Have We Reached Human-Level AGI? What the Evidence Actually Shows
"We're approaching AGI." This phrase echoes from Silicon Valley boardrooms and academic conferences alike. But listen closer and you notice something peculiar: smart people disagree dramatically about whether we're five years away, or fifty. The disagreement itself is the story. It reveals less about how close we are to human-level artificial general intelligence, and more about how uncertain our definitions really are.
Last week, a tech executive declared current systems "approaching AGI." The same week, an AI researcher called them "nowhere near" true general intelligence. Both referenced the same technology.1 So what's really happening?
The Definitional Crisis
You'd expect experts to agree on what AGI is. They don't. Not even close.
OpenAI defines AGI as "highly autonomous systems that outperform humans at most economically valuable work."2 Google DeepMind proposes it's a system that's "both general-purpose and high-achieving."3 The ARC Prize Foundation says AGI is "a system that can efficiently acquire new skills outside of its training data."4
These aren't subtle differences. They would classify the same AI system differently depending on which definition you use.
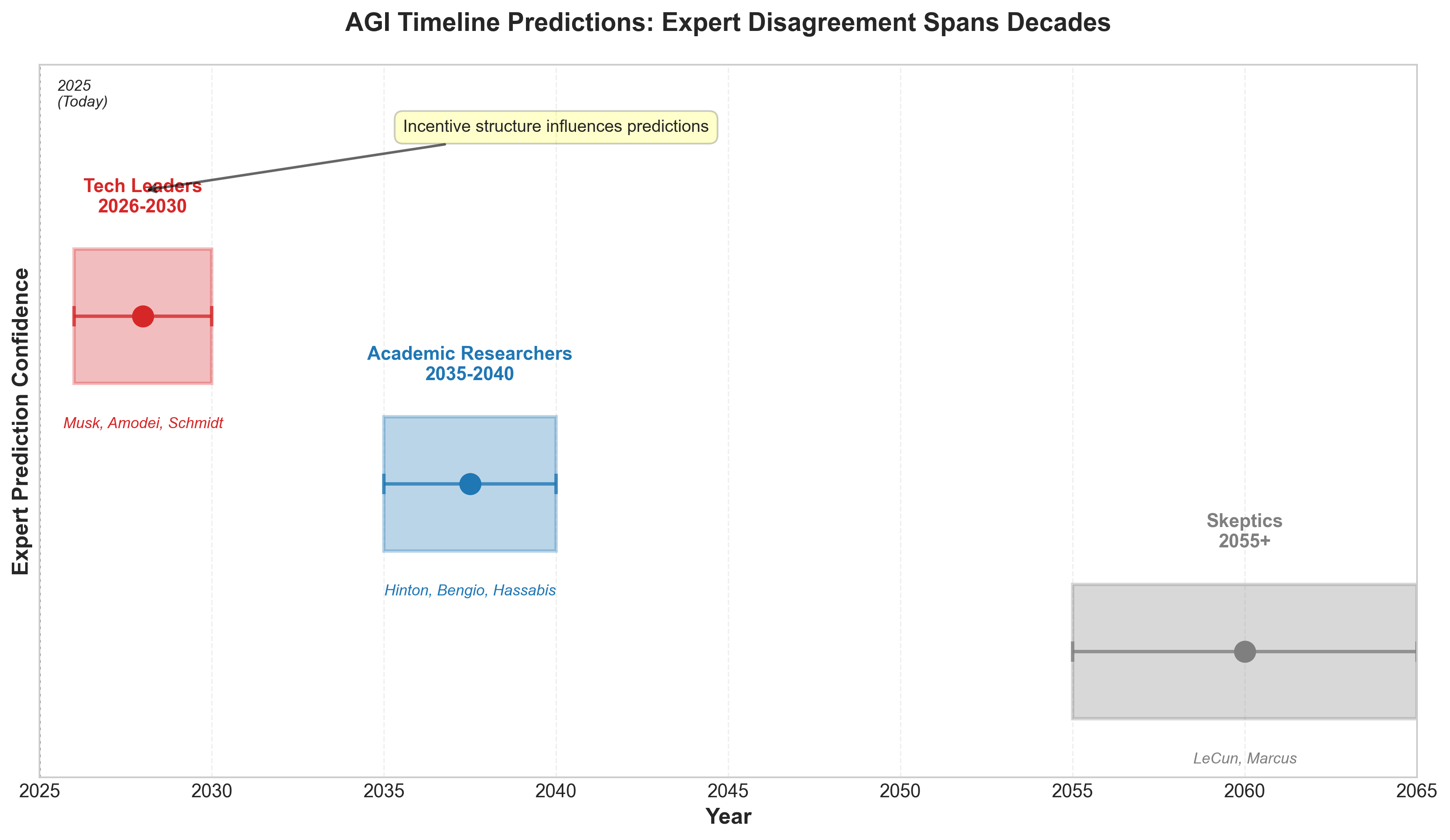 Figure 1: Expert AGI timeline predictions show dramatic disagreement, clustered into three groups spanning 40+ years. Tech leaders predict 2026-2030, academic researchers 2035-2040, and skeptics 2055+.
