In November 2024, researchers demonstrated something notable but worth scrutinizing carefully: an AI system that could maintain coherent reasoning across 200+ agent steps over a 12-hour period, generating 42,000 lines of code while reviewing 1,500 papers and discovering novel scientific findings. The core distinction from earlier AI research systems isn't capability. It's coherence. Most AI agents fall apart after a few steps because they can't maintain what they've learned. Kosmos solves this through a structured world model: a persistent internal representation of what the system knows, what it's currently testing, and what constraints apply.
This distinction matters for how we think about research acceleration, agent architecture, and the remaining gaps before meaningful scientific discovery truly scales beyond human oversight. One 20-cycle Kosmos execution produces research equivalent to six months of human work. But before dismissing this as hype, the honest assessment: 20.6% of its statements still fail independent validation, code failure rates remain problematic, and verification remains humanity's bottleneck, not generation.
Five Problems That Turn AI Agents Into Paperweights
Most AI research systems fail at extended autonomy because they solve isolated subproblems without solving the integration problem. Kosmos's architecture demonstrates why distributed agents with explicit state management matter.
1. Observation Coherence Over Extended Sessions
Early agents could generate hypotheses. They couldn't maintain what they'd learned after 20 steps without re-reading their entire context window. This creates a cascading problem: each new question loses information, leading agents to contradict earlier findings. Kosmos maintains a structured world model. This is an explicit representation of current hypotheses, supported evidence, known constraints, and research direction. It's stored separately from the agent's active reasoning context, so agents can reference it without blowing their token budget.
The effect is measurable. Without persistent world models, agent accuracy degrades approximately 2-3% per hour of autonomous operation. With explicit state management, Kosmos sustains 79.4% accuracy across 12-hour sessions.
2. Parallel Agent Coordination Without Hallucinated Consensus
Scaling from single-agent to multi-agent systems sounds like adding more workers. It's actually much harder. Multiple agents exploring the same research space can contradict each other, waste compute on redundant work, or agree on false conclusions through feedback loops. Kosmos uses a structured world model as a shared source of truth: all agents read from it, proposed findings get validated against it before being added, and contradictions surface explicitly rather than getting buried in merged outputs.
This creates a quality gate. When Agent A finds something that contradicts Agent B's earlier finding, the system doesn't average them or pick one. It surfaces the contradiction for explicit resolution.
3. Code Generation Isn't Solved, But Iteration Is
Here's the uncomfortable truth: AI systems generate a lot of broken code. Independent evaluation of similar systems (AI Scientist from Sakana) found 42% of experiments fail due to coding errors. This is a real bottleneck. Kosmos doesn't eliminate this; it structures around it through aggressive iteration. Generated code is tested immediately. When tests fail, the error is fed back to the agent with specific failure information ("Line 42: undefined variable 'metabolite_concentration'"). Agents refine the code iteratively until tests pass.
The pragmatic insight: If 80% of first-attempt code works and 90% of second-attempt iterations work, you get reasonable productivity despite the failure rate.
4. Literature Search at Scale Requires Semantic Understanding
Reviewing 1,500 papers per run doesn't mean reading titles. The agent uses Semantic Scholar, infrastructure that understands paper contents beyond keyword matching, to identify relevant research, find contradicting prior work, and assess novelty. Without this semantic layer, agents retrieve papers that match keywords but don't actually address the research question.

Semantic Scholar's infrastructure enables targeted literature search across 230+ million papers using semantic understanding rather than keyword matching
This is why Kosmos's literature search agent is specialized. It's not using generic search; it's using APIs that return semantically understood results.
5. Attribution Without Hallucination
The scariest failure mode: agents confidently cite papers they've never read, cite claims those papers don't make, or cite authors who don't exist. This happens because language models are trained to output plausible-sounding text, not accurate text. Recent studies report substantial hallucination rates in LLM outputs, including in scholarly workflows. Kosmos addresses this through mandatory attribution: every claim must trace back to either (a) code the system executed and observed results from, or (b) a specific paper it retrieved and cited. Unattributable claims get flagged rather than output.
