Large Language Models and Emergence: A Complex Systems Perspective
Large language models show surprising new capabilities as they grow. A model with 13 billion parameters can't do modular arithmetic. A model with 540 billion parameters suddenly can. A model below 100 billion parameters barely learns from examples in context. Above that threshold, it excels at few-shot learning. Are we watching intelligence emerge, or are we watching a measurement trick?
This question shapes billion-dollar decisions about scaling strategy, safety research, and fundamental assumptions about what these systems can become. A 2025 paper by complexity scientists David Krakauer, John Krakauer, and cognitive scientist Melanie Mitchell brings a new lens to this debate. Their insight: we're asking the wrong question. Instead of "is emergence real or fake," we should ask "what type of emergence are we looking at, and at what level of description?"
The answer matters because it determines whether we should expect unpredictable capability jumps or smooth, forecastable improvements as we scale toward ever-larger models.
What Emergence Actually Means
Start with water. One H₂O molecule behaves predictably according to quantum mechanics. A billion H₂O molecules also behave predictably, but at a completely different level of description. Place those billion molecules together at the right temperature and pressure, and something genuinely new appears. Ice has crystalline structure. Water has viscosity. Steam has pressure. These properties don't exist in isolated molecules. You can't predict ice from studying a single water molecule, no matter how thoroughly you understand it.
This is Philip Anderson's 1972 principle: "More is Different." At each level of organizational complexity, entirely new properties appear that require new vocabulary, new laws, new reduced-dimensional descriptions. We don't describe ice using quantum mechanics. We use temperature, pressure, entropy: concepts that emerge from statistics over many particles.
In complexity science, emergence requires three elements:
First, many interacting components: enough that tracking individual states becomes intractable. Ice contains septillions of molecules. At some point, you stop thinking about molecules and start thinking about crystal defects.
Second, interactions among components that produce collective behaviors. The molecular bonds in ice aren't special. But collectively, they create structure that makes ice less dense than water, a property invisible at the molecular level.
