DeepAgent: Teaching AI Agents to Remember and Learn
The gap between research papers and production AI agents is often measured in disappointment. Researchers demonstrate impressive capabilities in controlled settings while developers struggle with agents that forget what they were doing, fail at multi-step tasks, and barely handle a dozen tools without making mistakes.
A new paper from Renmin University of China, DeepAgent, addresses these problems with two innovations: a brain-inspired memory system that automatically compresses long interactions, and a reinforcement learning approach that teaches agents which tools to use without copying human examples. The system scales from handling tens of tools to managing over 16,000, maintaining performance across eight different benchmarks.
This post explains what makes DeepAgent noteworthy for developers: autonomous memory folding that compresses interaction history into structured memories, and ToolPO (Tool Policy Optimization), a reinforcement learning approach that teaches agents which tools to use through experience rather than examples alone.
What AI Agents Actually Do
Before exploring DeepAgent's innovations, understanding what AI agents are matters.
An AI agent is a system built around a large language model that can autonomously work toward goals by reasoning about problems and taking actions. Unlike a chatbot that just responds to messages, agents use external tools—calling APIs, searching databases, running calculations—to accomplish tasks in the real world. (For more on AI agent architectures, see our post on ReasoningBank.)
The dominant pattern for modern agents is ReAct (Reasoning and Acting), introduced in a 2023 research paper. ReAct agents operate in a loop:
- Thought: The agent reasons about what to do next
- Action: The agent uses a tool or performs an operation
- Observation: The agent receives feedback from that action
- Repeat: The cycle continues until the task completes
This mirrors how humans solve complex problems—we think, try something, see what happens, think again, and iterate.
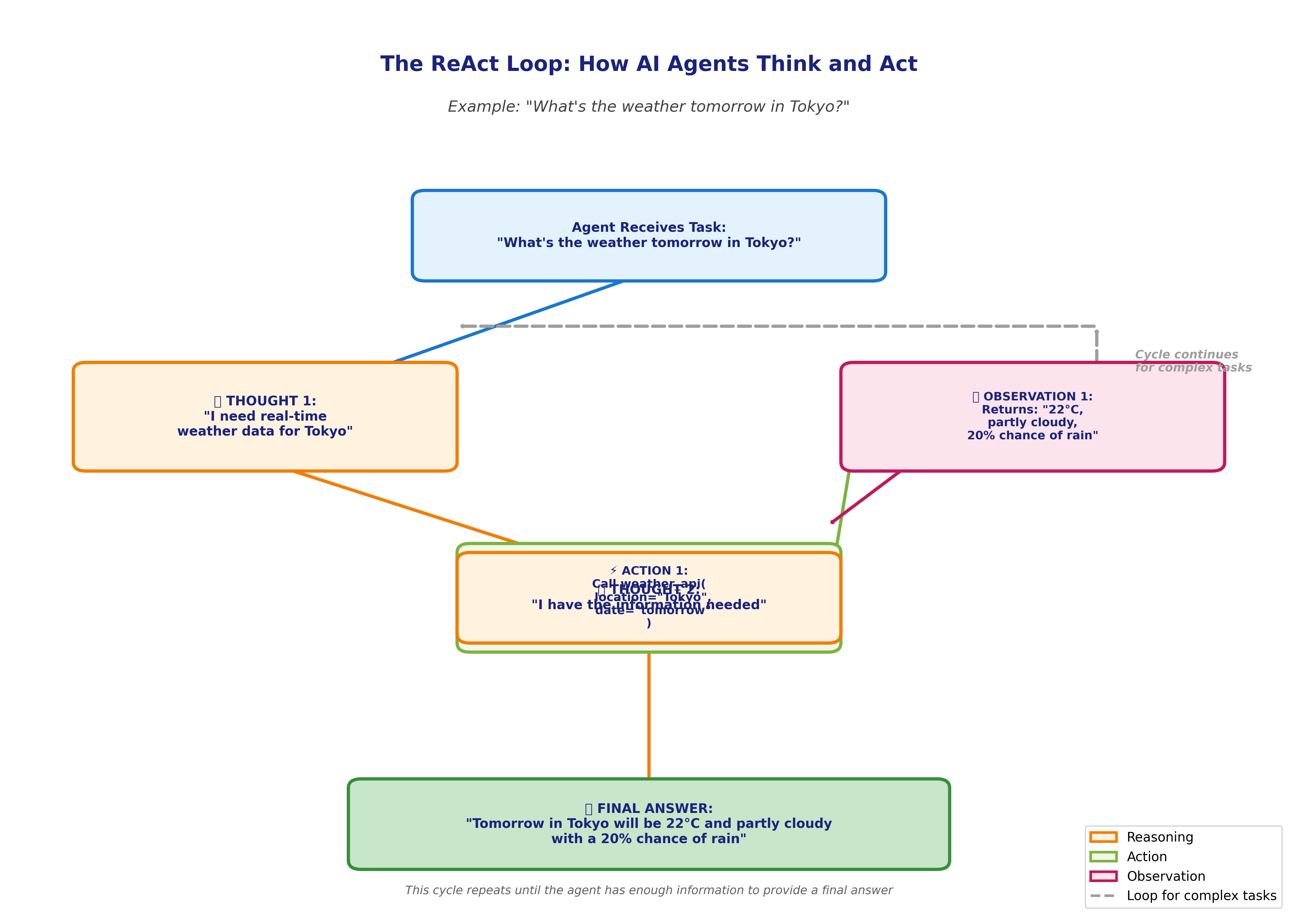 Figure 1: The ReAct Loop showing how AI agents alternate between reasoning (Thought), taking actions (Action), and processing results (Observation).
