Mixtral 8x7B has 46.7 billion parameters. But it only uses about 13 billion of them for any given input.1 This is not a bug. It is the entire point.
This architectural sleight of hand is called Mixture of Experts (MoE), and it powers some of the most capable AI systems today. Gemini 1.5, DeepSeek V3, and Mixtral all use variations of this approach.2 The result? Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference.3
For software engineers, the efficiency gains are hard to ignore. But MoE comes with hidden costs that rarely make the headlines. This post explains how it works, what tradeoffs you accept, and when it makes sense for your use case.
What Is Mixture of Experts?
Think of a hospital emergency room. You do not get examined by every specialist on staff. Instead, a triage nurse quickly assesses your symptoms and routes you to the right doctors. A broken arm goes to orthopedics. Chest pain goes to cardiology. The hospital has massive capacity (50 doctors) but any individual visit requires only modest resources (2 consultations).
MoE works the same way. "The MoE consists of a number of experts, each a simple feed-forward neural network, and a trainable gating network which selects a sparse combination of the experts to process each input."4
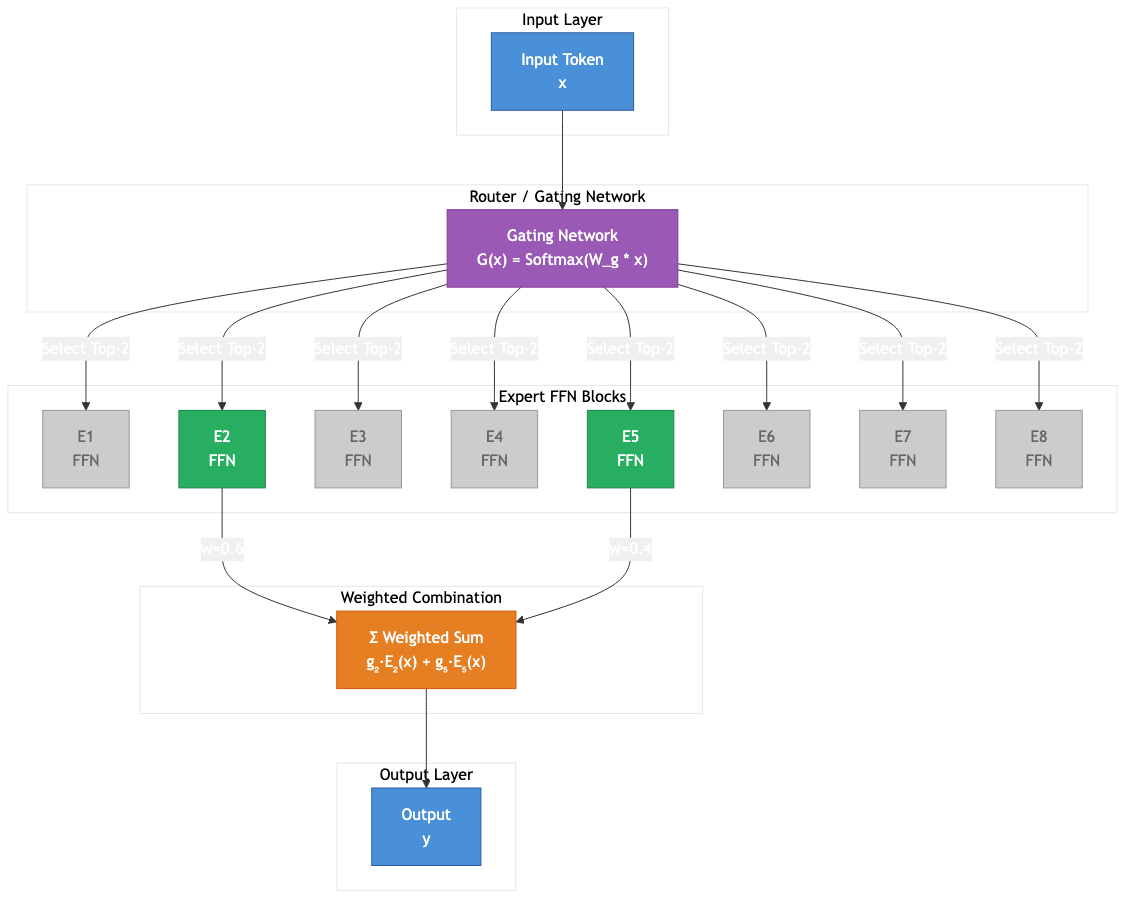 Figure 1: MoE architecture showing input token flowing through router to selected experts. Source: Author visualization based on Shazeer et al. (2017)4
Figure 1: MoE architecture showing input token flowing through router to selected experts. Source: Author visualization based on Shazeer et al. (2017)4
For software engineers, think of it like a microservices architecture where a load balancer decides which service handles each request. The model does the same thing, but for neural network components.