Third, new reduced-dimensional descriptions that capture system behavior without tracking every component. Thermodynamics doesn't track molecules. It tracks macroscopic properties that emerge from microscopic interactions.
Now apply this framework to large language models. In 2022, Wei et al. published "Emergent Abilities of Large Language Models," documenting dozens of tasks where performance jumped discontinuously at certain scales:
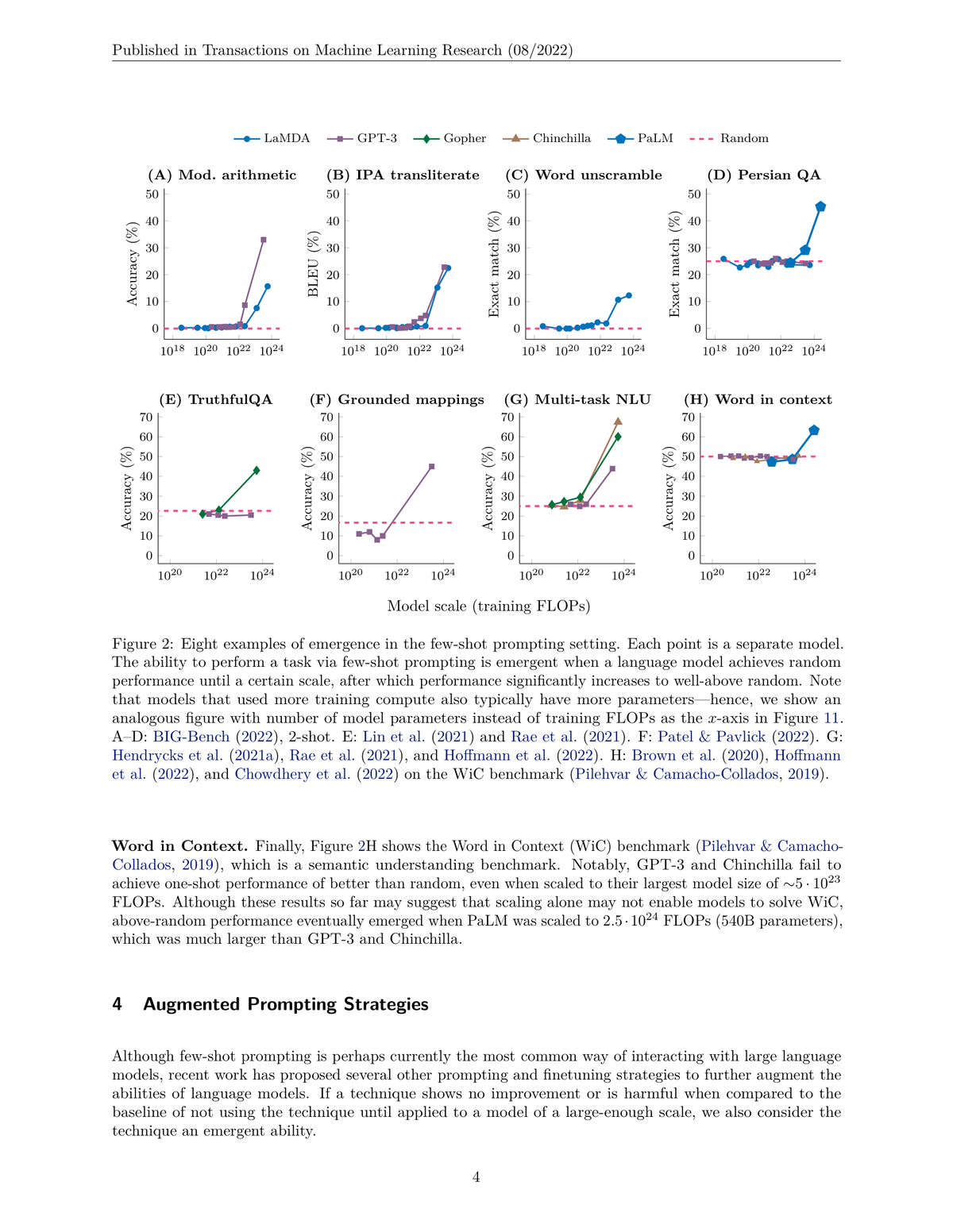 Figure 1: Eight examples of emergent abilities across different tasks. Performance remains near random until a critical scale, after which it jumps discontinuously. Tasks include modular arithmetic, transliteration, word unscrambling, and factual reasoning. Each panel shows different models (LaMDA, GPT-3, Gopher, Chinchilla, PaLM) with model scale on x-axis (training FLOPs) and accuracy on y-axis. Source: Wei et al., 2022
Figure 1: Eight examples of emergent abilities across different tasks. Performance remains near random until a critical scale, after which it jumps discontinuously. Tasks include modular arithmetic, transliteration, word unscrambling, and factual reasoning. Each panel shows different models (LaMDA, GPT-3, Gopher, Chinchilla, PaLM) with model scale on x-axis (training FLOPs) and accuracy on y-axis. Source: Wei et al., 2022
Look at panel A: modular arithmetic. GPT-3 at 175 billion parameters performs near random, effectively guessing. PaLM at 540 billion parameters performs near-perfectly. Nothing gradual. The capability appears suddenly, like water freezing at exactly zero degrees.
This looked like genuine emergence: phase transitions in capability space.
The Mirage Problem
But here's where measurement becomes everything.
In 2023, Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo won NeurIPS's Outstanding Paper Award for "Are Emergent Abilities of Large Language Models a Mirage?" Their argument cuts deep: the appearance of emergence depends entirely on how you measure.
Take that same arithmetic task. If you measure using "exact match" (did the model get every digit right?), performance looks binary: wrong, wrong, wrong, suddenly right. Apparent emergence. But measure the same capability using token edit distance (how many characters differ from the correct answer) and you see smooth, gradual improvement: 10% accuracy, 30%, 60%, 85%, 95%. Same model, same capability. The metric created the cliff.