Figure 1: The ReAct Loop showing how AI agents alternate between reasoning (Thought), taking actions (Action), and processing results (Observation).
An example helps clarify this. Imagine you're asking an agent: "What's the weather tomorrow in Tokyo?"
Thought 1: "I need real-time weather data for Tokyo" Action 1: Call weather API with location="Tokyo", date="tomorrow" Observation 1: Returns "22°C, partly cloudy, 20% chance of rain" Thought 2: "I have the information needed to answer" Final Answer: "Tomorrow in Tokyo will be 22°C and partly cloudy with a 20% chance of rain"
The agent didn't just guess based on training data—it reasoned about what information it needed, used a tool to get that information, and formulated an accurate answer.
The Memory Problem: When Agents Forget
ReAct agents work well for simple tasks, but longer operations expose a critical limitation: context windows fill up.
Every LLM has a finite context window—the amount of text it can process at once. Even models with 200,000+ token windows eventually run out of space during extended tasks. Research from Anthropic reveals an additional problem called "context rot": as the number of tokens increases, the model's ability to accurately recall information from that context decreases.
Consider an agent debugging a complex software issue. It needs to read error logs, search documentation, examine source files, test fixes, and track which approaches failed. Each action generates observations that fill the context window. Within an hour, the agent hits the limit.
What happens next reveals a fundamental challenge. As an agent works through a multi-step task, its context accumulates:
- System instructions
- Tool descriptions and documentation
- Conversation history
- Previous thoughts and actions
- Observations from tool use
- Intermediate results and findings
After dozens or hundreds of steps, the context window fills up. The agent starts forgetting earlier decisions, repeating failed approaches, or losing track of its overall goal.
Current solutions require manual intervention. Anthropic's context engineering guide describes three approaches developers use:
Compaction: Summarize the conversation history and restart with the compressed version, freeing context space.
Structured note-taking: The agent writes important information to external files, retrieves notes when needed, and maintains memory outside the context window.
Sub-agent architectures: Spawn specialized agents for focused tasks, each with a clean context, then summarize their findings back to a coordinating agent.
All three approaches work, but they share a limitation: a developer must design and implement the memory management strategy. The agent doesn't autonomously decide what to remember or forget.
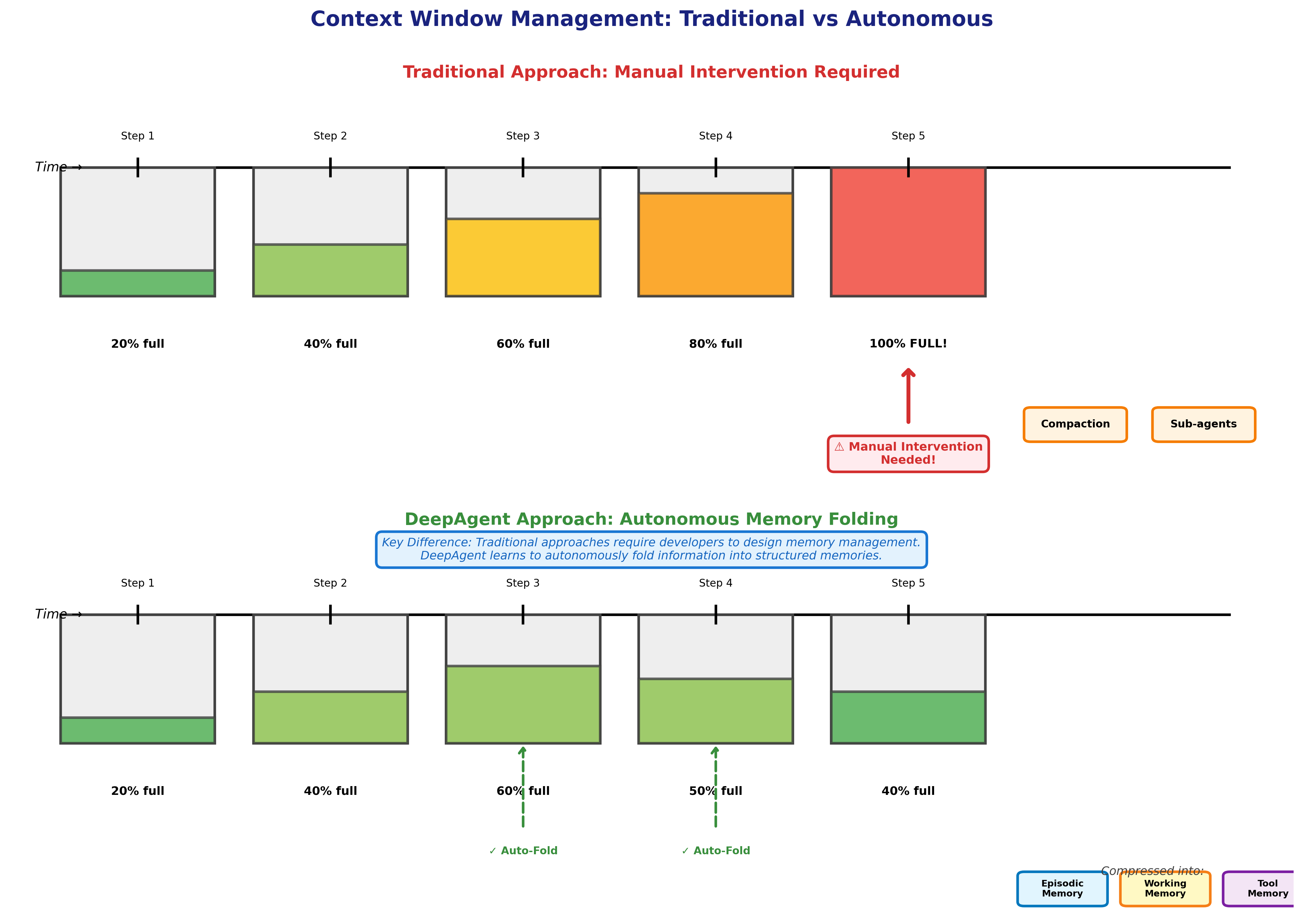 Figure 2: Traditional agents require manual intervention when context windows fill up (top), while DeepAgent autonomously folds information into structured memories (bottom).