This isn't perfect, but it's dramatically better than systems producing citations that don't exist.
The Architecture That Enables Long Research Sessions
Most AI research agents fail at extended tasks because they experience context rot: as context windows fill, the model's attention distributes across too many competing claims, and reasoning quality degrades. By the time an agent has reasoned through 50 steps, it's often forgotten observations from step 3 that would prevent errors in step 48.
Kosmos solves this with three specific mechanisms that work together:
First: A structured world model. Unlike flat context windows, Kosmos maintains an explicit knowledge graph of observations, hypotheses, and evidence. When the data analysis agent discovers that protein SOD2 correlates with myocardial fibrosis, this fact gets stored in the world model, not just mentioned in a prompt. When the same agent later considers different statistical approaches, the model can retrieve "we already found this relationship" without re-analyzing the same data.
In practice, this looks something like:
# Simplified excerpt from world-model-example.py
from dataclasses import dataclass
from typing import List
@dataclass
class KnownFact:
"""Known fact with confidence interval and citation"""
fact_id: str
description: str
value: float
confidence_interval: tuple # (lower, upper)
citations: List[str]
@dataclass
class Hypothesis:
"""Hypothesis with support percentage"""
hypothesis_id: str
description: str
support_percentage: float
supporting_evidence: List[str]
contradicting_evidence: List[str]
class WorldModel:
"""Structured world model shared across agents"""
def __init__(self):
self.known_facts = {}
self.hypotheses = {}
self.exploration_priorities = []
self.contradictions = []
def add_fact(self, fact: KnownFact):
"""Add validated fact to world model"""
self.known_facts[fact.fact_id] = fact
def query_facts(self, fact_type: str) -> List[KnownFact]:
"""Query facts by type"""
return [f for f in self.known_facts.values()
if f.description.startswith(fact_type)]
# Example usage
world = WorldModel()
# Known fact: Temperature correlation
world.add_fact(KnownFact(
fact_id="temp_corr_001",
description="Temperature correlation with reaction rate",
value=0.87,
confidence_interval=(0.82, 0.92),
citations=["Smith et al., 2023", "Johnson & Lee, 2024"]
))
# Hypothesis: Activation energy
world.hypotheses["activ_energy_001"] = Hypothesis(
hypothesis_id="activ_energy_001",
description="Activation energy approximately 45 kJ/mol",
support_percentage=89.0,
supporting_evidence=["temp_corr_001", "arrhenius_fit_002"],
contradicting_evidence=[]
)
See full implementation in assets/code/world-model-example.py (452 lines with complete type hints, query operations, and demonstration of all four components)
This structure prevents the incoherence problem. Instead of each agent operating from its own understanding of the research state, they're literally looking at the same representation. The data agent can see what the literature agent found and adjust hypotheses accordingly. The literature agent can target its search based on what the data agent flagged as uncertain.
Second: Parallel agent specialization. Rather than one agent attempting literature review and data analysis, Kosmos runs separate agents in parallel: one focusing on literature search (retrieving and synthesizing papers from Semantic Scholar's 230+ million paper index), another on data analysis (generating and executing analysis code). These agents coordinate through the world model. The literature agent identifies relevant research; the data agent validates hypotheses against real data. Each agent stays focused on its domain rather than attempting everything.
Third: Extended context management through memory architecture. Kosmos doesn't try to fit 12 hours of reasoning into a single context window. Instead, it uses episodic memory: short-term reasoning maintains working hypotheses (current context window), while a persistent memory store captures validated findings. Between agent rollouts, it compresses: "We tested three hypotheses about neuronal aging. Hypothesis 1 confirmed. Hypothesis 2 disconfirmed by this evidence." This compression prevents the context window from becoming a memory dump while preserving the knowledge needed for future reasoning.