The pattern holds across tasks. Use discontinuous metrics (exact match, multiple choice), get discontinuous-looking improvements. Use continuous metrics (edit distance, Brier score, token probabilities), get smooth scaling curves following power laws.
This matters because Wei et al.'s influential dataset, BIG-Bench, uses predominantly discrete evaluation metrics. When you re-evaluate the same models on the same tasks with continuous metrics, most "emergence" disappears. The capabilities were improving gradually all along. We just couldn't see it through our binary measurement lens.
The Complexity Science Reframe
This is where Krakauer et al. change the entire conversation. Rather than arguing whether emergence is "real" or "fake," they distinguish between fundamentally different types of emergence:
Knowledge-Out (KO) emergence: Simple components following simple rules produce complex behavior. Birds follow three rules: maintain distance, match heading, move toward center. No bird knows where the flock is going, yet the flock exhibits coordinated motion. Water molecules follow physics laws. Ice emerges. The complexity wasn't in the components. It emerged from their interactions.
Knowledge-In (KI) emergence: Complex components extract knowledge from complex environments, then self-organize. Brain neurons aren't simple. They receive thousands of inputs, integrate information, execute complex computations. The brain learns from sensory experience. Its capabilities emerge from knowledge acquired through interaction with a structured world.
LLMs are unambiguously Knowledge-In systems. They're not simple units following simple rules. They're transformers with billions of parameters, trained on human-generated text via sophisticated optimization, learning to compress patterns from the accumulated knowledge of human civilization.
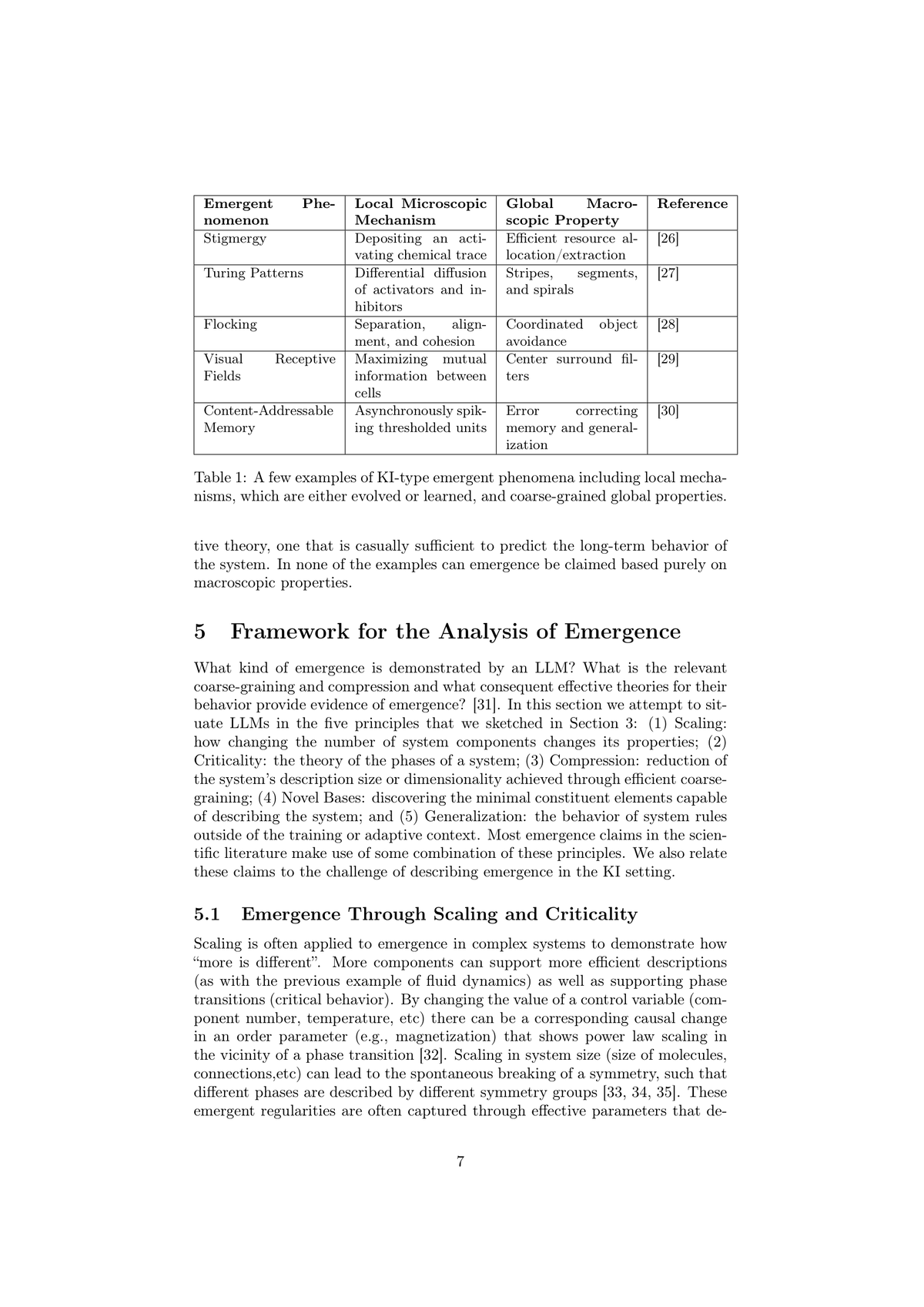 Figure 2: Examples of Knowledge-In (KI) type emergent phenomena in complex systems. Each row shows how local microscopic mechanisms produce global macroscopic properties. For LLMs, the mechanism is gradient descent on next-token prediction; the global property is capabilities like reasoning. Source: Krakauer et al., 2025
Figure 2: Examples of Knowledge-In (KI) type emergent phenomena in complex systems. Each row shows how local microscopic mechanisms produce global macroscopic properties. For LLMs, the mechanism is gradient descent on next-token prediction; the global property is capabilities like reasoning. Source: Krakauer et al., 2025