Figure 2: Traditional agents require manual intervention when context windows fill up (top), while DeepAgent autonomously folds information into structured memories (bottom).
DeepAgent's Solution: Autonomous Memory Folding
DeepAgent introduces a mechanism called Autonomous Memory Folding that addresses context management without human-designed strategies.
The system compresses interaction history into three structured memory types, inspired by cognitive architecture research on how brains organize information:
Episodic Memory: Records of significant events and experiences from the agent's operation. When the agent solves a subproblem or encounters an important outcome, it stores a compressed episode—much like how humans remember specific experiences ("I debugged a similar authentication error last week").
Working Memory: The current task context—what the agent is actively reasoning about right now. This is the "thinking space" for immediate problem-solving, equivalent to human short-term memory where we hold information we're actively using.
Tool Memory: Information about available tools, their purposes, and when they've been successfully used. This helps the agent recognize which tools work for which situations, learning from experience which APIs solve which problems.
The key innovation is the word "autonomous." DeepAgent decides when to compress information, what to keep in working memory, and what to fold into episodic or tool memories. A developer doesn't write compaction logic—the agent learns to manage its own memory through its training process.
This approach draws from research on episodic memory in AI systems, which suggests it "may be a missing link" for general intelligence. Human cognition relies heavily on episodic memory—recalling specific events and experiences to inform current decisions. DeepAgent brings this pattern to reasoning agents.
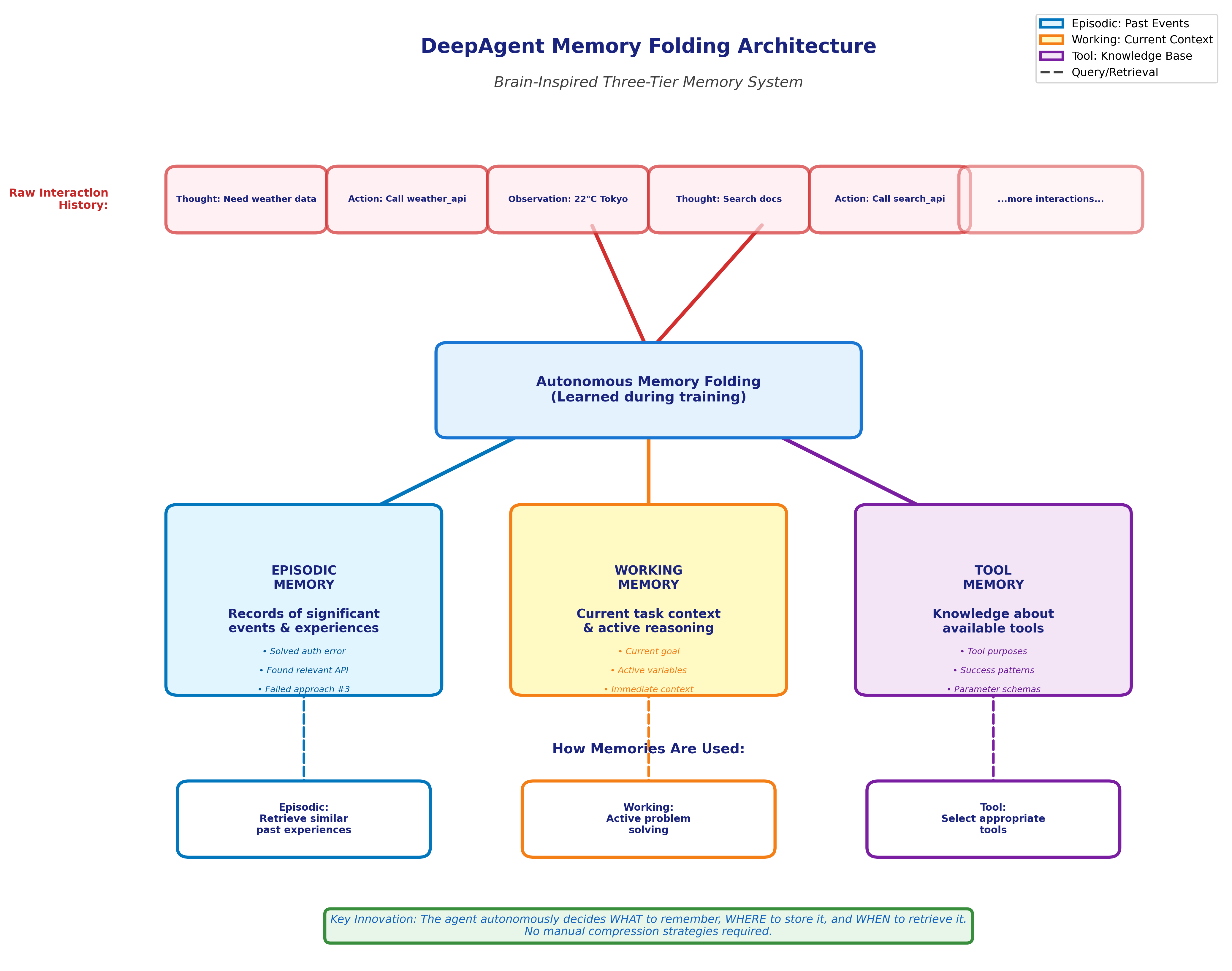 Figure 3: DeepAgent's three-tier memory architecture autonomously compressing interaction history into Episodic, Working, and Tool memories.