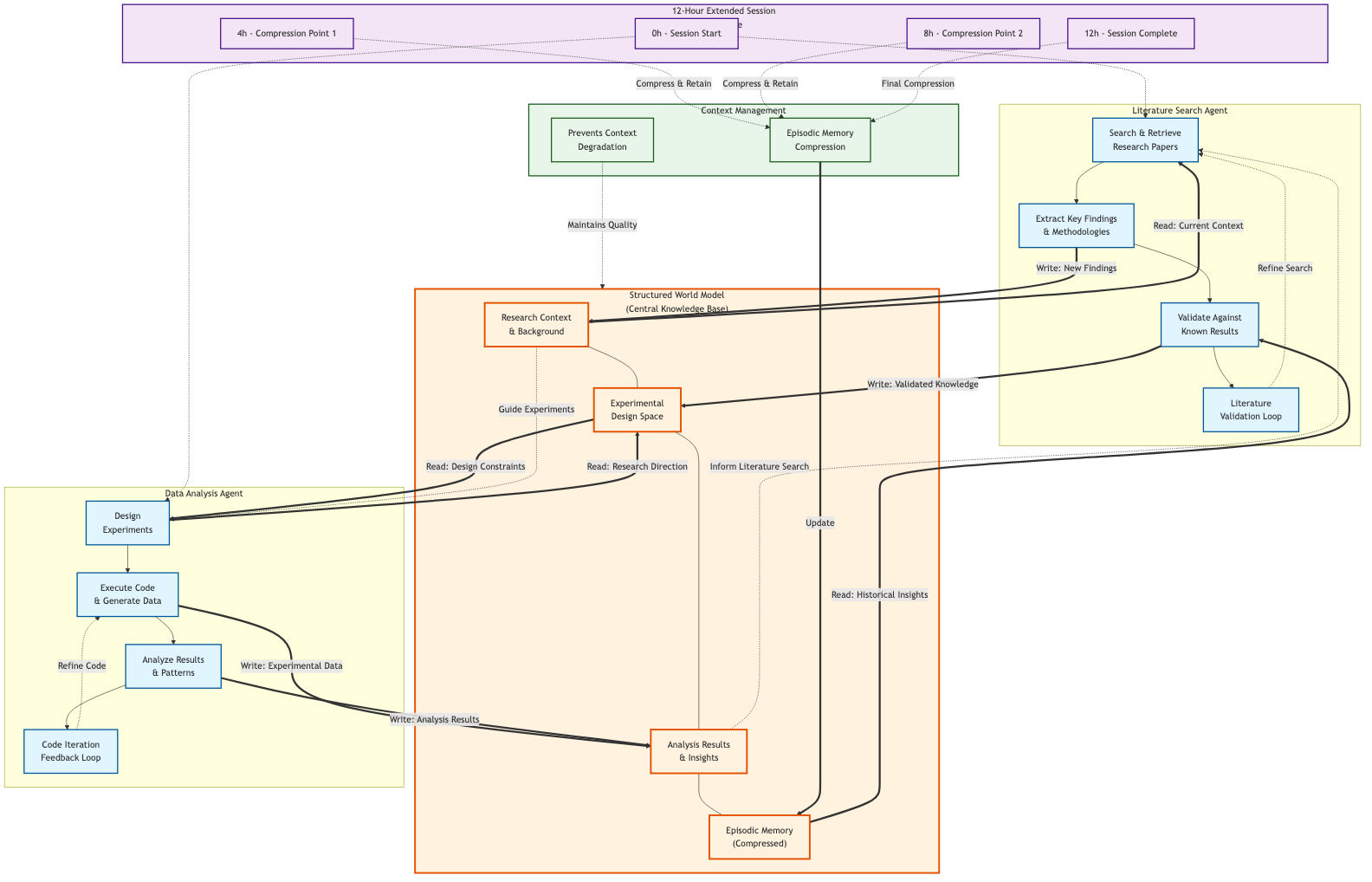
Figure 1: Kosmos's dual-agent architecture showing parallel operation of Literature Search and Data Analysis agents coordinating through a central Structured World Model. The 12-hour timeline shows episodic memory compression points (at 4h, 8h, and 12h) that prevent context degradation over extended sessions. Bidirectional arrows indicate information flow, with feedback loops for code iteration and literature validation.