This distinction matters because it reframes the question. We're not asking whether intelligence spontaneously crystallizes at scale like ice from water. We're asking whether LLMs develop genuinely new ways of processing information as they scale, or whether they're simply getting better at the same underlying pattern-matching task.
Genuine Phase Transitions: Grokking and In-Context Learning
Despite the measurement artifact critique, some phenomena show genuine phase transitions with mechanistic backing.
In-context learning exhibits clear threshold behavior. Models below roughly 100 billion parameters show minimal ability to adapt behavior based on examples in the prompt. They can't learn from context; they just apply their pre-trained patterns. Cross that threshold, and models suddenly excel at learning new tasks from a few examples without any parameter updates.
Mechanistic interpretability reveals why. Large models develop "induction heads": specific attention patterns that copy and complete patterns from earlier in the context. These circuits don't exist in smaller models. They emerge at scale because they require sufficient capacity and feature diversity. This isn't a measurement artifact. You can trace the mechanism in the model's attention patterns.
Grokking provides even stronger evidence. In 2025, Li et al. published the first empirical evidence of grokking in large-scale language model pretraining. Models transition from memorizing training data to discovering generalizable patterns, not gradually, but through sharp phase transitions with information-theoretic signatures.
During training, different knowledge domains undergo grokking asynchronously. The model memorizes facts about early history, then suddenly generalizes to unfamiliar historical periods. Later, it undergoes a similar transition for scientific concepts. Each transition shows the characteristic signature: prolonged memorization, sudden generalization, continued refinement.
These aren't artifacts of how we measure. They're genuine reorganizations of how the model processes information.
The Scaling Laws Tension
Here's the paradox. We know neural networks improve predictably with scale, following power laws. Kaplan et al. and subsequent work established this: performance improves as roughly log(parameters). The improvement is smooth, continuous, remarkably forecastable. You can predict how well a model will perform at a given scale with considerable accuracy.
If improvement is predictable and continuous, how can capabilities "emerge" unpredictably?