Figure 1: Expert AGI timeline predictions show dramatic disagreement, clustered into three groups spanning 40+ years. Tech leaders predict 2026-2030, academic researchers 2035-2040, and skeptics 2055+.
UC Berkeley cognitive scientist Alison Gopnik goes further, questioning whether "general intelligence" is even a meaningful concept. "There's no such thing as general intelligence, artificial or natural," she argues.5 Even defining what we're trying to measure raises philosophical questions that researchers haven't resolved.
This definitional chaos isn't a bug; it's a feature of the current moment. Tech leaders prefer broader definitions that let them claim progress sooner. Skeptics prefer stricter definitions that highlight remaining gaps.6 Everyone can point to evidence supporting their position because they're measuring different things.
Current State: Impressive Within Boundaries
Before examining limitations, credit the genuine accomplishments. The progress is real.
GPT-4 passes the bar exam, writes coherent essays, explains complex concepts, and generates working code.7 Systems now surpass human PhDs at difficult scientific reasoning questions.8 On traditional knowledge benchmarks like MMLU (testing facts across 57 academic subjects), leading systems score 88-90%, approaching and sometimes exceeding human performance.9
The acceleration from GPT-4 to more recent models shows measurable progress. Using a cognitive ability framework, researchers scored GPT-4 at 27% and later models at 57% toward AGI thresholds.10 Visual reasoning improved from 43.8% to 70.8%, approaching human performance of 88.9%.11
But here's the crucial distinction: all current systems are classified as "narrow AI," not general AI.12 The difference matters. Narrow AI excels at specific domains. General AI would transfer learning across domains, solve novel problems, and adapt continuously, just as humans do.
The Evidence Against: Where Systems Break Down
The evidence of narrow limitations is concrete and measurable.
Consider the ARC-AGI benchmark. Created by François Chollet, it measures something traditional benchmarks miss: fluid intelligence, the ability to solve genuinely novel problems with minimal data.13 Unlike MMLU, which tests accumulated knowledge, ARC-AGI presents visual puzzles designed to be "easy for humans, hard for AI."14
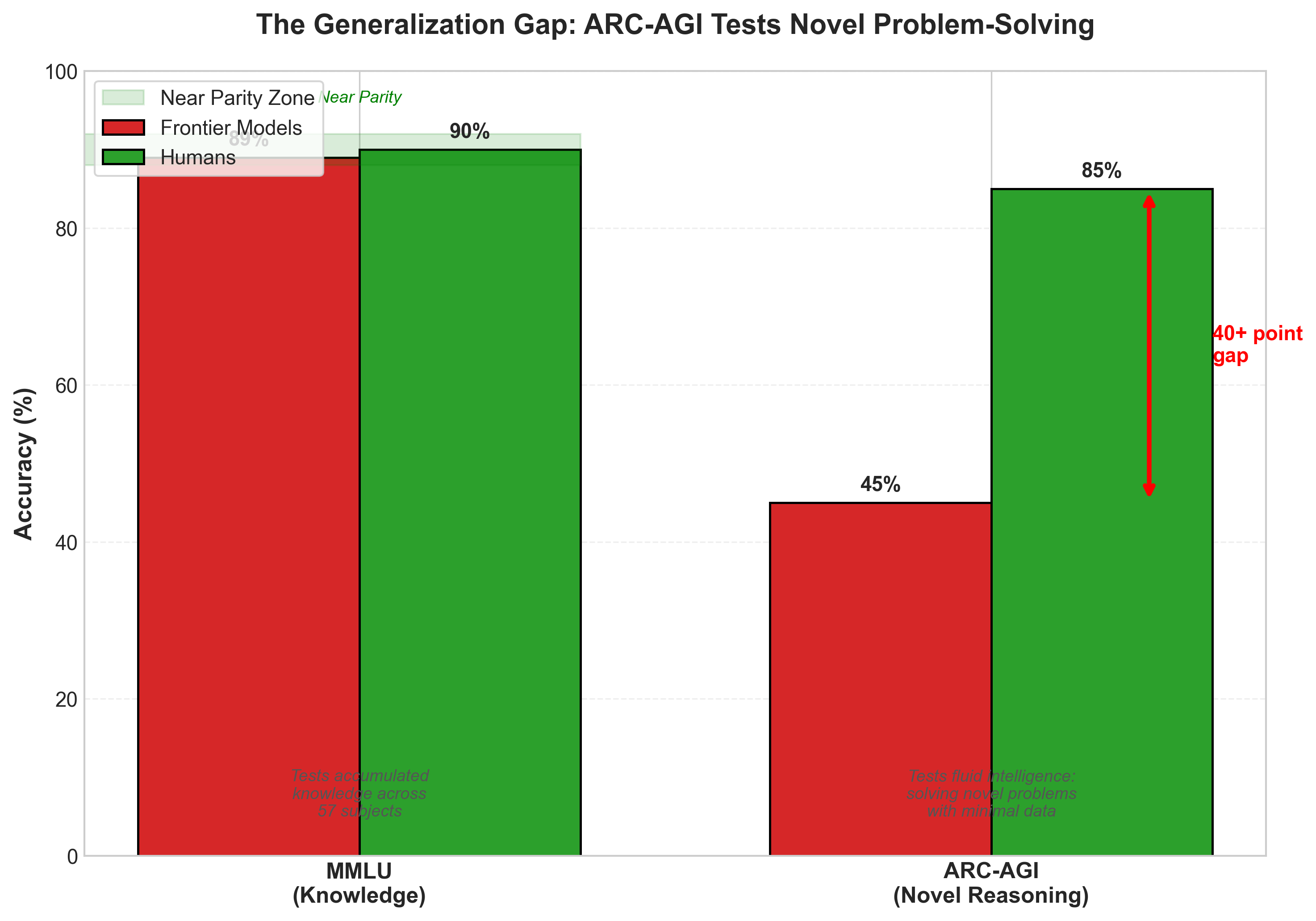 Figure 2: The Generalization Gap. Models achieve near-parity on MMLU (knowledge) but show a 40+ point gap on ARC-AGI (novel reasoning), revealing the difference between memorization and genuine problem-solving.