Figure 3: DeepAgent's three-tier memory architecture autonomously compressing interaction history into Episodic, Working, and Tool memories.
The practical benefit appears in long-horizon tasks. Where traditional agents accumulate context until they can no longer function effectively, DeepAgent compresses past interactions, maintains focus on the current problem, and retrieves relevant episodes when needed.
Testing on benchmarks like ToolBench and API-Bank demonstrates this advantage. Tasks requiring dozens of tool calls and extended reasoning chains show consistent improvements compared to baseline ReAct agents.
The Learning Problem: Which Tool to Use When
Memory management solves one challenge. Tool use presents another.
Modern AI agents can work with external tools through function calling—the LLM outputs structured JSON describing which function to call and with what parameters, then a developer's code executes that function. This works, but how does an agent learn which tools to use for which tasks?
The standard approach uses supervised fine-tuning: collect examples of correct tool use, show the model these examples, and train it to recognize patterns. An agent sees demonstrations like "For weather queries, use the weather API" or "For math problems, use the calculator tool."
Supervised learning works well when tasks are straightforward and tools are few. The approach breaks down as tool sets scale. For ten tools, this works. For hundreds, it becomes impractical. For thousands, it breaks down completely.
Consider ToolBench, a benchmark with 16,464 real-world APIs across 49 categories. No reasonable number of examples can demonstrate every tool's optimal use case.
A deeper problem exists: supervised learning teaches pattern matching, not actual understanding. The agent learns "this input pattern matches this tool" but doesn't learn why that tool works or how to adapt when the situation varies slightly.
Reinforcement learning offers an alternative. Instead of copying examples, RL agents learn through trial and error—much like humans learning a new skill. They try actions, receive feedback on outcomes, and adjust their behavior to maximize rewards.
Code Example: Supervised vs. Reinforcement Learning
See the full working example in /images/deepagent/04_supervised_vs_rl_tool_selection.py
# Supervised Learning: Pattern matching from examples
def supervised_tool_selection(query: str) -> str:
if "weather" in query.lower():
return "weather_api"
elif "calculate" in query.lower():
return "calculator_api"
else:
return "unknown_tool" # Fails on unfamiliar patterns!
# Reinforcement Learning: Learning from experience
class RLToolSelector:
def __init__(self, available_tools):
self.tools = available_tools
self.experiences = {} # Tracks success rates
self.exploration_rate = 0.3 # Try new things 30% of time
def select_tool(self, query, query_type):
# Explore: Try random tools to learn
if random.random() < self.exploration_rate:
return random.choice(self.tools)
# Exploit: Use the best known tool
return self.find_best_for(query_type)
def learn_from_experience(self, tool, success, reward):
# Update knowledge based on outcomes
self.experiences[tool].update(reward)
The full example includes 233 lines of working code with detailed comments and outputs.
The challenge with RL for tool use is credit assignment: when a multi-step task succeeds or fails, which specific tool choices deserve credit or blame?
Imagine an agent completing a task that requires five tool calls. The final outcome is successful, earning a positive reward. But which of those five tool calls was crucial? Maybe the first and third calls were perfect choices, the second was unnecessary, and the fourth and fifth were suboptimal but sufficient. Standard RL assigns credit to the entire sequence, not individual decisions.
ToolPO: Fine-Grained Credit Assignment for Tool Use
DeepAgent's second major innovation is ToolPO (Tool Policy Optimization), an end-to-end reinforcement learning strategy that solves the credit assignment problem for tool use.
ToolPO builds on RLHF (Reinforcement Learning from Human Feedback), the technique that powers ChatGPT, Claude, and other AI assistants. RLHF uses human preferences to guide model training—showing the model multiple outputs, having humans rank them, and training the model to generate responses humans prefer.
ToolPO adapts this approach specifically for tool-using behavior. The system:
- Uses LLM-simulated APIs for training (creating a sandbox where agents can safely experiment)
- Applies fine-grained credit assignment specifically to tool invocation tokens (the exact moments when the agent decides which tool to call)
- Computes a "tool-call advantage" that measures how much better or worse a specific tool choice was compared to alternatives
The advantage function captures something important: not just whether the overall task succeeded, but whether this particular tool call contributed to that success.
Think of it like a basketball team analyzing game footage. You can look at the final score (overall reward), but better analysis identifies which specific plays contributed most to winning. A pass that created an open shot deserves more credit than a pass that went nowhere, even if both happened in a winning game.