How Routing Works
The router is surprisingly simple. It takes each input token and produces a score for each expert. The highest-scoring experts process that token. Their outputs combine with learned weights.
"For every token, at each layer, a router network selects two of these groups (the experts) to process the token and combine their output additively."5
The key insight: the router learns during training which experts handle which inputs well. No human designs the specialization. The network discovers it.
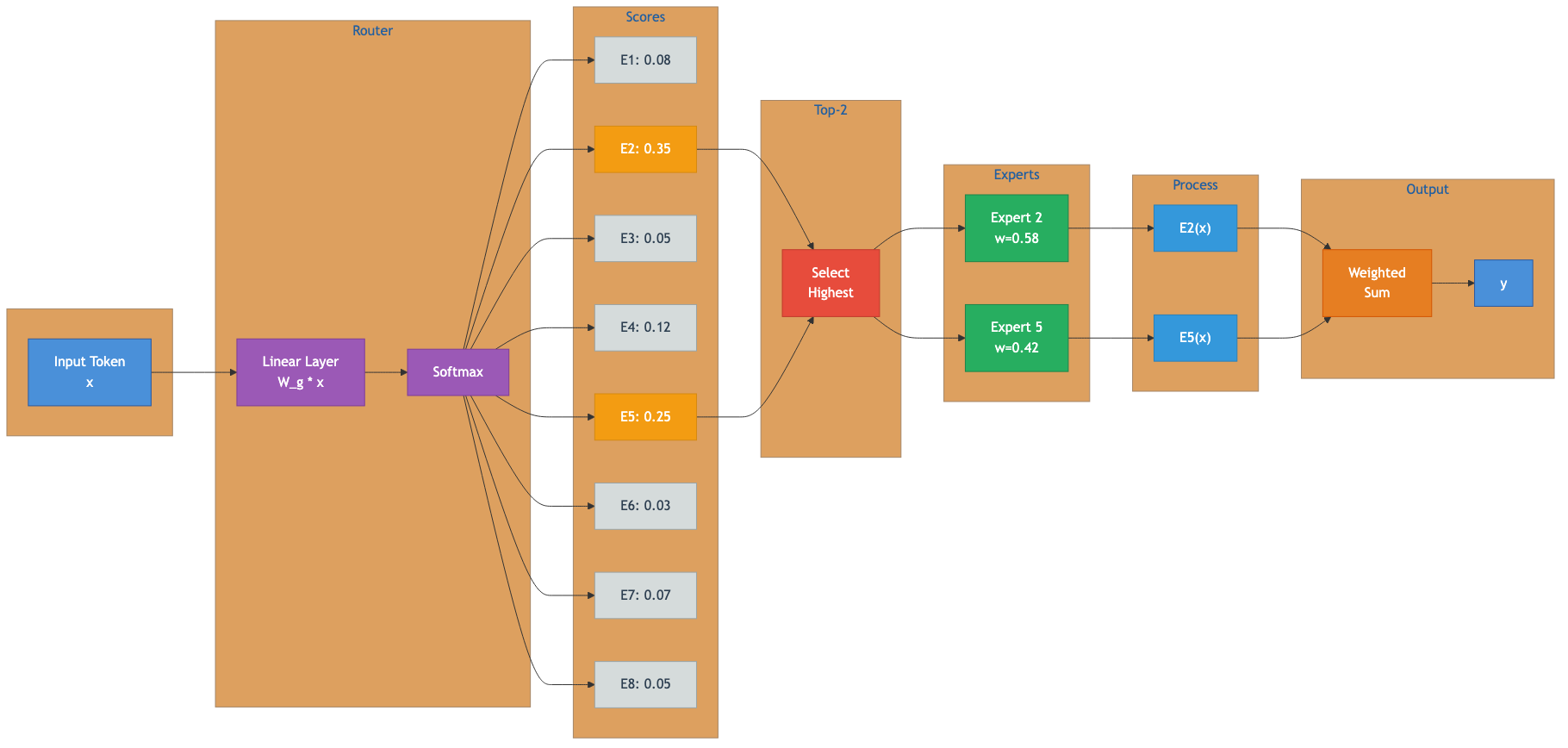 Figure 2: Router decision process showing softmax scoring and top-2 expert selection. Source: Author visualization based on Mixtral architecture5
Figure 2: Router decision process showing softmax scoring and top-2 expert selection. Source: Author visualization based on Mixtral architecture5