Figure 2: The Generalization Gap. Models achieve near-parity on MMLU (knowledge) but show a 40+ point gap on ARC-AGI (novel reasoning), revealing the difference between memorization and genuine problem-solving.
Current frontier models score below 50% on ARC-AGI. Humans score 85% and above.15 That's a 35-plus percentage point gap. The \$1 million ARC Prize for achieving 85% accuracy remains unclaimed after six years of attempts.16 If AGI were truly achieved, this would be trivial. It's not.
Even basic tasks break on unexpected inputs. Despite handling complex scientific reasoning, systems miscount letters in a word or make elementary logical errors on unfamiliar variations of simple problems.17 Researchers call this "brittleness": systems fail on trivial modifications of tasks they nominally mastered.18
Performance vs. Competence: The Critical Distinction
Current AI systems excel at narrow domains with well-defined tasks. But excellence at benchmarks doesn't equal general capability. Researchers describe this as the "performance vs. competence" gap: a system might score 95% on an exam while lacking fundamental understanding.19
Consider language translation. Modern systems perform remarkably well. But they're not understanding meaning; they're pattern-matching at scale. Prove this by asking a translation system to "translate this sentence but keep the grammar errors intact" or "translate in a way that preserves the original author's sarcasm." Suddenly performance collapses.20 The system wasn't understanding language; it was statistically predicting likely translations.
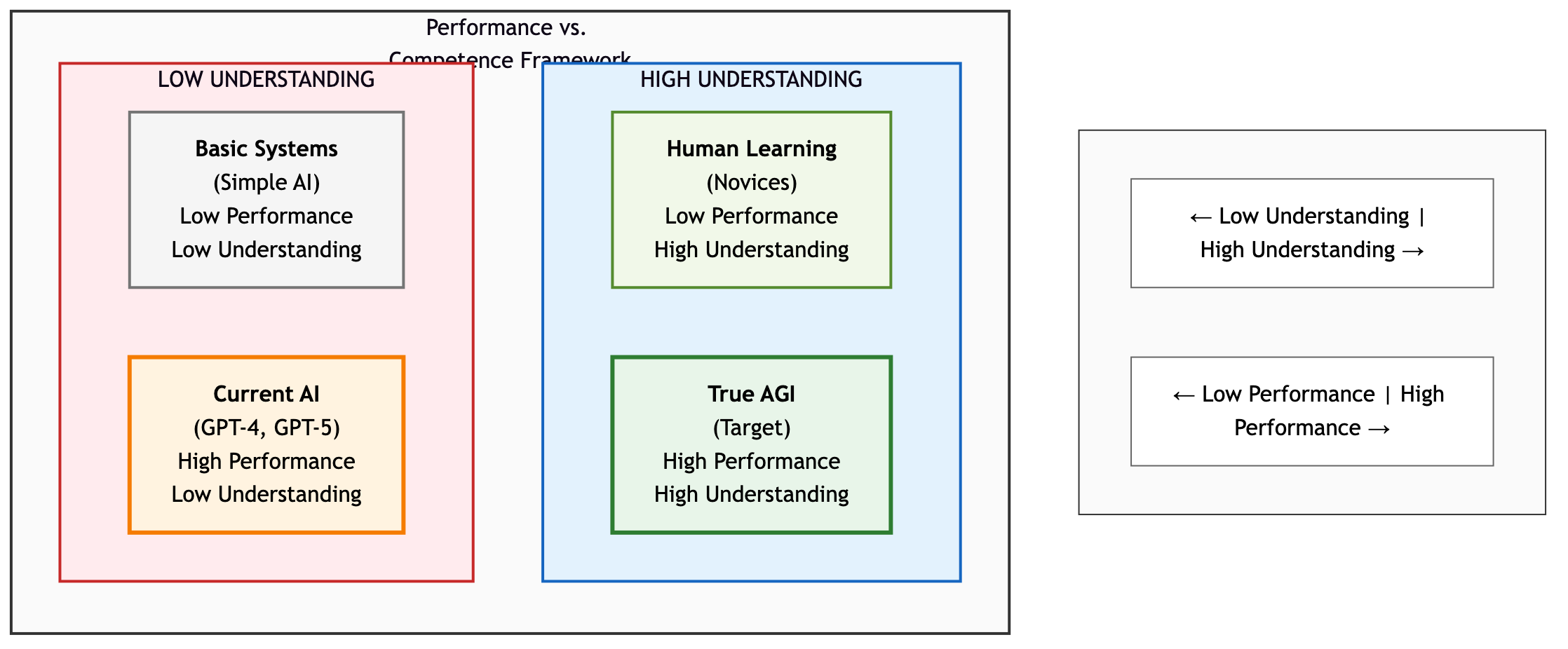 Figure 3: Performance vs. Competence Matrix. Current AI systems occupy the "high performance, low understanding" quadrant, demonstrating that benchmark scores don't equal genuine comprehension.