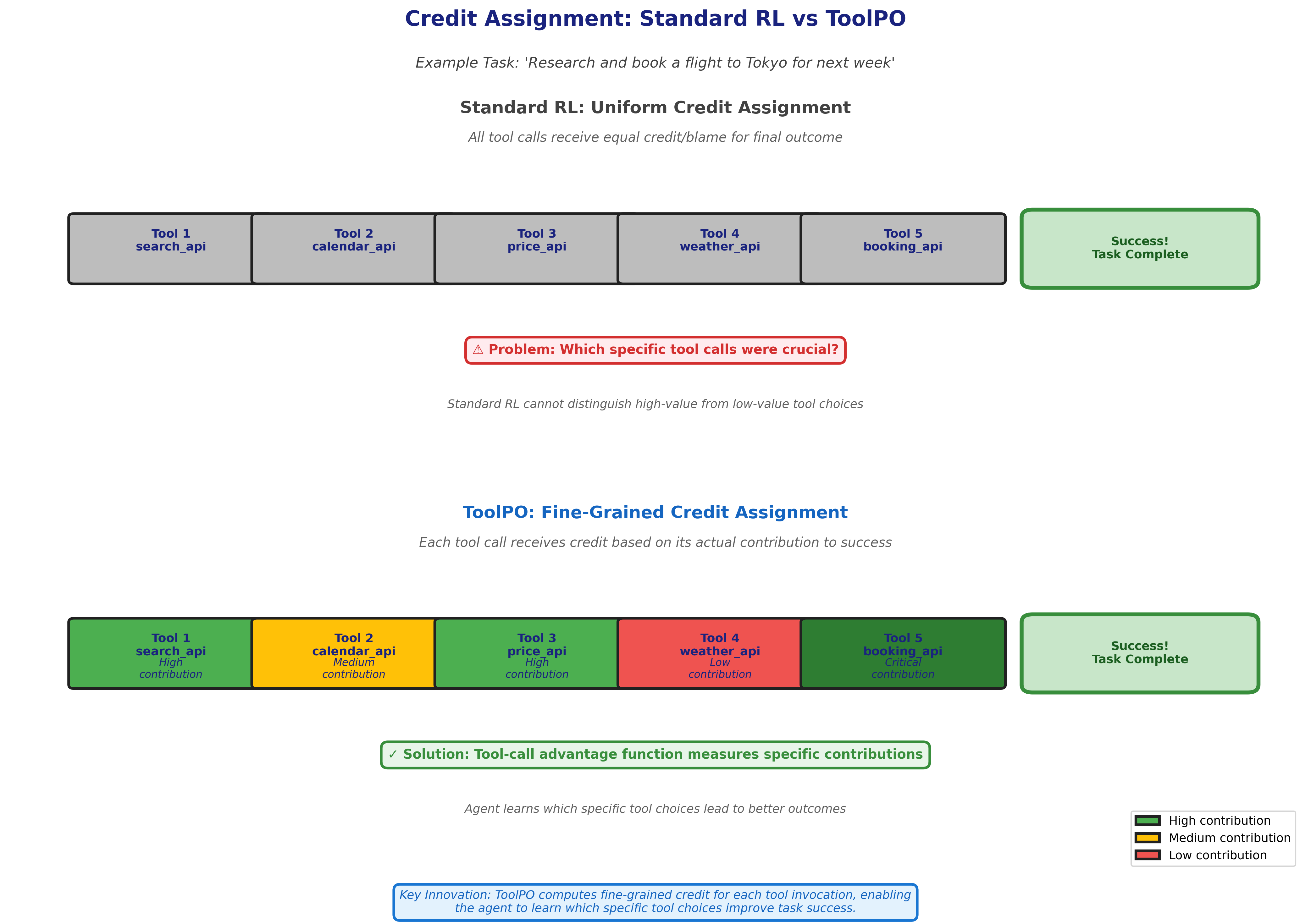 Figure 4: ToolPO attributes credit based on each tool's actual contribution to success, enabling more effective learning than uniform credit assignment.
Figure 4: ToolPO attributes credit based on each tool's actual contribution to success, enabling more effective learning than uniform credit assignment.
The training process uses LLM-simulated APIs—essentially, another LLM acts as a simulated environment, responding to API calls the agent makes. This creates a safe training ground where agents can try many different tool-calling strategies without real-world consequences or API costs.
Proximal Policy Optimization (PPO), a well-established RL algorithm, handles the actual training. PPO prevents catastrophic updates where the agent's behavior changes too drastically in one step. It also includes a penalty term that keeps the agent's language generation close to the original model, preventing the agent from developing incoherent outputs that accidentally score high rewards.
The result: DeepAgent learns not just which tools exist, but which tools work effectively for different situations, through experience rather than memorization.
Scaling to Thousands of Tools
Most research on AI agents tests with small tool sets—five to twenty tools. Real-world applications involve far more options.
DeepAgent's evaluation includes ToolBench, which scales from tens to 16,000+ tools. This tests whether the system's architecture breaks down as choices multiply.
Results show consistent performance across scale. The combination of memory folding and ToolPO enables DeepAgent to:
- Maintain relevant tool information in tool memory
- Retrieve appropriate tools for current tasks
- Avoid getting overwhelmed by choice paralysis
- Learn from experience which tools work in practice