The result is dramatic. Mixtral has 46.7B total parameters but only uses 12.9B per token.6 You get the knowledge capacity of a 47B model with the inference cost of a 13B model.
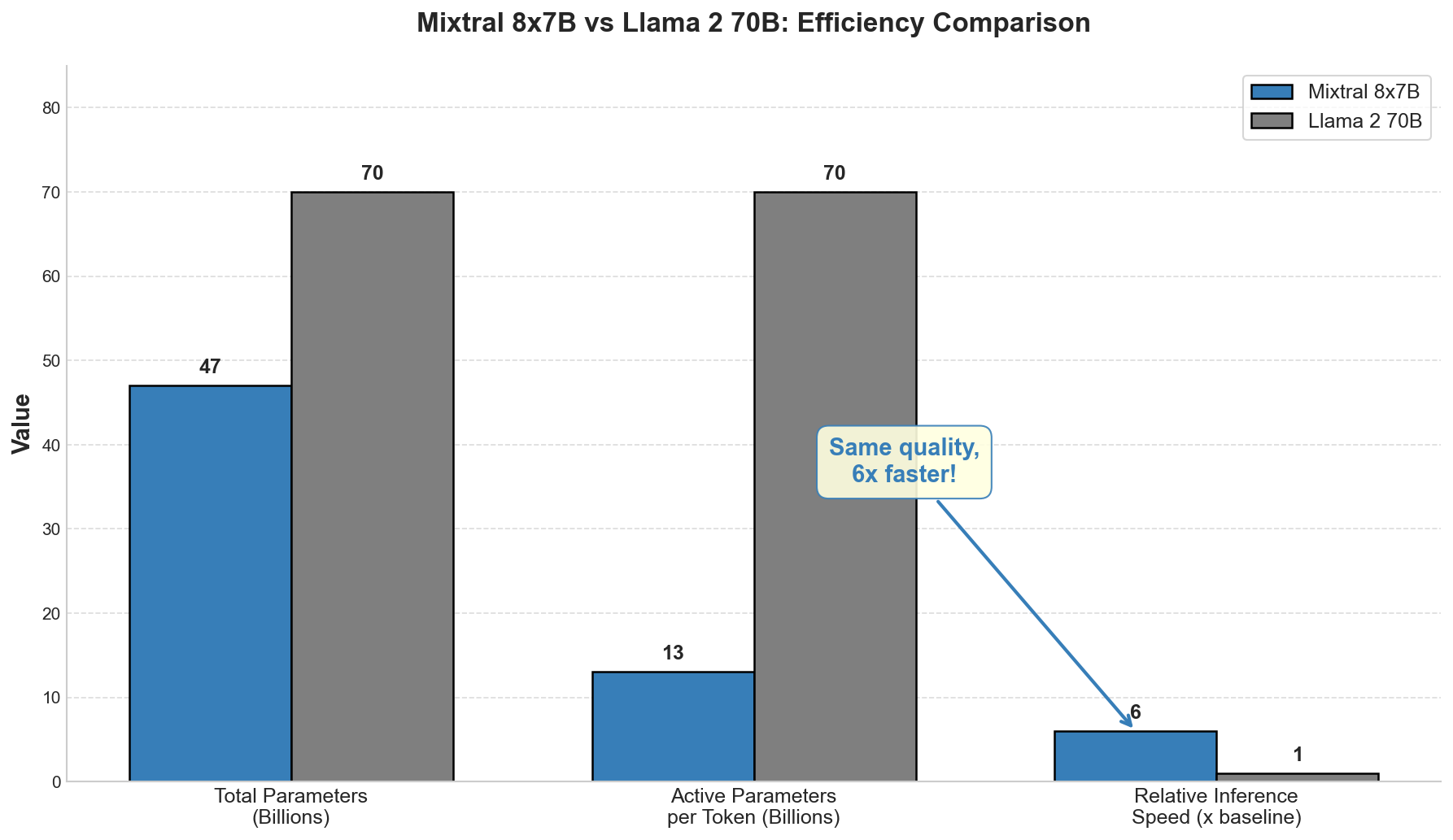 Figure 3: Parameter and speed comparison between Mixtral 8x7B and Llama 2 70B. Source: Data from Jiang et al. (2024)13
Figure 3: Parameter and speed comparison between Mixtral 8x7B and Llama 2 70B. Source: Data from Jiang et al. (2024)13
The Hidden Costs
No free lunch. MoE has real tradeoffs that do not show up in benchmark headlines.
Load Balancing Is Hard
The router has a natural tendency to pick favorites. "One issue with MoEs is that the network has a tendency to repeatedly utilize the same few experts during training."7 Popular experts get more training, become even better, and get selected even more.