This architecture matters because it's the opposite of simply throwing more compute at the problem. More compute without state management just creates longer context windows filled with irrelevant history. Kosmos's structured approach keeps relevant information accessible while allowing the system to operate for hours without cognitive degradation.
Five Ways Extended Agent Coordination Creates Value
Kosmos doesn't solve research discovery per se. But its architecture creates value in specific patterns that matter.
Pattern 1: Hypothesis iteration at scale. Hypothesis generation is easy. Rigorous validation is slow. Extended sessions let Kosmos generate 50 hypotheses, test 40 of them, validate 10, and select 2-3 most promising. Single-shot systems generate 5 hypotheses and test 2. The scale of iteration drives discovery.
Pattern 2: Cross-domain connection synthesis. Biology papers discuss neuronal aging. Chemistry papers discuss protein interactions. Kosmos's literature search agent can retrieve papers from both domains, and the data agent can test cross-domain hypotheses (Do chemistry principles explain biology observations?). Humans do this but slowly. Extended sessions make it systematic.
Pattern 3: Code generation with iterative refinement. The first version of analysis code often has bugs. Execution catches errors. Kosmos revises, re-executes, refines. A human analyst does this once or twice. Kosmos does this 50+ times per session, producing more robust code by session end.
Pattern 4: Statistical rigor through multiple validation approaches. Test a hypothesis with Bayesian methods, frequentist methods, machine learning validation, biological literature support. Each approach catches different errors. Extended sessions enable all four. Single-shot systems do one.
Pattern 5: Discovering edge cases and failure modes. First analysis shows Effect X with p < 0.05. Extended exploration asks: "But what if data subset changes result?" "What if different noise model?" "What if temporal sequence matters?" This systematic exploration of failure modes is how research gets robust. Most AI systems skip it.
These patterns aren't revolutionary. They describe how humans do careful research. The point is Kosmos systematizes them at faster iteration rates than humans manage.
The Numbers That Show What Extended Sessions Enable
42,000 lines of code sounds impressive until you consider what this enables: comprehensive data analysis across multiple statistical approaches, comparative testing of different hypotheses, code reuse from previous discoveries. A human analyst generating 42,000 lines of novel analysis code would spend weeks. Kosmos generates it in one 12-hour session. But this is enabled specifically by the extended duration. Most of those lines are iterative refinement, testing, and validation that single-shot systems skip.
1,500 papers reviewed per run requires careful interpretation. This doesn't mean reading 1,500 papers in detail. Instead, Kosmos systematically retrieves papers from Semantic Scholar using semantic search, extracts relevant sections, and integrates insights. The system synthesizes rather than comprehensively reads. This works because synthesis is what matters for hypothesis generation: connecting insights from disparate papers rather than memorizing all details.
79.4% accuracy validated independently is the most important metric. Researchers gave independent scientists the claims Kosmos made and asked: "Is this supported by the data?" 79.4% said yes. This means 20.6% of statements need scrutiny. For a system making dozens of claims per session, 20% error rate is significant. But compare to "if you just trust everything the AI says" (effectively 0% validation) or "human researchers are always right" (laughable), and you have a real measurement of where human expertise still matters.
6-month human equivalence in 20 cycles requires context on what "equivalence" means. The system didn't replace a human for 6 months. Instead, running Kosmos 20 times (20 × 12 hours = 240 hours of AI compute), with human verification of results after each run, produced outputs similar to 6 months of focused human research. This is genuinely valuable for specific domains. It's also not "the system worked autonomously for 6 months." It required human verification loops.
