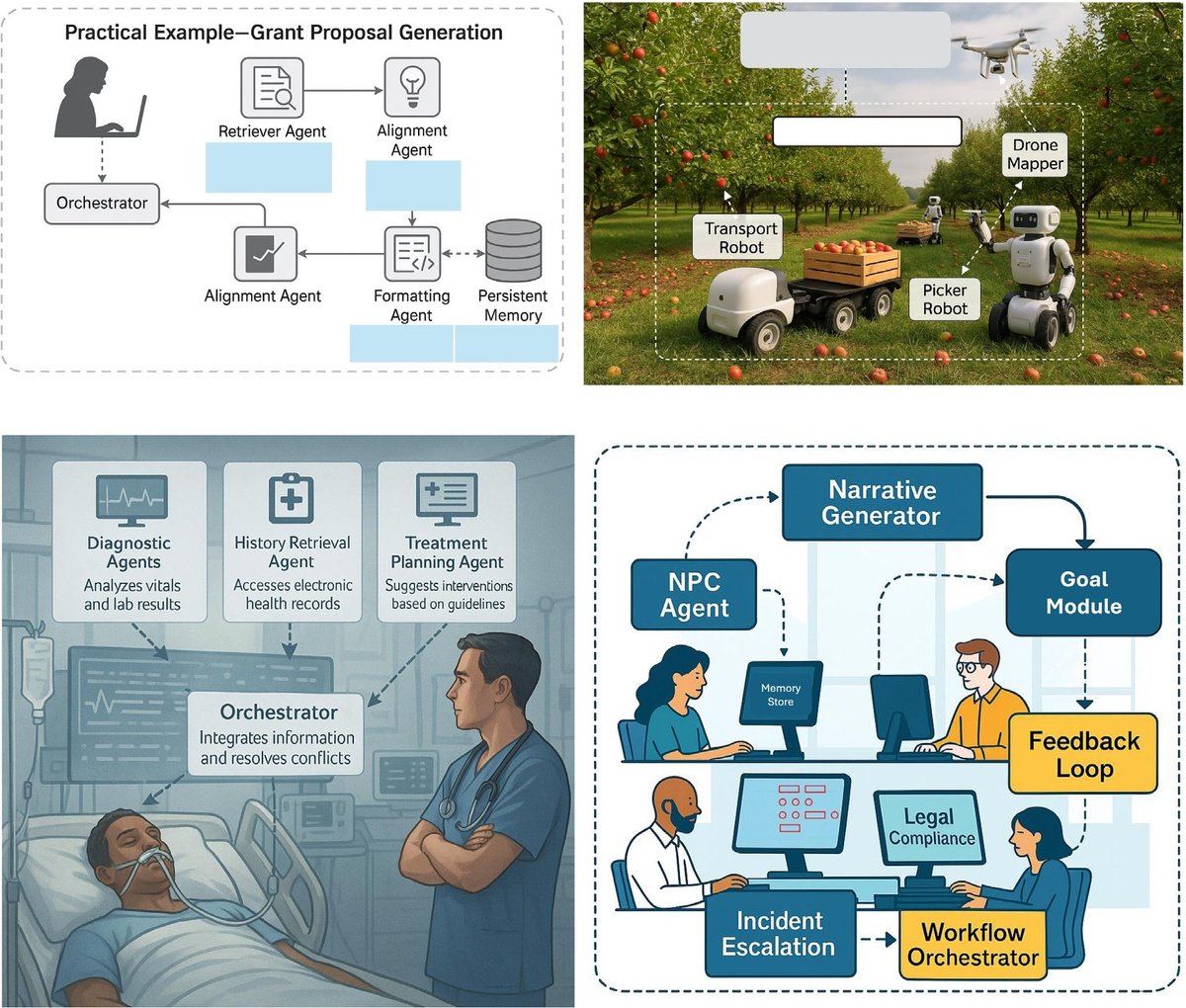 Figure 3: Examples of advanced multi-agent systems showing orchestration patterns for L4 autonomy, including research assistants, medical diagnosis systems, and robotic workflow coordination. (Source: AI Agents vs. Agentic AI Taxonomy, arXiv:2505.10468)
Figure 3: Examples of advanced multi-agent systems showing orchestration patterns for L4 autonomy, including research assistants, medical diagnosis systems, and robotic workflow coordination. (Source: AI Agents vs. Agentic AI Taxonomy, arXiv:2505.10468)
Companies like Matillion are exploring this with products like Maia: teams of specialized agents for data pipeline management. Early results show L3-L4 capability for routine tasks, but human oversight remains essential for anything non-standard.