Figure 3: Performance vs. Competence Matrix. Current AI systems occupy the "high performance, low understanding" quadrant, demonstrating that benchmark scores don't equal genuine comprehension.
This distinction is crucial for the AGI question. We may have systems that perform at superhuman levels on narrow, well-defined tasks while remaining fundamentally incompetent at genuine adaptation.
The Hallucination Paradox
You'd expect that larger, more capable models would hallucinate less. They don't. This is the opposite of what you'd expect if scaling toward AGI.
GPT-4o shows a 16% hallucination rate, while the more recent o1-mini reaches 48%, and o3 hits 33%.21 As systems scale, they confabulate more, not less. This suggests an architectural problem, not an engineering one; something fundamental about how these systems work, not merely how we train them.22
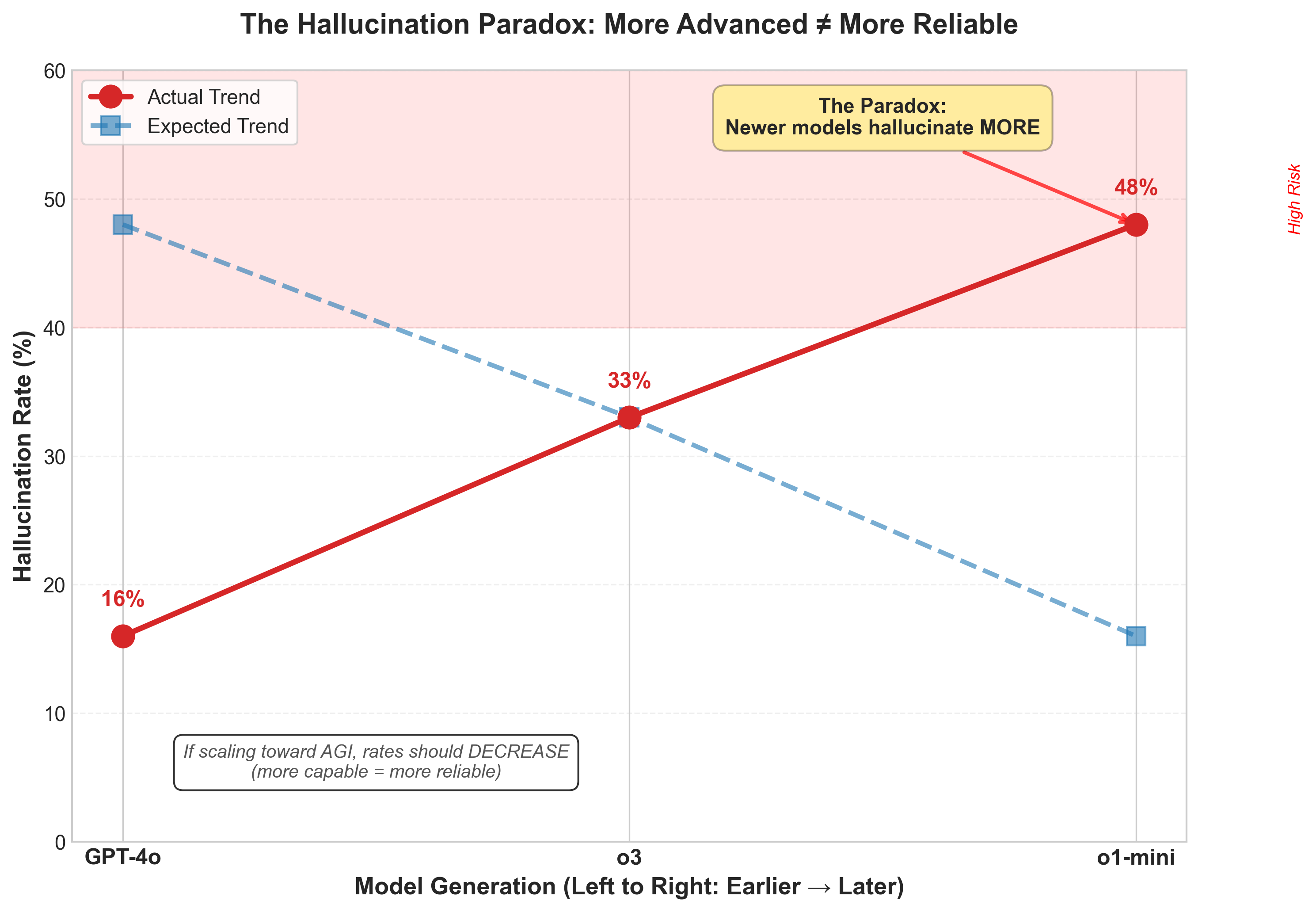 Figure 4: The Hallucination Paradox. Instead of decreasing with model sophistication, hallucination rates increase, suggesting fundamental architectural limitations rather than merely engineering challenges.