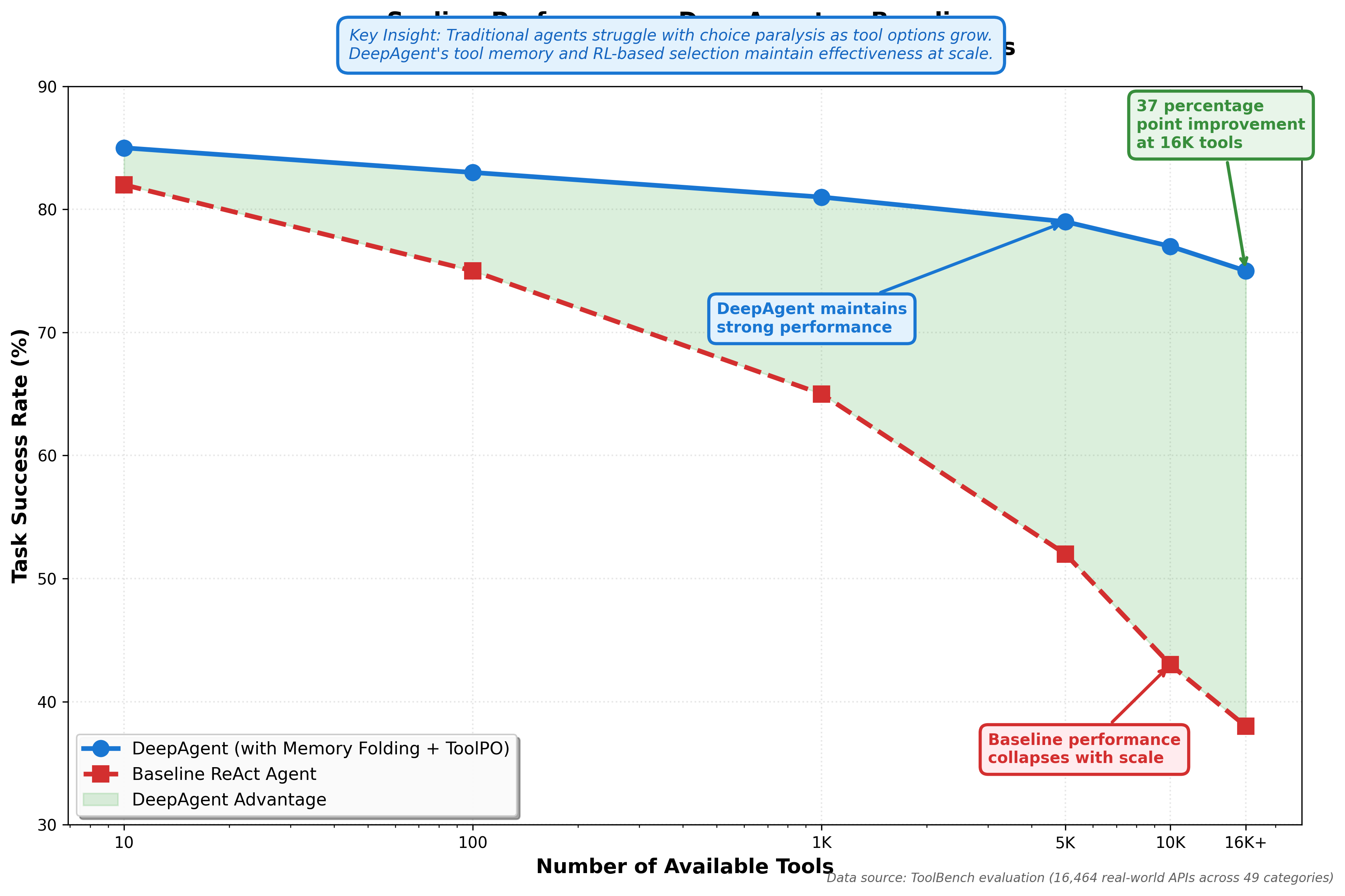 Figure 5: DeepAgent maintains 75-85% success rates from 10 to 16,000+ tools, while baseline performance collapses to 38%.
Figure 5: DeepAgent maintains 75-85% success rates from 10 to 16,000+ tools, while baseline performance collapses to 38%.
The practical implication matters for your production systems. You can provide comprehensive tool libraries without careful curation down to a "perfect" minimal set. The agent learns which tools prove useful through experience.
Eight Benchmarks: Measuring Real Capability
Academic AI research sometimes optimizes for narrow benchmarks that don't reflect real-world complexity. DeepAgent's evaluation spans eight diverse benchmarks testing different capabilities:
General Tool Use:
- ToolBench: Real-world RESTful APIs (16,464 tools across 49 categories)
- API-Bank: 73 runnable API tools with 314 dialogue scenarios
- TMDB & Spotify: Domain-specific tasks (movies, music)
- ToolHop: Multi-hop tool use requiring chaining multiple calls
Embodied and Applied Tasks:
- ALFWorld: Household tasks in a 3D simulated environment (6 task types)
- WebShop: E-commerce navigation and product purchasing
- GAIA: General AI assistant tasks (GPT-4 achieves under 50% success)
- Humanity's Last Exam (HLE): Expert-level reasoning challenges
This breadth tests whether DeepAgent's innovations generalize. A system optimized only for API calling might fail at embodied tasks. An agent effective in structured environments might struggle with open-ended assistant queries.
The results demonstrate consistent improvements across all scenarios. DeepAgent outperforms baseline approaches on ToolBench, API-Bank, and the specialized benchmarks, suggesting the core innovations—autonomous memory folding and ToolPO—address fundamental agent limitations rather than solving narrow problems.