L5 is science fiction today. A system capable of fully autonomous operation across all data domains, with human-level reasoning and generalization, doesn't exist and won't for the foreseeable future.
What This Means for Evaluating Vendors
When a vendor claims their product is an "autonomous AI agent," ask these questions to figure out what they actually built:
Critical Questions
Ask vendors to demonstrate these scenarios live, not in pre-recorded demos:
1. "What happens when your agent encounters an error it doesn't know how to handle?"
- L1 answer: "It returns an error message to the user."
- L2 answer: "It retries with a different approach automatically."
- L3 answer: "It diagnoses the issue, explains what went wrong, and asks for guidance."
- L4 answer: "It evaluates multiple recovery strategies and implements the most appropriate one."
If they describe anything less than explanation + feedback incorporation, it's not L3.
2. "Show me a multi-step task completed end-to-end without human intervention, including failure handling."
Watch for cherry-picked demos. Ask: "What happens if the data schema changes? If a column is ambiguous? If an API times out?" L2 systems break. L3 systems adapt.
3. "How does your agent incorporate user feedback?"
L2 systems might log feedback for future training. L3 systems adjust their strategy in the current session based on your corrections.
4. "What's your observability story?"
Production agents require comprehensive monitoring. If they can't show you full reasoning traces for every decision, error rate tracking by failure type, latency breakdowns across multi-step workflows, and quality evaluation metrics, they're not production-ready. This applies at any level, but becomes critical at L3+ where reasoning complexity explodes.
Red Flags for Overpromising
Watch for these warning signs:
- Vague architecture descriptions: "AI-powered" without specifics about reasoning, error handling, or feedback loops
- No production deployments: Only pilots and demos, no reference customers running at scale
- "Full autonomy" claims without qualification: "What conditions must be true for full autonomy?"
- Missing observability: Can't show detailed traces of agent reasoning or debugging interfaces
- Guarantees of fast deployment: "AI deployment in 30 days" for complex use cases requiring significant data preparation