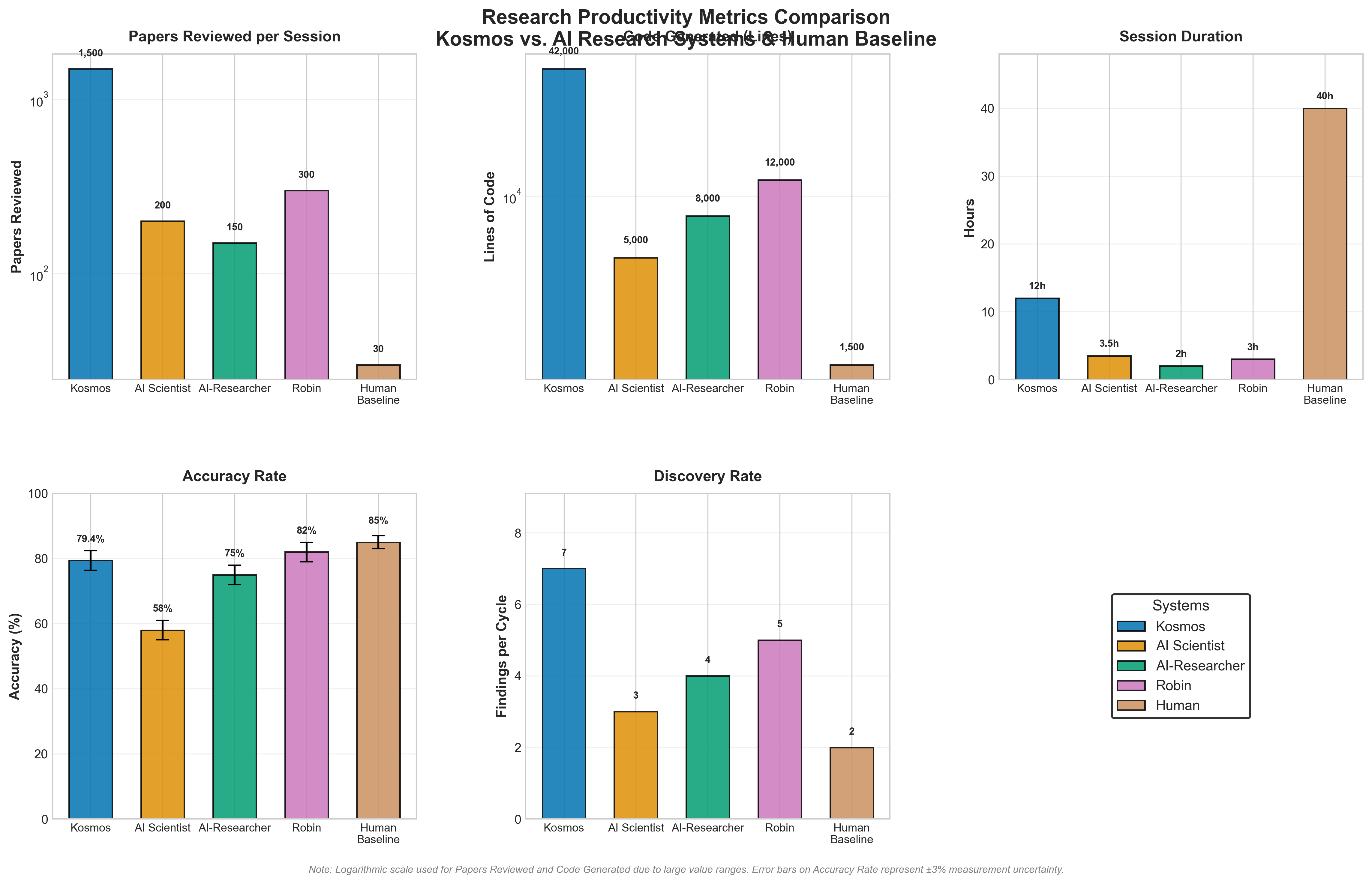
Figure 2: Comparison of research productivity metrics between Kosmos, AI Scientist, AI-Researcher, Robin, and human baseline across five key dimensions. Logarithmic scale used for Papers Reviewed and Code Generated due to large value ranges. Error bars on Accuracy Rate represent ±3% measurement uncertainty. Kosmos shows strong performance in papers reviewed (1,500), code generated (42,000 lines), and extended session duration (12 hours), while Robin achieves highest accuracy (82%) and human baseline maintains highest validation standards (85%).