Figure 4: The Hallucination Paradox. Instead of decreasing with model sophistication, hallucination rates increase, suggesting fundamental architectural limitations rather than merely engineering challenges.
Former OpenAI Chief Scientist Ilya Sutskever predicted an "end to pre-training scaling," a ceiling where throwing more compute at the same approach yields diminishing returns.23 The hallucination data supports this: we're hitting architectural limits, not just engineering challenges.
Expert Disagreement: Following the Incentives
When researchers attempt to predict when AGI arrives, the disagreement spans decades.
Tech entrepreneurs are most optimistic. Elon Musk, Dario Amodei, and Eric Schmidt predict 2026-2027.24 Their proximity to cutting-edge systems and confidence in scaling trajectories drive these timelines. But there's an unspoken incentive structure: shorter timelines drive investment hype, stock prices, and recruitment talent.25
Academic researchers typically predict 2040, a full decade or more later.26 Geoffrey Hinton projects 2025-2030, but he's among the more bullish academics. Yoshua Bengio and Yann LeCun expect 2032-2040.27 Skeptics like Gary Marcus argue current approaches are insufficient and AGI might require 2060 or never be achieved this way at all.28
Why such divergence? Three factors:
Different definitions. "We can do what humans do in many tasks" arrives sooner than "we truly understand and reason, not just pattern-match."29
Different incentives. Tech leaders benefit from shorter timelines. Academics have reputational risk from overestimating.30
Historical pattern recognition. AI has repeatedly overestimated progress. The 1956 Dartmouth Summer promised human-level AI within a generation; the 1980s saw an AI winter from failed predictions.31 Academics remember this history. Tech leaders often don't dwell on it.
What AGI Actually Requires
Before declaring victory, it's worth asking what would genuinely constitute general intelligence versus impressively narrow AI.
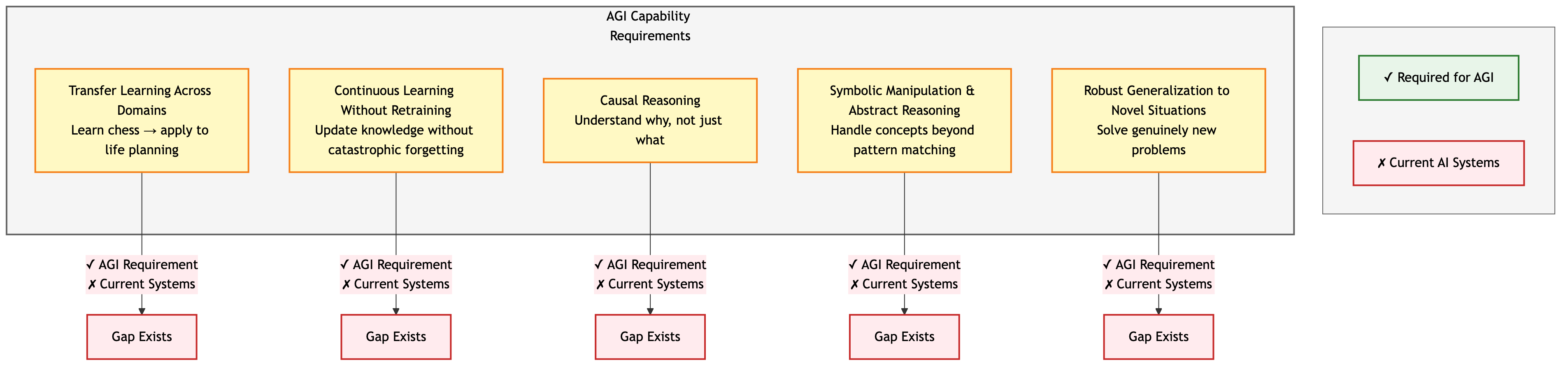 Figure 5: AGI Capability Requirements. Current systems lack all five key capabilities required for genuine general intelligence: transfer learning, continuous learning, causal reasoning, symbolic manipulation, and robust generalization.
