Benchmarks vs RL Environments: Why the Distinction Actually Matters
When I first started working with reinforcement learning, I used "benchmark" and "environment" interchangeably. CartPole was a benchmark. MuJoCo was a benchmark. Atari was definitely a benchmark. Then I spent three weeks debugging why my results weren't comparable to published papers, and I realized the distinction between these terms actually matters quite a lot.
A colleague finally asked me the question that cleared things up: "Do you mean which environment to train on, or which benchmark to report results on?" I stared blankly. Weren't they the same thing?
Here's the core difference: environments are the interactive simulators where agents learn, while benchmarks are standardized protocols that wrap environments with specific rules for fair comparison. Getting this right matters because, according to a survey of NeurIPS 2022 RL papers, "performance evaluation is the primary form of experimentation, with 91% of empirical papers using it."1 If you're among that 91%, you need to understand what you're actually measuring.
The Core Distinction: Playgrounds vs Exams
Think of an environment as a playground. It's a place where your agent can interact, learn, and make mistakes. As the Toloka AI team puts it, an RL gym is "a controlled digital environment where intelligent agents learn by interacting with simulated tasks and receiving structured feedback."2 The environment provides the rules of interaction: what observations look like, what actions are valid, and what rewards mean.
A benchmark, on the other hand, is more like a standardized exam administered on that playground. It specifies not just where you're playing, but how you should play, how long, and how we'll score your performance. A benchmark takes one or more environments and wraps them with evaluation protocols, metrics, and comparison standards.
 Figure 1: DeepMind Control Suite provides continuous control environments using MuJoCo physics. The environments themselves are the interactive simulations; the benchmark adds standardized reward structures and evaluation protocols. Source: DeepMind Control Suite3
Figure 1: DeepMind Control Suite provides continuous control environments using MuJoCo physics. The environments themselves are the interactive simulations; the benchmark adds standardized reward structures and evaluation protocols. Source: DeepMind Control Suite3
The DeepMind Control Suite illustrates this well. The paper describes it as "a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents."3 Notice how they're providing both the environments (physics simulations) and the benchmark structure (standardized rewards, consistent interfaces).
What Defines an RL Environment?
At its core, every environment implements a simple interface. "At the foundation is a concise interface: reset(), step(), and close(), with optional methods such as render() or seed()."4 This pattern, standardized by OpenAI Gym in 2016 and now maintained through Gymnasium, defines the contract between your learning algorithm and the world it operates in.
Technically speaking, "an Env roughly corresponds to a Partially Observable Markov Decision Process (POMDP)."5 In practice, environments handle three core responsibilities:
- State representation: "Observations describe the information available to the agent, pixel arrays, joint angles, or symbolic states"6
- Action execution: How the agent's decisions affect the world
- Reward generation: The feedback signal guiding learning
The concept became practical with the introduction of OpenAI Gym in 2016, "an open-source library that standardized how these environments connect to algorithms."7 "That standardization solved a major reproducibility problem in early reinforcement learning research."8
 Figure 2: The Gymnasium API defines how agents interact with environments through a standardized reset-step-observe-reward cycle. Source: Gymnasium9
Figure 2: The Gymnasium API defines how agents interact with environments through a standardized reset-step-observe-reward cycle. Source: Gymnasium9
"MuJoCo stands for Multi-Joint dynamics with Contact. It is a physics engine for facilitating research and development in robotics, biomechanics, graphics and animation."10 As of October 2021, DeepMind has acquired MuJoCo and open-sourced it in 2022, making it free for everyone.11 This changed continuous control research, with "eleven MuJoCo environments (in roughly increasing complexity)"12 now accessible to anyone.
For multi-agent scenarios, "PettingZoo is a simple, pythonic interface capable of representing general multi-agent reinforcement learning (MARL) problems."13 The library supports two distinct APIs: "The AEC API supports sequential turn based environments, while the Parallel API supports environments with simultaneous actions."14
 Figure 3: PettingZoo provides standardized multi-agent environments ranging from classic games to complex coordination scenarios. Source: PettingZoo15
Figure 3: PettingZoo provides standardized multi-agent environments ranging from classic games to complex coordination scenarios. Source: PettingZoo15
What Makes Something a Benchmark?
A benchmark adds a crucial layer on top of environments: standardized evaluation protocols. This includes fixed training budgets, specific metrics, defined train/test splits, and agreed-upon reporting conventions.