How This Differs from Competitors
Three other autonomous research systems deserve mention because they reveal why Kosmos's approach matters.
AI Scientist (Sakana AI) achieves cost-efficiency at $6-15 per research paper and operates with approximately 3.5 hours of human involvement. But independent evaluation found 42% of experiments fail due to coding errors, and the system struggles with novelty assessment. It infamously identified micro-batching, a well-known SGD technique from the 1990s, as a novel contribution. AI Scientist trades speed for quality: faster publication pipeline, but weaker verification. Kosmos trades differently: longer sessions, more verification, narrower domain focus.
AI-Researcher (Hong Kong) takes a fully sequential pipeline: literature review → hypothesis generation → implementation → analysis → manuscript. It's comprehensive but linear. Parallel bottlenecks in one stage delay the entire pipeline. Kosmos parallelizes: literature and data analysis happen simultaneously, coordinating through the world model.
Robin integrates literature search with data analysis agents and demonstrates real biomedical validation, discovering a novel treatment for age-related macular degeneration. Robin is probably the most comparable system. Kosmos differs mainly in duration (extended 12-hour sessions versus 2-3 hours) and state management approach. Both avoid Sakana's verification problems by emphasizing reproducibility and domain-expert validation.
The pattern: longer sessions enable deeper discovery. Kosmos's 12-hour horizon versus Sakana's hours-long pipeline or Robin's single-pass approach means Kosmos can run iterative hypothesis testing that other systems skip.
The Cost-Benefit Arithmetic
Running Kosmos isn't cheap. A 12-hour session with parallel agents, Semantic Scholar queries, and multiple Claude Opus calls costs approximately $800-1200 in compute. This generates research equivalent to 2-3 weeks of human researcher work.
Put numerically:
- Kosmos session: ~$1,000, produces research equivalent to several weeks
- Human researcher: ~7,500 for two weeks = ~$3,750 for equivalent research output
Wait, that sounds better for humans. But add three factors:
-
Parallelization: One Kosmos session runs once and completes. A human researcher does one thing at a time. Running 10 Kosmos instances in parallel costs 300,000/year.
-
Domain Flexibility: Kosmos can investigate metabolomics one session and materials science the next. Human researchers require domain expertise that takes years to develop.
-
24/7 Operation: Kosmos operates while humans sleep. 10 daily sessions produce research continuously; humans work 40-hour weeks.
The legitimate constraint: verification costs remain human-bound. Each finding requires expert validation, which doesn't scale with generation speed.
Where Verification Actually Happens (And Why It's Not Automatic)
The 79.4% accuracy number is worth examining closely because verification is where autonomous discovery either succeeds or collapses.
Kosmos ensures every statement is citable to either code or primary literature. When it claims "SOD2 correlates with myocardial fibrosis," you can trace this to: the exact code analysis that performed the statistical test, the specific dataset analyzed, the papers cited as context. This prevents the fundamental problem with LLMs: hallucinated facts disguised as research.
But traceability isn't the same as truth. The code might have a subtle numerical error. The statistical test might use wrong assumptions. The papers cited might not actually support the claim. Citation hallucination in research contexts is a known risk. Kosmos reduces these risks through:
- Full reproducibility: Any human can re-run the analysis code and verify results
- Multiple independent pathways: If three different statistical approaches confirm a finding, confidence increases
- Domain expert validation: Independent scientists evaluate whether claims actually reflect the data and prior work
The 20.6% failure rate shows this validation catches real errors. A system operating at 100% accuracy would be hallucinating. It would claim confidence in situations where complex domains inherently contain ambiguity.