Figure 5: AGI Capability Requirements. Current systems lack all five key capabilities required for genuine general intelligence: transfer learning, continuous learning, causal reasoning, symbolic manipulation, and robust generalization.
A true AGI would need to:
- Solve genuinely novel problems outside its training domain without retraining
- Transfer learning from one context to another (as humans learn that planning for chess helps planning for life)
- Reason symbolically about abstract concepts, not just pattern-match
- Learn continuously, incorporating new information without catastrophic forgetting
- Understand causality: why something happened, not just that it did32
Current systems fall short on all of these.33 They're exceptional pattern matchers with genuinely impressive capabilities in their domain. They're not universal problem solvers.
There's also the roboticist's perspective, often overlooked in discussions focused on language and reasoning. Most jobs with genuine economic value require physical dexterity and embodied understanding of the world: building, repairing, adapting to spatial constraints.34 Current AI has made minimal progress here. If AGI requires solving practical problems in physical reality, not just text manipulation, that's an additional major barrier we haven't overcome.
The Acceleration Is Real, The Outcome Uncertain
Exponential scaling is real. Effective compute, the combination of hardware improvements and algorithmic efficiency, is growing approximately 12 times annually, far faster than Moore's Law's historical 2x every two years.35 This accelerating compute enables increasingly capable models.
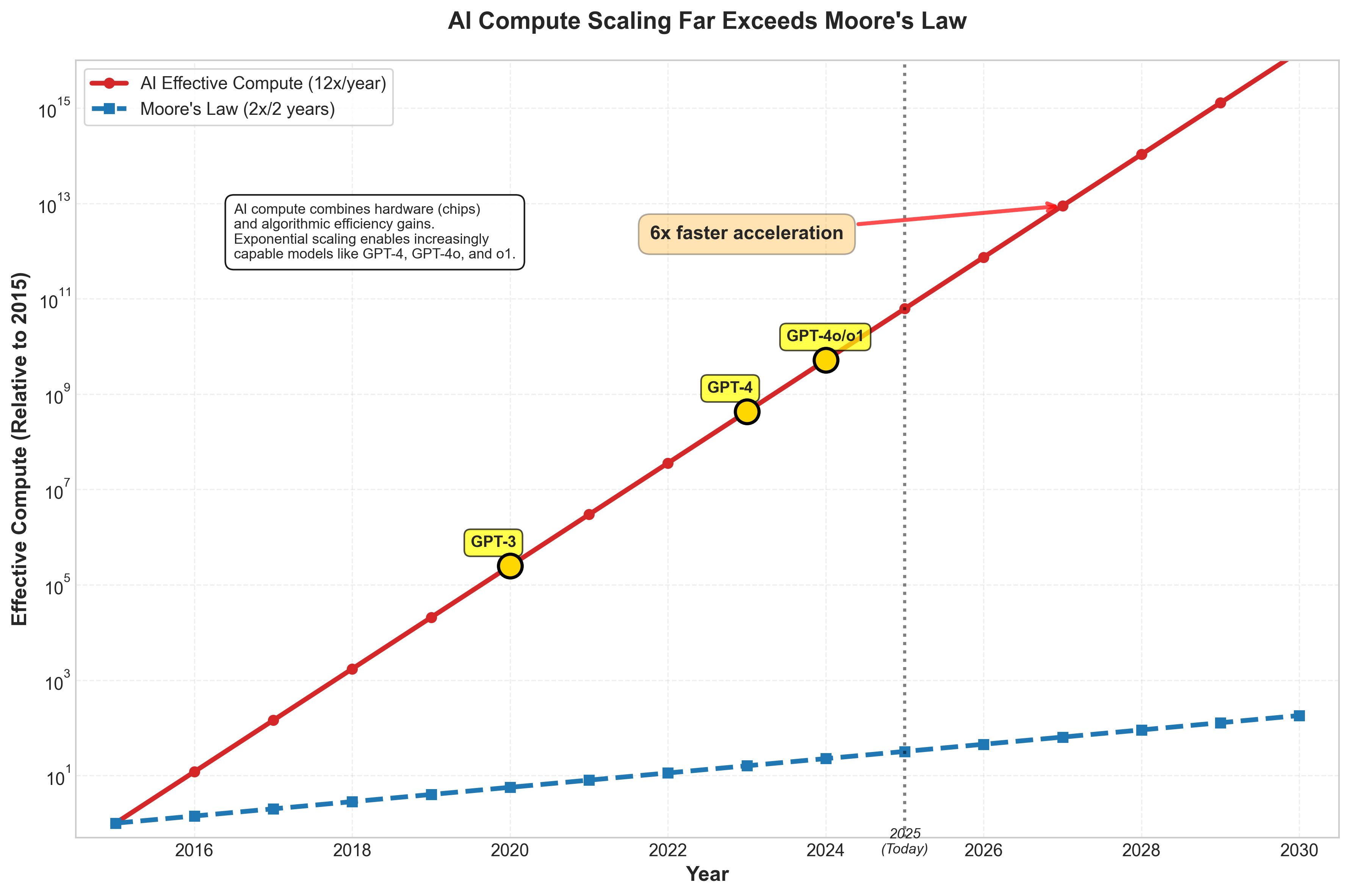 Figure 6: AI Compute Scaling Far Exceeds Moore's Law. AI effective compute grows 12x annually (6x faster than Moore's Law), with clear acceleration milestones at GPT-3, GPT-4, and subsequent model releases.