Krakauer et al. offer a resolution: different levels of description reveal different phenomena.
At the parameter level, everything is continuous. Add parameters, loss decreases smoothly. No emergence here.
At the behavioral level, improvement crosses thresholds where capabilities become practically useful. A model might improve continuously at predicting tokens, but only at a certain accuracy does this translate to "can solve arithmetic problems." The underlying improvement is smooth; the behavioral manifestation appears discontinuous.
At the mechanistic level, genuine phase transitions occur. Induction heads emerge. Circuits reorganize. The model transitions from memorization to generalization. These are real discontinuities in how information flows through the network.
At the conceptual level, new descriptions become necessary. We stop talking about token probabilities and start talking about "reasoning" or "in-context learning," not because we're being sloppy, but because these higher-level descriptions capture patterns that lower-level descriptions miss.
More Is Different Versus Less Is More
The core tension Krakauer et al. identify: two competing visions of what intelligence means at scale.
"More is Different" says scale enables entirely new capabilities. Larger models don't just do the same things better; they access completely new modes of processing. Each order of magnitude unlocks capabilities that smaller models cannot achieve regardless of training time. Intelligence emerges from scale.
"Less is More" says intelligence means doing more with existing capabilities. Scale doesn't create new abilities; it refines execution of existing ones. A larger model solves problems more efficiently, more accurately, with better generalization. But the fundamental approach remains continuous with smaller models.
The evidence supports both, depending on the capability:
In-context learning looks like "More is Different": a genuinely new ability to learn from examples that smaller models lack entirely.
Arithmetic looks like "Less is More": models get progressively better at pattern-matching numerical relationships, with no transition in approach.
Chain-of-thought reasoning sits between: it works poorly below certain scales, then becomes effective, but the mechanism appears to be better internal state tracking rather than entirely new processing.
 Figure 3: Framework showing the spectrum of emergence in LLMs, from continuous improvements to genuine phase transitions to measurement artifacts. The diagram illustrates how the same underlying model improvements can appear as smooth scaling (Track 1), sharp phase transitions (Track 2), or measurement artifacts (Track 3) depending on the capability and metric used. Scale thresholds (10B, 100B, 500B parameters) are shown at top, with evidence from Wei et al., Schaeffer et al., and Li et al. supporting each track.
Figure 3: Framework showing the spectrum of emergence in LLMs, from continuous improvements to genuine phase transitions to measurement artifacts. The diagram illustrates how the same underlying model improvements can appear as smooth scaling (Track 1), sharp phase transitions (Track 2), or measurement artifacts (Track 3) depending on the capability and metric used. Scale thresholds (10B, 100B, 500B parameters) are shown at top, with evidence from Wei et al., Schaeffer et al., and Li et al. supporting each track.
Why the Distinction Matters
Your position on emergence determines your strategy:
If you believe emergence is real:
- Invest heavily in scaling; each order of magnitude might unlock unprecedented capabilities
- Develop reliable capability detection systems for sudden jumps
- Prioritize interpretability research to understand mechanisms before they surprise us
- Prepare governance frameworks for discontinuous capability improvements
If you believe emergence is mostly measurement artifact:
- Focus on architectural efficiency over raw scale
- Use continuous metrics to track actual capability improvement
- Invest in data quality and training innovations rather than pure scaling
- Develop governance based on predictable capability trajectories
If you believe both are true (most aligned with evidence):
- Different capabilities require different strategies
- Map which capabilities show genuine phase transitions (in-context learning) versus continuous improvement (factual knowledge)
- Develop mechanistic understanding of specific capabilities rather than treating "emergence" as monolithic
- Recognize diminishing returns in some domains while expecting surprises in others
The practical reality: we're hitting data constraints. Multiple researchers identify training data scarcity as the binding constraint for continued scaling. OpenAI's o1 reportedly achieves gains through test-time compute (thinking longer) rather than pure scale increases. The era of "just make it bigger" may be ending, making these distinctions more critical.