Consider the Atari 100K benchmark. It uses standard Atari environments, but constrains agents to roughly 2 hours of gameplay worth of interactions (around 100,000 environment steps). This transforms the same games that DQN mastered with billions of frames into a completely different challenge testing sample efficiency rather than asymptotic performance.
The Components of a Benchmark
A complete benchmark specification includes:
| Component | Purpose | Example |
|---|---|---|
| Environment(s) | The actual simulation | 26 Atari games |
| Training budget | Fair comparison point | 100K interactions |
| Evaluation protocol | How to measure performance | Human-normalized mean score |
| Reporting standard | What numbers to publish | Median across 3 seeds |
| Version control | Reproducibility | Environment v4 vs v5 |
PettingZoo made versioning explicit: "PettingZoo keeps strict versioning for reproducibility reasons. All environments end in a suffix like '_v0'. When changes are made to environments that might impact learning results, the number is increased by one."16
 Figure 4: Procgen provides 16 procedurally generated environments specifically designed to test generalization, not just performance on fixed levels. Source: Procgen Benchmark17
Figure 4: Procgen provides 16 procedurally generated environments specifically designed to test generalization, not just performance on fixed levels. Source: Procgen Benchmark17
Take Procgen: "We introduce Procgen Benchmark, a suite of 16 procedurally generated game-like environments designed to benchmark both sample efficiency and generalization in reinforcement learning."17 The benchmark adds something the environments alone don't provide: a protocol for measuring generalization. The finding that changed how I think about RL: "We find that agents strongly overfit to small training sets in almost all cases. To close the generalization gap, agents need access to as many as 10,000 levels."18
You can't discover that insight by just running an environment; you need the benchmark's train/test separation methodology.
The Spectrum from Environment to Benchmark
Not everything fits neatly into one category. The field has evolved a spectrum:
Pure Environments provide simulation only. MuJoCo is a physics engine. You can build anything with it, but MuJoCo itself doesn't specify how to evaluate agents.
Environment Libraries package related environments together. Gymnasium, the maintained successor to OpenAI Gym,19 provides eleven MuJoCo environments all using the same physics engine. Each environment has a defined observation space, action space, and reward function, but training and evaluation protocols remain flexible.
Benchmark Suites add standardized evaluation. "Meta-World is a benchmark for meta-RL and multi-task learning. It contains 50 robotic manipulation tasks compatible with the Gymnasium interface."20 The benchmark specifies not just environments but task distributions, training protocols, and evaluation metrics.
 Figure 5: Meta-World's 50 robotic manipulation tasks enable evaluation of multi-task and meta-learning capabilities, revealing that current algorithms struggle with even modest task diversity. Source: Meta-World21
Figure 5: Meta-World's 50 robotic manipulation tasks enable evaluation of multi-task and meta-learning capabilities, revealing that current algorithms struggle with even modest task diversity. Source: Meta-World21
The results reveal something important about current algorithms: "These algorithms struggle to learn with multiple tasks at the same time, even with as few as ten distinct training tasks."22 This finding came specifically from benchmark-level analysis, not from studying individual environments in isolation.
Constrained Benchmarks add resource limitations. The Atari 100K benchmark uses the same games as the original Atari Learning Environment but restricts training to 100,000 environment steps. "BBF results in 2x improvement in performance over SR-SPR with nearly the same computational-cost, while results in similar performance to model-based EfficientZero with at least 4x reduction in runtime."23 These comparisons only make sense under the 100K constraint.
The Computational Reality of Rigorous Benchmarking
Here's where the rubber meets the road. "Training for 200M timesteps with PPO on a single Procgen environment requires approximately 24 GPU-hrs and 60 CPU-hrs."24 Multiply that by 16 environments, multiple algorithms, and the dozens of seeds needed for statistical rigor, and you understand why most published comparisons use minimal seeds.
A critical position paper found that "in the literature it is common for highly cited works to only have few samples per algorithm-environment pair, e.g., 1, 3, or 5 random seeds."25 The computational cost of proper evaluation is staggering: "Scaling up these experiments to use enough random seeds to have reliable confidence intervals requires at least 20-50 times more compute."26
Most published results are statistically underpowered for the claims they support.