Why does this matter? If 8 tokens in a batch of 10 route to Expert A while Experts B through H each get one token, you have created a bottleneck. Modern GPUs cannot efficiently process such uneven batches. Your theoretical speedup evaporates.
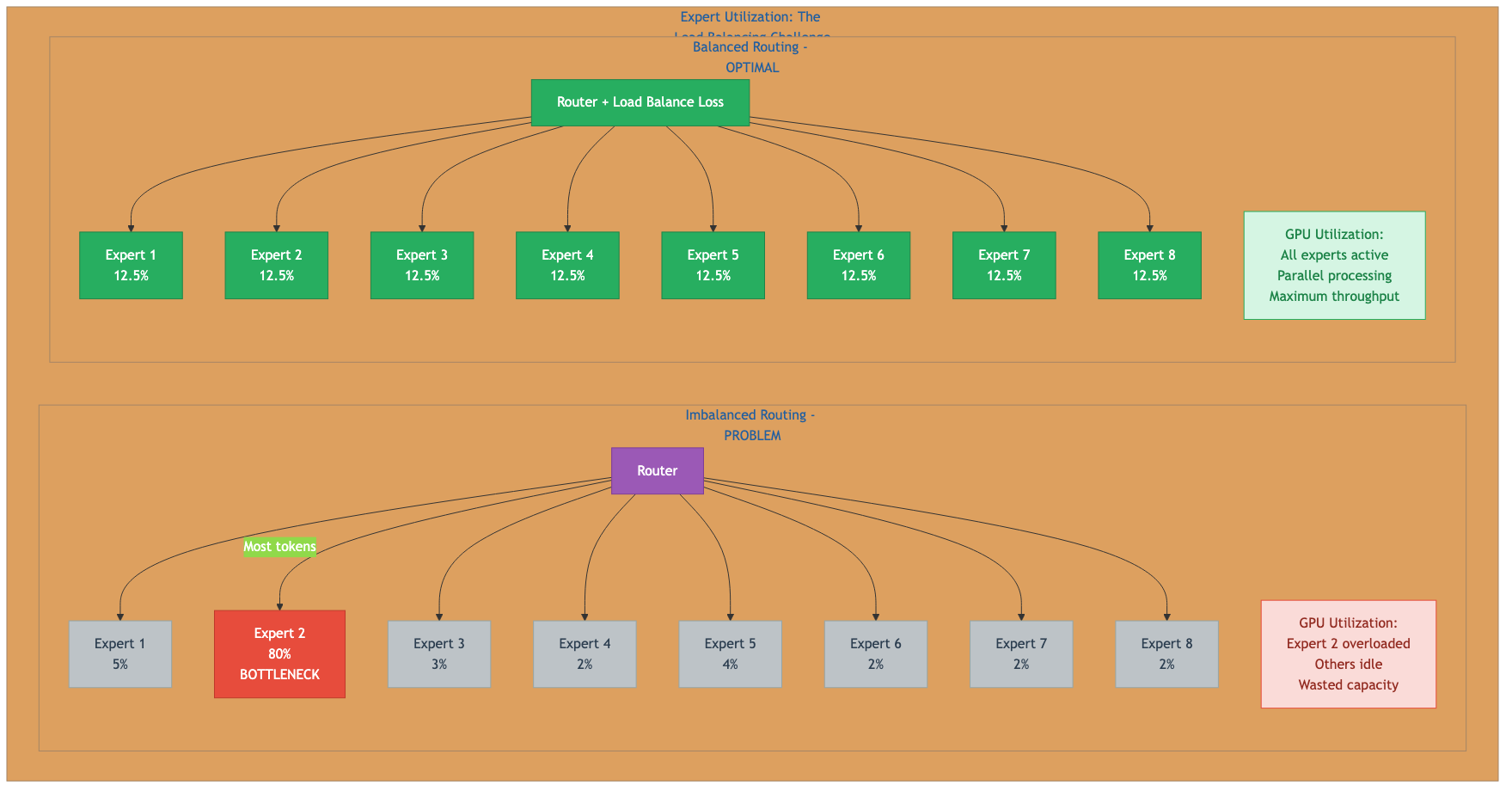 Figure 4: Imbalanced vs balanced expert routing and GPU utilization impact. Source: Author visualization based on Fedus et al. (2022)8
Figure 4: Imbalanced vs balanced expert routing and GPU utilization impact. Source: Author visualization based on Fedus et al. (2022)8
The solution? "The auxiliary load balancing loss encourages uniform routing by penalizing uneven expert utilization."9 This loss competes with your actual training objective. Getting the balance right requires careful tuning.
Memory Still Hurts
Consider the number that MoE marketing tends to skip. "MoE models consume more VRAM as all experts must be loaded into memory even though only a few are activated."10
Mixtral uses 12.9B parameters per token. Great. But you still need to fit all 46.7B parameters in GPU memory. That typically means 4x A100 80GB GPUs or equivalent. The inference is faster, yes. But your hardware requirements are set by total parameters, not active parameters.
Fine-tuning Is Tricky
"MoE models are prone to overfitting and notoriously difficult to finetune."11 The combination of massive parameter count and sparse activation creates a generalization problem. Your fine-tuning examples might only update a subset of experts. Experts that specialize in other patterns may drift or degrade.
Research suggests increasing "dropout on MoE layers during finetuning to prevent overfitting."8 These are not obvious choices, and getting them wrong can ruin your model.