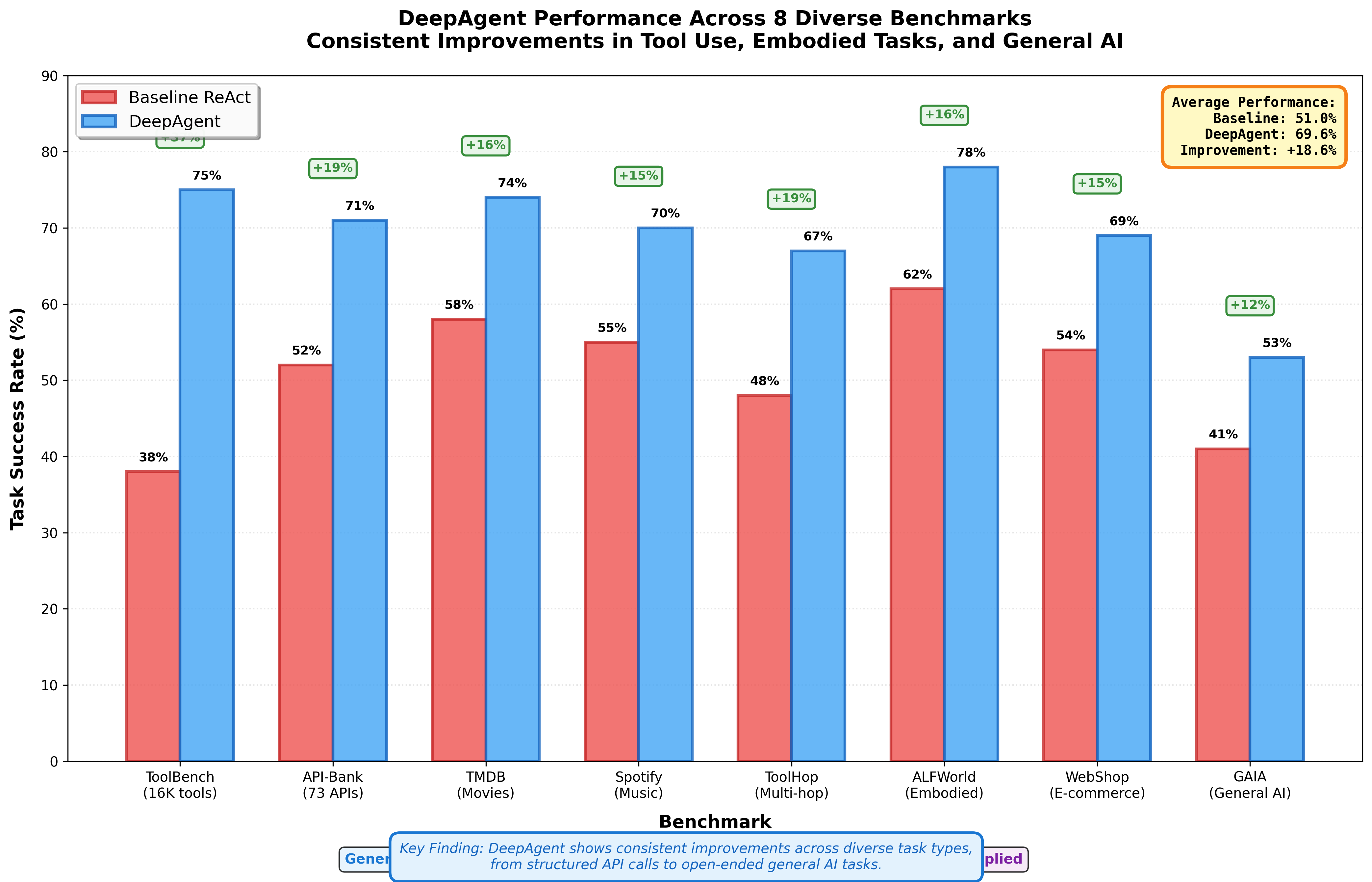 Figure 6: Consistent improvements across eight benchmarks ranging from +12% to +37%, averaging +18.6 percentage points.
Figure 6: Consistent improvements across eight benchmarks ranging from +12% to +37%, averaging +18.6 percentage points.
GAIA results particularly reveal real-world gaps. This benchmark shows that even GPT-4 completes fewer than half of tasks when actual tool use and intermediate verification are enforced (not just accepting the LLM's claims of success). Improvements on GAIA indicate progress toward agents that work reliably in practice, not just in controlled tests.
How the Pieces Fit Together: Unified Reasoning
DeepAgent doesn't just add memory folding and ToolPO as separate components. The system performs thinking, tool discovery, and action execution within a single coherent reasoning process.
Traditional agent architectures often separate:
- A reasoning module that plans actions
- A retrieval module that finds relevant tools
- An execution module that calls tools
- A memory module that tracks history
This separation creates coordination challenges. When should the agent consult memory? How does tool discovery integrate with reasoning? When does execution feedback influence planning?
DeepAgent's unified framework handles these questions by treating all aspects as part of one continuous reasoning process. The agent:
- Reasons about the current state (drawing from working memory)
- Considers what information or capabilities it needs
- Retrieves relevant tools or episodic memories
- Takes actions and observes outcomes
- Autonomously decides when to fold information into compressed memories
- Continues reasoning with updated context
This integration resembles how humans approach complex problems. We don't consciously separate "now I'm retrieving a memory" from "now I'm reasoning about options" from "now I'm taking action." These processes flow together naturally.
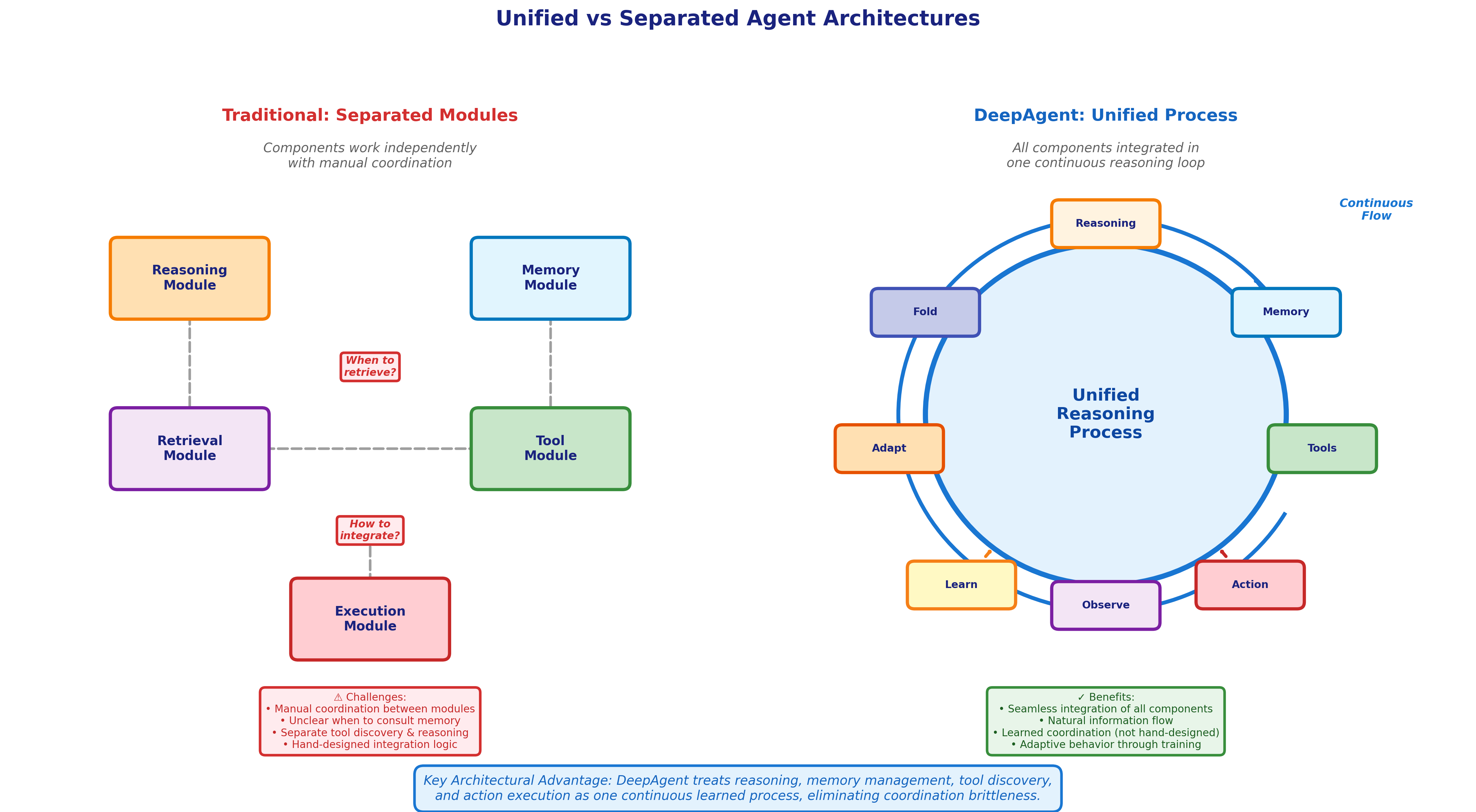 Figure 7: DeepAgent integrates all components into one continuous reasoning process, eliminating coordination brittleness.
Figure 7: DeepAgent integrates all components into one continuous reasoning process, eliminating coordination brittleness.
The unified approach reduces the brittleness that comes from hand-designed coordination between separate components. When memory management, tool selection, and reasoning are all part of one learned process, the system can adapt these behaviors jointly through training.
What This Means for Developers
DeepAgent is research, not a production framework like LangChain or AutoGPT. However, the innovations point toward where AI agent development is heading.
Autonomous memory management: Current production agents require developers to implement compaction strategies, external note-taking systems, or sub-agent coordination. As autonomous memory folding techniques mature, agents could handle context management themselves, reducing developer burden and improving reliability.
Learning from experience: Today's agents primarily learn from demonstrations. The ToolPO approach shows that agents can learn tool use through reinforcement learning with fine-grained credit assignment. Production systems might combine supervised learning (for basic patterns) with RL fine-tuning (for optimization and edge cases).
Scaling to comprehensive tool libraries: Rather than carefully curating minimal tool sets as current best practices recommend, future agents might work effectively with large, comprehensive tool libraries, learning which tools prove useful through operation.