Figure 6: AI Compute Scaling Far Exceeds Moore's Law. AI effective compute grows 12x annually (6x faster than Moore's Law), with clear acceleration milestones at GPT-3, GPT-4, and subsequent model releases.
Between GPT-4 and more recent models, performance on cognitive tasks doubled.36 The timeline for task complexity keeps compressing: problems requiring seconds of reasoning in 2020, hours of reasoning by 2024, and projected to handle weeks-long reasoning chains by 2028.37 This isn't just minor tweaking; it's fundamental capability growth.
The financial feasibility exists. Training the next generation of models (GPT-6 and beyond) would cost around \100 billion annually in AI infrastructure.38 The bottleneck isn't money anymore. It's data and algorithmic breakthroughs.
Honest Assessment: Watch the Evidence
Have we achieved human-level AGI? No, not by any rigorous definition. The evidence is concrete: ARC-AGI performance gaps, hallucination increases despite scaling, narrow domain dependency, and the \$1 million prize that remains unsolved.39
Are we making impressive progress? Absolutely yes. Exponential scaling is real. Breakthrough capabilities in reasoning are real. The trend toward more general capabilities is real, even if we haven't crossed the finish line.40
Is near-term AGI plausible? It depends who you ask. You'll get answers ranging from "likely by 2027" to "unlikely within 50 years."41 The disagreement itself is honest. We're in genuinely uncertain territory.
Rather than asking "Have we achieved AGI?", which invites yes-or-no thinking that papers over nuance, the better questions are: Which human capabilities has AI matched? Which remain far behind? What would closing those gaps require, and how long might it take?
This framing acknowledges that current systems are incomparable to human intelligence in some ways and superhuman in others. The meaningful conversation isn't whether we've hit an arbitrary finish line. It's tracking which specific capabilities are developing, which remain stubbornly difficult, and whether the architectural limitations we're seeing are solvable through continued scaling or require fundamental rethinking.
We're in the middle of a genuinely interesting inflection point in AI development. Declaring victory prematurely closes that conversation. So does dismissing all progress as hype. The evidence is complex enough to justify careful attention to both the real breakthroughs and the real limitations.
The evidence will speak louder than any proclamation. Watch whether the next generation of systems breaks through ARC-AGI. Watch whether hallucinations decrease or increase. Watch whether transfer learning becomes possible. Until then, healthy skepticism toward AGI claims remains justified, not because the progress isn't real, but because the remaining gaps are substantial and their closure remains genuinely uncertain.
References
Footnotes
-
Expert Timeline Predictions (2025). Tech executives and AI researchers give contradictory assessments of the same systems. https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Scientific American (2024-2025). OpenAI's definition of AGI as "highly autonomous systems that outperform humans at most economically valuable work." https://www.scientificamerican.com/article/what-does-artificial-general-intelligence-actually-mean/ ↩
-
Scientific American (2024-2025). Google DeepMind's AGI definition. https://www.scientificamerican.com/article/what-does-artificial-general-intelligence-actually-mean/ ↩
-
ARC Prize Foundation (2025). "AGI is a system that can efficiently acquire new skills outside of its training data." https://arcprize.org/arc-agi ↩
-
Scientific American (2024-2025). Alison Gopnik quote: "There's no such thing as general intelligence, artificial or natural." https://www.scientificamerican.com/article/what-does-artificial-general-intelligence-actually-mean/ ↩
-
Brookings Institution (2023). Analysis of definitional weaponization in AGI claims. https://www.brookings.edu/articles/how-close-are-we-to-ai-that-surpasses-human-intelligence/ ↩
-
Brookings Institution (2023). Documentation of GPT-4's capabilities across multiple task types. https://www.brookings.edu/articles/how-close-are-we-to-ai-that-surpasses-human-intelligence/ ↩
-
80,000 Hours (2025). "Models now surpass human PhDs at difficult scientific reasoning questions." https://80000hours.org/agi/guide/when-will-agi-arrive/ ↩
-
AI Frontiers (2025). MMLU benchmark scores for leading systems. https://ai-frontiers.org/articles/agis-last-bottlenecks ↩
-
AI Frontiers (2025). "GPT-4 achieved 27%, while later models reached 57% on AGI cognitive ability framework." https://ai-frontiers.org/articles/agis-last-bottlenecks ↩
-
AI Frontiers (2025). Visual reasoning improvement metrics. https://ai-frontiers.org/articles/agis-last-bottlenecks ↩
-