When to Use MoE
Based on the research and real-world deployments, consider this practical framework:
Use MoE when:
- You are pretraining at massive scale with trillions of tokens. "Given a sufficiently large pretraining dataset, MoE models tend to learn faster than a compute-matched dense model."12
- Inference throughput matters more than latency per request. The batch efficiency offsets the memory overhead.
- You have multi-GPU infrastructure. MoE requires distributed deployment; if you already operate at that scale, the additional complexity is manageable.
Stick with dense models when:
- VRAM is constrained. A 7B dense model fits where a 46.7B MoE does not.
- You are fine-tuning on small datasets. The overfitting risk is real.
- Single-request latency is the primary constraint. For sub-50ms inference, routing overhead can hurt.
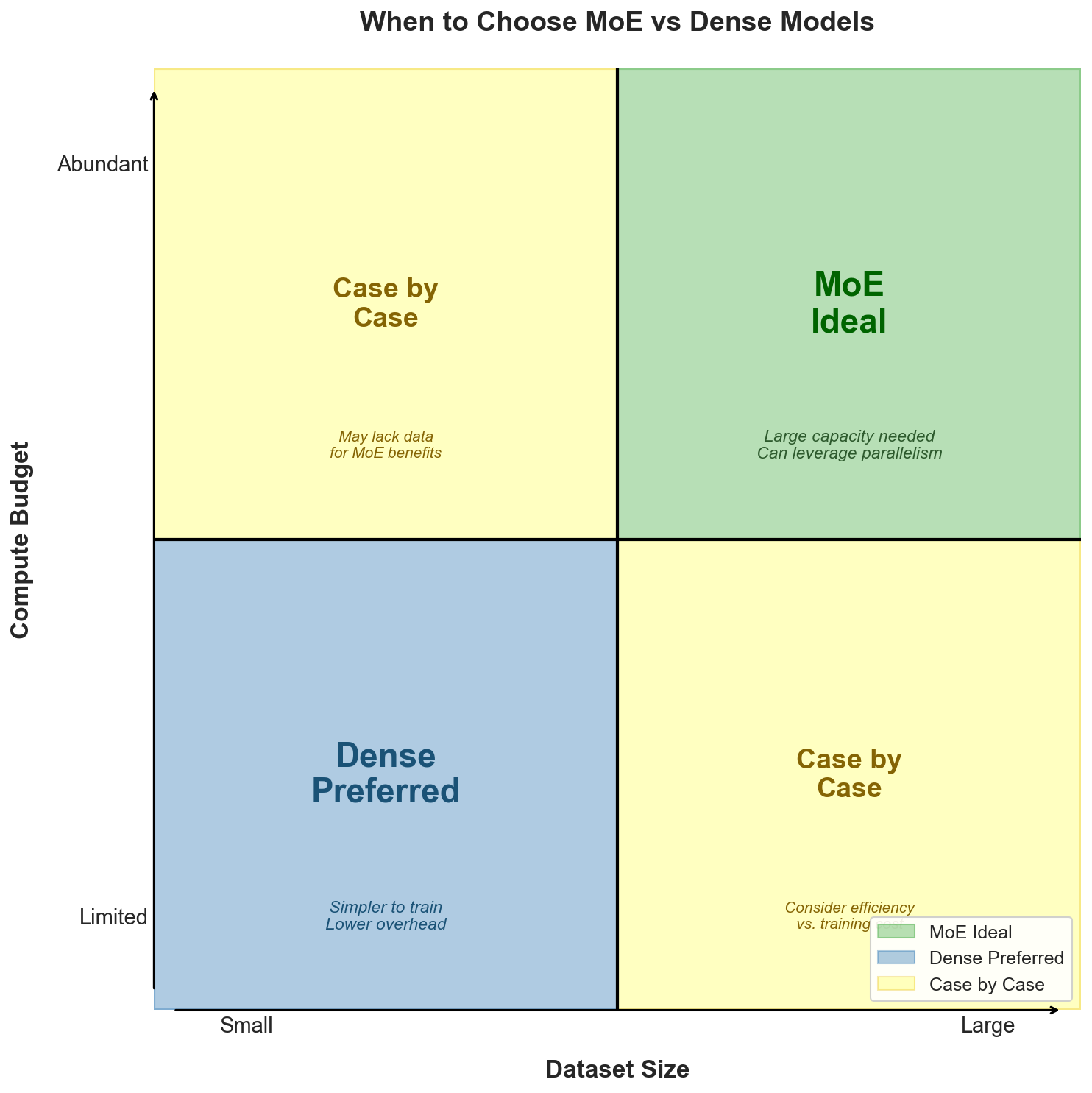 Figure 5: Decision framework for choosing between MoE and dense models. Source: Author synthesis based on research findings12
Figure 5: Decision framework for choosing between MoE and dense models. Source: Author synthesis based on research findings12
The Bottom Line
The fundamental insight behind MoE is real: "The fundamental idea behind an MoE is to decouple a model's parameter count from the amount of compute that it uses."13 This is powerful.
Mixtral, Gemini 1.5, and DeepSeek V3 prove MoE works at production scale. DeepSeek V3 pushes this further with 671B total parameters but only 37B activated.14 These are not research prototypes. They are production models serving millions of users.
For software engineers watching the AI space, MoE explains why capability is scaling faster than cost. It is not magic. It is conditional computation, finally made practical at scale.
References
Footnotes
-
Jiang, A. Q., et al. (2024). "Mixtral of Experts." arXiv:2401.04088. "Mixtral has 46.7B total parameters but only uses 12.9B parameters per token." ↩ ↩2