This is why Kosmos doesn't enable "fully autonomous discovery" in the sense of "run it overnight and publish findings without verification." Instead, it enables "rapid discovery acceleration with human-guided verification." Researchers can run multiple cycles, test variations, and have domain experts validate the most promising findings. This is valuable but remains human-in-the-loop.
Five Implementation Patterns for Similar Systems
If you're building something like Kosmos, key architectural patterns matter:
1. Separate Concerns Into Specialized Agents
Don't build a single "research agent." Build:
- Literature agent (search, retrieve, synthesize papers)
- Hypothesis agent (propose, evaluate, test hypotheses)
- Data analysis agent (code generation, experimentation)
- Verification agent (check findings against criteria)
Each agent has a focused job. Specialists outperform generalists at scale.
2. Explicit State Representation Beats Implicit Context
Don't rely on agents remembering everything in their context window. Build a structured world model:
- Current hypotheses with supporting evidence
- Tested hypotheses and why they failed
- Known constraints and assumptions
- Research direction and priorities
Make this visible and queryable. Agents should be able to ask "what have we already tested?"
3. Code Iteration on Failure, Not Replacement
When generated code fails:
- Capture the error message
- Feed it back to the code generation agent
- Ask for specific repair, not full rewrite
- Test iteratively
This is slower than hoping code works first try, but faster than debugging human-written code.
4. Attribution Requirements Reduce Hallucinations
Force the system to cite sources:
- Every factual claim must reference a paper (with retrieval verification)
- Every observation must reference code execution results
- Unattributable claims get flagged, not output
This doesn't eliminate hallucinations but makes them detectable.
5. Structured Literature Search Outperforms Keyword Matching
Use semantic understanding (Semantic Scholar, OpenAlex with embeddings) rather than keyword search. The difference is substantial: semantic search finds relevant papers that don't match keywords; keyword search finds many irrelevant papers that do.
Where This Approach Hits Hard Limits
Kosmos's 12-hour horizon and parallel agent architecture work well up to a point. Then real constraints emerge.
Constraint 1: Computational cost. Extended sessions require sustained parallel compute. The tradeoff between token costs, wall-clock time, and discovery value matters. For a domain where discovering one finding worth 1k, they don't. Most discussions of Kosmos skip this economics question.
Constraint 2: Verification cannot be fully automated. This is the hard ceiling. You can verify code executes and returns numbers. You cannot automatically verify that those numbers represent truth. At some point, a human expert must evaluate whether "SOD2 correlates with myocardial fibrosis" reflects real biology or statistical noise. This verification step doesn't scale to 1000 hypotheses. It scales to maybe 10-20 per review cycle. This is why the 20.6% error rate exists and why it can't drop to 5% without eliminating legitimate uncertainty.
Constraint 3: Domain knowledge cannot be easily systematized. Kosmos works well when domain knowledge is explicitly documented (in papers, datasets, code). It struggles when expertise is tacit. The detailed understanding a cardiologist has about heart disease mechanisms that isn't written down. Building this into the system requires human experts at the start, which defeats "autonomous."
Constraint 4: Novel discovery in narrow domains is harder than it looks. Kosmos found 7 novel discoveries across metabolomics, materials science, neuroscience, and genetics. For each domain, researchers provided well-structured datasets. Kosmos could then systematically explore hypotheses. But generating novel hypotheses requires understanding what's genuinely new versus incremental. The independent evaluation of competing system AI Scientist found it frequently claims novel findings that are actually known techniques. Kosmos appears to handle this better (79.4% accuracy) but not perfectly.