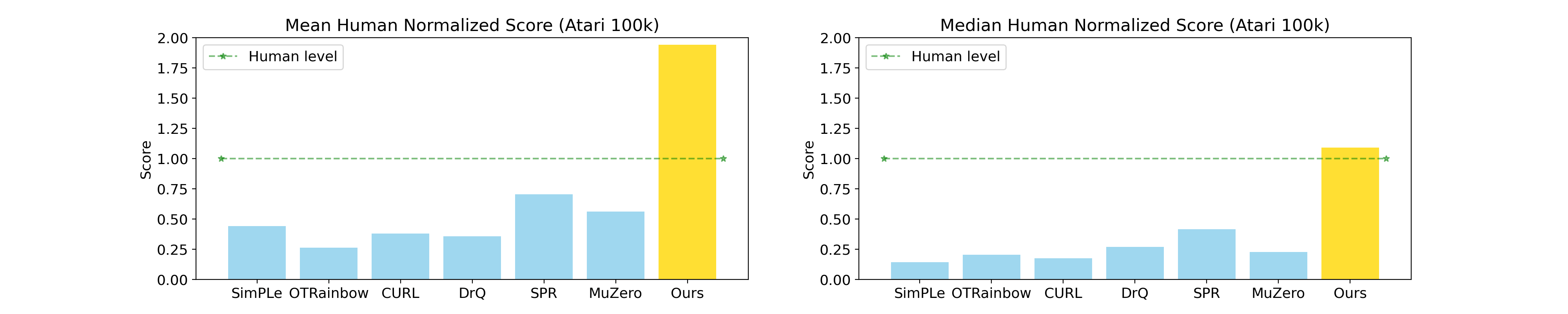 Figure 6: The Atari 100K benchmark enables direct comparison of sample efficiency across algorithms by constraining all agents to the same interaction budget. Source: CURL: Contrastive Unsupervised Representations for Reinforcement Learning27
Figure 6: The Atari 100K benchmark enables direct comparison of sample efficiency across algorithms by constraining all agents to the same interaction budget. Source: CURL: Contrastive Unsupervised Representations for Reinforcement Learning27
Computational efficiency of the environment itself matters enormously. Craftax, a JAX-accelerated reimplementation of Crafter, achieves dramatic speedups over the original Python implementation. The paper states: "Existing benchmarks used for research into open-ended learning are either too slow for meaningful research to be performed without enormous computational resources or they are not complex enough to pose a significant challenge."28
 Figure 7: Craftax achieves significant speedup through JAX implementation, enabling billion-step experiments on single GPUs. Source: Craftax28
Figure 7: Craftax achieves significant speedup through JAX implementation, enabling billion-step experiments on single GPUs. Source: Craftax28
This isn't just about convenience. When your environments run faster, you can afford more seeds, more ablations, and more rigorous statistical analysis. Infrastructure shapes what science is possible.
The Generalization Problem
One of the most important lessons from benchmark development is how easily agents overfit. The CoinRun experiments demonstrated that "substantial overfitting occurs when there are less than 4,000 training levels. Even with 16,000 training levels, overfitting is still noticeable."29
 Figure 8: Crafter evaluates agent capabilities through 22 hierarchical achievements rather than simple reward maximization. Source: Crafter30
Figure 8: Crafter evaluates agent capabilities through 22 hierarchical achievements rather than simple reward maximization. Source: Crafter30
Crafter addresses this by designing "an open world survival game with visual inputs that evaluates a wide range of general abilities within a single environment."30 The benchmark "defines 22 achievements"31 organized in a technology tree of depth 7, measuring progression rather than just episode reward. "An agent is granted a budget of 1M environment steps to interact with the environment."32
Performance gaps are stark: "DreamerV2 achieves a score of 10.0%, followed by PPO with 4.6% and Rainbow of 4.3%"33 while "Human experts achieved a score of 50.5%."34 The achievement-based metric reveals capabilities that raw reward numbers would obscure.
"Procedurally generated environments replace that rigidity with controlled randomness. Each run creates a new configuration of obstacles, goals, and transitions, forcing agents to generalize instead of memorize."35 The shift is philosophical: "Procedural variety doesn't just improve robustness, it redefines success. Instead of achieving a high score in one environment, models will be judged by their transfer performance across many unseen configurations."36
Domain-Specific Considerations
Different application domains require different approaches to the environment/benchmark distinction.