-
Google. (2024). "Gemini 1.5: Unlocking Multimodal Understanding." arXiv:2403.05530; DeepSeek AI. (2024). "DeepSeek-V3 Technical Report." arXiv:2412.19437. ↩
-
Jiang, A. Q., et al. (2024). "Mixtral of Experts." arXiv:2401.04088. "Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference." ↩ ↩2
-
Shazeer, N., et al. (2017). "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer." arXiv:1701.06538. ↩ ↩2
-
Jiang, A. Q., et al. (2024). "Mixtral of Experts." arXiv:2401.04088. Section 2.1. ↩ ↩2
-
Jiang, A. Q., et al. (2024). "Mixtral of Experts." arXiv:2401.04088. "Mixtral has 46.7B total parameters but only uses 12.9B parameters per token." ↩
-
Wolfe, C. R. (2024). "Conditional Computation: The Birth and Rise of Conditional Computation." https://cameronrwolfe.substack.com/p/conditional-computation-the-birth ↩
-
Fedus, W., et al. (2022). "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity." ICLR 2022. ↩ ↩2
-
Hugging Face. (2023). "Mixture of Experts Explained." https://huggingface.co/blog/moe ↩
-
Wolfe, C. R. (2024). "Conditional Computation." "MoE models consume more VRAM as all experts must be loaded into memory even though only a few are activated." ↩
-
Wolfe, C. R. (2024). "Conditional Computation." "MoE models are prone to overfitting and notoriously difficult to finetune." ↩
-
Wolfe, C. R. (2024). "Conditional Computation." "Given a sufficiently large pretraining dataset, MoE models tend to learn faster than a compute-matched dense model." ↩ ↩2
-
Wolfe, C. R. (2024). "Conditional Computation." "The fundamental idea behind an MoE is to decouple a model's parameter count from the amount of compute that it uses." ↩
-
DeepSeek AI. (2024). "DeepSeek-V3 Technical Report." arXiv:2412.19437. "DeepSeek V3 uses a novel Multi-head Latent Attention (MLA) architecture with 671B total parameters and 37B activated parameters." ↩