The gap between research capabilities and production deployments remains significant. Research benchmarks test performance; production systems require reliability, predictability, cost management, and safety guarantees. DeepAgent demonstrates what's possible in controlled evaluation. Translating these innovations into production systems presents additional engineering challenges.
Limitations and Open Questions
The DeepAgent paper demonstrates strong benchmark performance, but several questions remain:
Computational costs: The paper doesn't specify training costs, inference latency, or resource requirements compared to baseline approaches. RL training typically requires significant compute, and autonomous memory folding adds processing overhead.
Failure modes: Research papers emphasize successes; detailed analysis of when and how DeepAgent fails would help developers understand limitations. What types of tasks break the memory folding mechanism? When does ToolPO learn suboptimal tool-use patterns?
Production deployment: How difficult is integrating DeepAgent-style systems into real applications? What operational challenges arise? How do costs scale with real-world usage?
Long-term operation: Evaluations test tasks lasting minutes to hours. How does performance change for truly long-horizon operations spanning days or weeks?
Adversarial robustness: Can malicious tool environments exploit the learning system? How does the agent handle deliberately misleading tools or responses?
Information loss in compression: When folding interaction history into episodic memory, what information gets lost? Could critical details be discarded, leading to suboptimal decisions later?
These questions don't diminish the research contributions—they represent the gap between promising research and production-ready systems. Further work will address these considerations.
The Path Forward
DeepAgent represents meaningful progress on two fundamental challenges in AI agent development: memory management for long-horizon tasks and scalable tool use learning.
The autonomous memory folding mechanism moves from developer-designed compaction strategies to learned, brain-inspired memory organization. The ToolPO approach demonstrates that reinforcement learning with fine-grained credit assignment can teach agents which tools to use through experience rather than examples alone.
Comprehensive evaluation across eight diverse benchmarks suggests these innovations address general agent limitations, not narrow problems. Scaling from tens to thousands of tools without performance collapse demonstrates practical scalability.
For developers building with current agent frameworks, DeepAgent's research offers insights into future directions. The principles—autonomous context management, learning from experience, unified reasoning processes—point toward more capable and reliable agent systems.
The research is available on arXiv (paper 2510.21618) with code and demonstrations on GitHub (RUC-NLPIR/DeepAgent). As these innovations mature and transition from research to production frameworks, AI agents may become genuinely autonomous problem-solvers rather than carefully constrained assistants requiring constant human oversight and manual memory management.
What's next? If you're building AI agents, explore the DeepAgent repository to see how autonomous memory folding works in practice. For more on agent memory systems, read our analysis of ReasoningBank and dynamic tool allocation patterns.