Narrow AI vs. General AI (2024-2025). "All publicly available AI systems are categorized under narrow AI." https://www.geeksforgeeks.org/difference-between-narrow-ai-and-general-ai/ ↩
-
ARC Prize Foundation (2025). Description of ARC-AGI benchmark measuring fluid intelligence. https://arcprize.org/arc-agi ↩
-
ARC Prize Foundation (2025). Design philosophy of ARC-AGI puzzles. https://arcprize.org/arc-agi ↩
-
ARC Prize Foundation (2025). "Top frontier models score below 50% on ARC-AGI, while humans score 85%+." https://arcprize.org/arc-agi ↩
-
ARC Prize Foundation (2025). "\$1 million ARC Prize remains unsolved. If AGI were achieved, this would be trivial." https://arcprize.org/arc-agi ↩
-
American Prospect (2025). "Elementary failures: Systems miscounting letters despite handling complex logic." https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
American Prospect (2025). Description of brittleness in AI systems. https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
Brookings Institution (2023). Performance vs. competence distinction in AI systems. https://www.brookings.edu/articles/how-close-are-we-to-ai-that-surpasses-human-intelligence/ ↩
-
AI Frontiers (2025). Translation task failures demonstrating lack of true understanding. https://ai-frontiers.org/articles/agis-last-bottlenecks ↩
-
American Prospect (2025). "Hallucinations: GPT-4o 16%, o3 33%, o1-mini 48%." https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
American Prospect (2025). Analysis of hallucination as architectural problem. https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
American Prospect (2025). Former OpenAI Chief Scientist predicted "end of pre-training scaling." https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
Expert Timeline Predictions (2025). "Elon Musk: 2026; Dario Amodei: 2026; Eric Schmidt: 3-5 years (April 2025)." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Expert Timeline Predictions (2025). "Tech leaders benefit from shorter timelines (investment hype); academics have reputational risks." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Expert Timeline Predictions (2025). "Academic researchers typically predict AGI around 2040 (50% probability)." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Expert Timeline Predictions (2025). "Yoshua Bengio: 2032-2040; Yann LeCun: 2035-2040; Geoffrey Hinton: 2025-2030." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
American Prospect (2025). Gary Marcus argues current approaches are insufficient and AGI might require decades or be impossible this way. https://prospect.org/economy/2025-09-04-what-if-theres-no-agi ↩
-
Expert Timeline Predictions (2025). "Different AGI definitions drive different timeline predictions." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Expert Timeline Predictions (2025). "Academics have reputational risk from overestimation; tech leaders have investment incentives." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Expert Timeline Predictions (2025). "Historical pattern: AI repeatedly overestimated progress (1956, 1980s AI winter)." https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩
-
Lumenova (2025). "True AGI requires: continuous learning, autonomy, metacognition, novel discovery, symbolic reasoning, causal understanding." https://www.lumenova.ai/blog/artificial-general-intelligence-measuring-agi/ ↩
-
Narrow AI vs. General AI (2024-2025). Current systems cannot solve novel problems outside training domain or transfer learning between contexts. https://www.geeksforgeeks.org/difference-between-narrow-ai-and-general-ai/ ↩
-
Brookings Institution (2023). "Most common U.S. jobs require manual dexterity far beyond current AI robotics capabilities." https://www.brookings.edu/articles/how-close-are-we-to-ai-that-surpasses-human-intelligence/ ↩
-
80,000 Hours (2025). "Training compute: 4x per year; algorithmic efficiency: 10x per 2 years; combined 12x annually." https://80000hours.org/agi/guide/when-will-agi-arrive/ ↩
-
AI Frontiers (2025). Performance doubling on cognitive tasks between GPT-4 and more recent models. https://ai-frontiers.org/articles/agis-last-bottlenecks ↩
-
80,000 Hours (2025). "Task complexity increasing from seconds (2020) → hours (2024) → weeks (projected 2028)." https://80000hours.org/agi/guide/when-will-agi-arrive/ ↩
-
80,000 Hours (2025). "GPT-6 training: ~\100B+ annually on chips." https://80000hours.org/agi/guide/when-will-agi-arrive/ ↩
-
ARC Prize Foundation (2025). Multiple evidence sources: ARC-AGI below 50%, hallucination increases, domain dependency, unsolved prize. https://arcprize.org/arc-agi ↩
-
80,000 Hours (2025). Multiple sources confirm exponential scaling, reasoning breakthroughs, and trend toward more general capabilities. https://80000hours.org/agi/guide/when-will-agi-arrive/ ↩
-
Expert Timeline Predictions (2025). Expert predictions range from 2026 to 2060+, reflecting genuine uncertainty. https://research.aimultiple.com/artificial-general-intelligence-singularity-timing/ ↩