- Opaque pricing: Usage-based costs that could explode with increased autonomy
The Evaluation Scorecard
Evaluate vendors across these dimensions:
| Dimension | L1-L2 Indicators | L3+ Indicators |
|---|---|---|
| Autonomy Claims | "Recommends actions" / "Automates tasks" | "Handles exceptions" / "Self-corrects" |
| Architecture | Single-agent, procedural | Multi-agent or feedback loops |
| Error Handling | Returns errors to user | Diagnoses + explains + adapts |
| Feedback | Stateless or batch training | Real-time strategy adjustment |
| Memory | Session-only or none | Persistent across sessions |
| Observability | Basic logging | Full reasoning traces |
| Production Evidence | Demos and pilots | Deployed at scale with metrics |
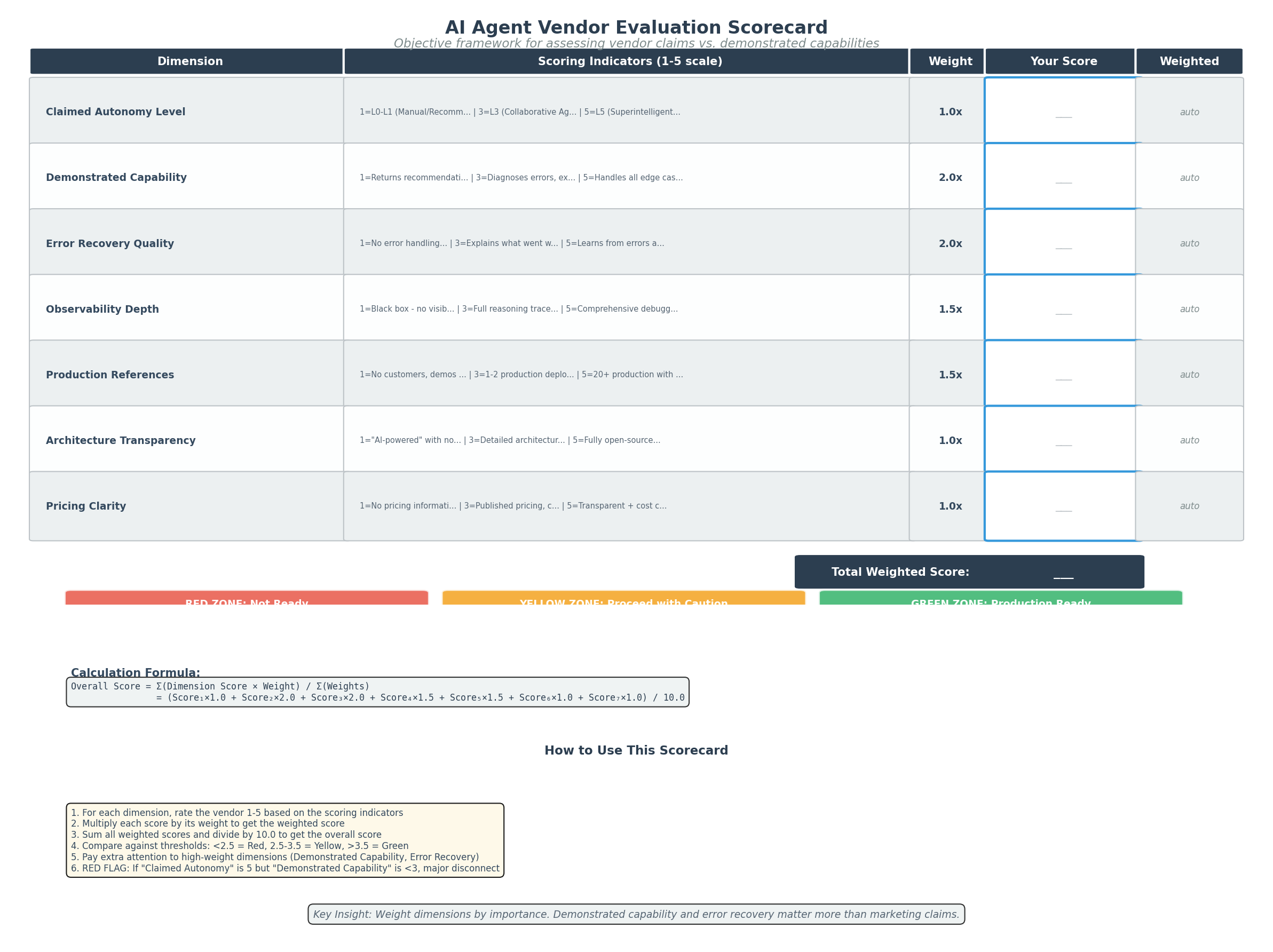 Figure 4: Vendor evaluation scorecard with weighted dimensions (1-5 scale). Demonstrated Capability and Error Recovery receive 2.0x weight as they most accurately reveal true autonomy level. Overall readiness scores: Red (<2.5), Yellow (2.5-3.5), Green (>3.5).
Figure 4: Vendor evaluation scorecard with weighted dimensions (1-5 scale). Demonstrated Capability and Error Recovery receive 2.0x weight as they most accurately reveal true autonomy level. Overall readiness scores: Red (<2.5), Yellow (2.5-3.5), Green (>3.5).
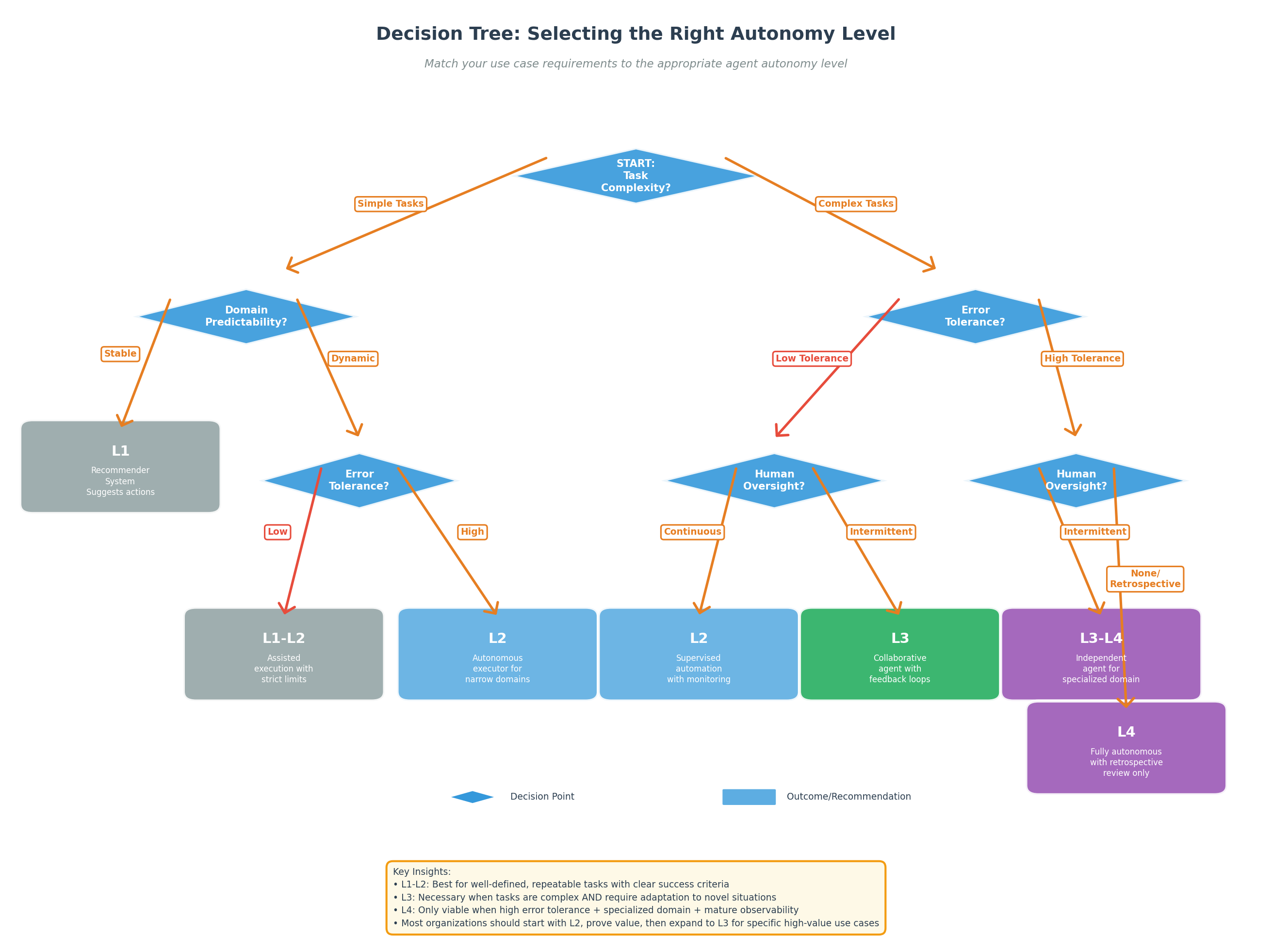 Figure 5: Decision tree for selecting appropriate autonomy level based on task characteristics and organizational constraints. Most use cases currently benefit from starting at L2, proving value, then selectively advancing to L3 when justified.
Figure 5: Decision tree for selecting appropriate autonomy level based on task characteristics and organizational constraints. Most use cases currently benefit from starting at L2, proving value, then selectively advancing to L3 when justified.
Getting Started: A Practical Approach
Most organizations don't need L3+ agents today. L2 systems deliver tremendous value for well-defined tasks with narrow domains:
- Automated reporting for standard queries
- Data quality checks with known patterns
- NL2SQL for routine business questions
- Scheduled data transformations
Start there. Measure carefully:
- Task completion rate (target 90%+)
- Time saved vs. manual approaches
- Error rate and types
- User satisfaction