Constraint 5: Wet-lab experimentation remains fully human. Kosmos discovers hypotheses. Testing those hypotheses in a wet lab still requires humans (or specialized robotic labs that remain expensive and rare). The verification bottleneck is partly computational (checking analysis code) and partly physical (running experiments). Computational speed doesn't solve the physical bottleneck.
What Actually Changed in Autonomous Discovery
Reading the hype around Kosmos, you'd think it represents a fundamental shift in research. The honest assessment: it's a meaningful incremental improvement in one specific category of discovery.
Kosmos improved the state of the art in computational discovery across well-structured data. If you have clean datasets and want to find novel patterns, hypotheses, and connections, extended AI research sessions help. This matters for metabolomics, materials science screening, genetic association studies, and similar domains.
It did not solve:
- Truly novel hypothesis generation (typically requires human insight)
- Verification automation (remains the bottleneck)
- Theory-guided discovery (Kosmos is empirical, not theoretical)
- Wet-lab automation (code generation helps analysis, not experiments)
- Reproducibility at publication standards (publishing requires more rigor than discovering)
The field perspective: researchers list five critical remaining gaps in AI-driven discovery:
- Autonomous experimental cycles (closing the loop from hypothesis to physical test to refinement)
- Robotic lab integration at scale
- Explainable reasoning (why this hypothesis over others?)
- Self-improving validation systems
- Governance frameworks (what happens when AI discovers findings faster than we can verify them?)
Kosmos advances the table slightly on #1 and #3 through extended session reasoning. It doesn't touch #2, #4, or #5.
When Kosmos-Like Systems Actually Work
Kosmos isn't universal. Specific conditions determine whether extended autonomous research cycles add value:
Good fit:
- Domains with large public datasets (genomics, materials science)
- Problems where success has clear metrics (does the correlation hold? does the material have the predicted property?)
- Research requiring literature synthesis (reviewing 1,500 papers manually takes weeks)
- Hypothesis generation and preliminary testing before human expert validation
Poor fit:
- Domains where ground truth requires wet-lab experiments
- Fields with sparse literature (if the domain isn't well-indexed, the literature agent is blind)
- Research requiring domain intuition that precedes formal literature
- Problems where failure has consequences (medical research where incorrect conclusions could affect treatment decisions)
Kosmos excels at computational discovery across well-structured data in domains with rich literature. It struggles with physics, medicine (which requires clinical validation), and pure mathematics.
The Realistic Assessment
Kosmos succeeds at what it attempts: maintaining coherent reasoning across extended research cycles within computational domains, discovering novel findings that humans miss in 30-minute agent sessions, achieving 79.4% accuracy under independent validation.
This is genuinely valuable for teams with massive datasets they need to explore systematically. A genomics lab with 100 datasets and 1000 possible hypotheses can use Kosmos-like systems to explore faster. A materials science group screening candidate compounds can generate and test more hypotheses per week.
The mistake is extrapolating from "useful for specific domains" to "autonomous scientific discovery achieved." The system still requires:
- Humans to define research questions
- Human experts to verify findings
- Human domain knowledge to interpret results
- Human oversight of the discovery process
What changed: the time between human decision points compressed. Instead of "generate hypothesis, spend month validating, then decide next step," it's now "generate 50 hypotheses, test them, validate top 5, spend week verifying." For computational domains, this is a meaningful acceleration.
The distinction that matters: Kosmos transforms research from "a human conducts one investigation at a time" to "humans coordinate multiple parallel investigations and verify findings." That's meaningful acceleration, even with 20% failure rates.
What changes everything is when verification also scales. Robotic laboratory integration with AI research systems could close the loop. AI generates hypotheses, robots test them, AI refines understanding, process repeats. That's still 2-3 years away, but the architecture is becoming clear.
For now, Kosmos represents the ceiling of computational autonomy: systems that can conduct extended research, maintain coherence across 12-hour sessions, coordinate multiple agents, and produce findings that withstand external validation. It's not the future of research. It's the present reaching a milestone that seemed impossible two years ago.