What's Actually Emerging
Setting aside philosophical debates, what can we say concretely about LLM capabilities?
Improving continuously: General pattern-matching ability, factual knowledge coverage, cross-domain transfer, token prediction accuracy. These follow predictable scaling laws without discontinuities.
Showing genuine phase transitions:
- In-context learning (threshold ~100B parameters)
- Grokking dynamics (memorization-to-generalization transitions)
- Chain-of-thought effectiveness (emerges around 50-100B parameters)
- Instruction-following robustness (quality jumps at specific scales)
Creating measurement artifacts:
- Most arithmetic tasks (exact-match scoring creates artificial cliffs)
- Translation quality (BLEU scores discretize continuous improvement)
- Code generation (pass/fail tests hide gradual improvement)
- Factual accuracy (binary correct/incorrect masks partial knowledge)
Still mechanistically mysterious:
- How abstract reasoning emerges from next-token prediction
- Why models fail at simple tasks humans find trivial while excelling at complex ones
- What determines which capabilities emerge at which scales
- Whether alternative architectures would show different emergence patterns
That last point is crucial. Almost all emergence research focuses on Transformer-based architectures trained with next-token prediction. Would emergence look different with alternative architectures, different training objectives, or different data distributions? We're studying one path through a vast space.
Open Questions That Would Resolve the Debate
The emergence question will likely remain contested until we answer:
Can we predict emergence? If we understand the mechanisms behind in-context learning and grokking well enough, can we forecast when new capabilities will emerge? Prediction would suggest emergence follows discoverable laws rather than being fundamentally unpredictable.
Is emergence architecture-dependent or fundamental? Would radically different architectures (not Transformers) show the same emergence patterns? If emergence is fundamental to intelligence, it should appear across architectures. If it's contingent, different designs might avoid or accelerate it.
How do we measure what matters? We evaluate what's easy to measure (exact match, multiple choice) not what we care about (robust reasoning, reliable assistance, aligned behavior). Would better metrics reveal different emergence patterns?
What are the hard limits? Does each capability have a minimum scale for emergence, or can architectural innovations reduce these thresholds? Are there capabilities that won't emerge regardless of scale?
Can we induce emergence? Instead of waiting for capabilities to emerge with scale, can we design training procedures that trigger specific phase transitions? This would transform emergence from mysterious to engineerable.
The Honest Conclusion
The age of asking "is emergence real?" is ending. The age of asking "what, exactly, emerges at what scales through what mechanisms?" is beginning.
The evidence points to a messy truth: some capabilities genuinely emerge through phase transitions with identifiable mechanisms (in-context learning via induction heads). Others improve continuously but appear emergent due to measurement choices (arithmetic via exact-match scoring). Still others involve complex interactions between scale, architecture, and training that we don't fully understand.
The most productive stance isn't dogmatic belief or skepticism about emergence. It's empirical mapping of which capabilities show which patterns, mechanistic investigation of why, and practical application of these insights to build better systems.
For practitioners, this means:
- Don't assume scaling automatically unlocks new capabilities
- Do expect threshold effects for specific, mechanistically-grounded abilities
- Measure carefully: metric choice shapes what you see
- Investigate mechanisms, not just behaviors
- Prepare for both continuous improvements and genuine surprises
For researchers, it means moving beyond "emergence exists/doesn't exist" to questions like:
- What mechanisms enable in-context learning?
- Why does grokking occur at specific scales?
- How do architectural choices influence emergence patterns?
- What capabilities require genuine phase transitions versus continuous refinement?
The complexity science lens doesn't resolve the emergence debate. It reveals that we've been having the wrong debate. The question isn't whether LLMs exhibit emergence; they exhibit various phenomena at various levels of description. The question is which phenomena matter for which purposes, and how we can understand them mechanistically rather than merely documenting their appearance.
That's a harder question than "does emergence exist?" It's also far more useful.
Comments and feedback
Spotted an error or have a counterpoint? Comment below. No account needed, a name is enough. Corrections and pushback are welcome.