Only consider L3+ when:
- Your use cases are too diverse for narrow domains
- Users need to handle novel situations
- Error rates prevent L2 from delivering value
- You have mature observability infrastructure
- You can justify the higher costs (infrastructure, monitoring, continuous refinement)
Understanding the Gap
Most "autonomous AI agents" are sophisticated L2 executors marketed as L3 collaborative agents. That's not necessarily dishonest; terminology confusion pervades this rapidly evolving space. But it matters because the L2→L3 gap explains why demos impress while production disappoints.
The gap exists because L3 requires meta-reasoning about failures, and current LLMs hallucinate more when reasoning about reasoning. Error propagation in multi-step workflows amplifies every mistake. Until we solve this reliability problem, L3 remains aspirational for most applications.
L2 is valuable. Automated execution of well-defined tasks saves time and reduces errors. Match your expectations to actual capabilities and don't pay L3+ prices for L2 functionality.
As you evaluate agent products, use this framework to cut through marketing claims:
- Ask the critical questions about error handling and feedback
- Demand production evidence, not just demos
- Assess observability rigorously
- Start with L1-L2, prove value, then explore L3 only when needed
The 6-level framework gives you a common language for these conversations. When a vendor claims "full autonomy," ask: "Which autonomy level? What's your L2→L3 story?" Most will struggle to answer.
The market will mature. Reasoning models will improve. Observability will standardize. L3 will become more achievable. But today, understanding where the gaps exist will save you from expensive pilots that were never going to work and help you recognize the vendors building genuine autonomous systems when they finally arrive.
References
- Zhu et al. (2025). "A Survey of Data Agents: Emerging Paradigm or Overstated Hype?" arXiv:2510.23587
- SAE International (2021). "Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles." SAE J3016
- "AI Agents vs. Agentic AI: A Taxonomy" arXiv:2505.10468
- Market Research: AI Agents Data Analysis Market projected 38.1B (2034), 38.2% CAGR
- Enterprise adoption: 45% of Fortune 500 companies piloting agent systems (2025)