Autonomous Driving: "CARLA is an open-source simulator explicitly designed to support research in autonomous driving and ADAS."37 "Built on Unreal Engine 4, CARLA provides a photorealistic 3D environment with configurable urban and highway scenes that include diverse road layouts, dynamic weather, and day-night cycles."38 The CARLA Leaderboard then adds benchmark structure with standardized routes and evaluation metrics: "CARLA Leaderboard v2 encompasses 39 real-world corner cases, providing more realistic autonomous driving scenarios than previous versions."39
Interestingly, "model-free approaches dominate the CARLA literature, accounting for over 80% of all surveyed works."40 This tells us something about which methods researchers find tractable in this environment, which is itself benchmarking-relevant information.
Robotics: "Isaac Lab is built on top of Isaac Sim to provide a unified and flexible framework for robot learning that exploits latest simulation technologies."41 The platform "includes actuator dynamics in the simulation, procedural terrain generation, and support to collect data from human demonstrations."42 GPU acceleration enables thousands of parallel environments: "Isaac Gym provides a high performance GPU-based physics simulation for robot learning."43
Multi-Agent: Recent benchmarking work found troubling results: "Fully cooperative MARL tasks need careful algorithmic design, in terms of both excessive coordination and joint exploration, as current SoTA and standard MARL methods are not very effective."44 The benchmark exposed limitations invisible when testing algorithms on individual environments.
Beyond Static Benchmarks: The Continual Learning Frontier
Static benchmarks have a fundamental limitation. "Continual Reinforcement Learning (CRL) emerges from the intersection of RL and continual learning, aspiring to address the numerous limitations present in current RL algorithms."45 The problem: "existing DRL algorithms generally lack the ability to efficiently transfer knowledge across tasks or adapt to new environments."46
A CRL agent "is expected to achieve two key objectives: 1) minimizing the forgetting of knowledge from previously learned tasks and 2) leveraging prior experiences to learn new tasks more efficiently."47 Traditional benchmarks measure final performance; continual learning benchmarks must measure stability (maintaining previous performance) and plasticity (the ability to learn new things).48
Real-world environments rarely stay static, and agents that only perform well on fixed benchmarks may fail when conditions change.
Practical Takeaways
So what should you actually do with this distinction?
When selecting environments, consider what you're trying to learn. "Lightweight tasks such as CartPole or MountainCar benchmark basic algorithms. Complex simulators like MuJoCo, CARLA, or Isaac Gym examine continuous control and perception."49 Match complexity to your research question.
When designing benchmarks, specify your evaluation protocol explicitly. How many seeds? What metrics? Train/test separation? Time or sample budget? The benchmark is the protocol plus the environment, and the protocol matters as much as the environment choice.
When interpreting results, remember that "in the literature it is common for highly cited works to only have few samples per algorithm-environment pair, e.g., 1, 3, or 5 random seeds."25 Most published comparisons you've read probably don't meet the statistical bar for reliable algorithm ranking.
When reporting results, document everything. "A common interface ensures that identical code produces identical outcomes across machines, operating systems, and compute configurations."50 But that's necessary, not sufficient, for reproducible science. Specify environment version, training steps, random seeds, and evaluation protocol.
The standardization that Gymnasium and PettingZoo provide "mirrors what ImageNet did for computer vision: a clear, measurable, and reusable benchmark that brought coherence to an otherwise fragmented field."51 But standardization of interfaces is just the beginning. Standardization of evaluation protocols, computational budgets, and statistical practices remains a work in progress.
Conclusion
The distinction between benchmarks and RL environments is not semantic triviality. Environments are where agents learn. Benchmarks are how we compare them. Conflating the two works fine for casual conversation, but falls apart when you need reproducible, meaningful algorithm comparisons.
Three takeaways for your work:
-
Check what you're actually measuring. An environment without a benchmark protocol tells you how an agent performs on that specific setup. A proper benchmark tells you how it compares to alternatives.
-
Report more than you think necessary. Environment version, training steps, random seeds, evaluation episodes. Future you will thank present you.
-
Don't confuse benchmark success with real-world readiness. "Gyms democratized reinforcement learning education. Instead of building a simulator from scratch, a beginner can import gymnasium, call env = gym.make('CartPole-v1'), and watch an agent learn in minutes."52 But benchmark performance doesn't guarantee production success.
The next time you read a paper claiming state-of-the-art results, ask two questions: What environment did they use? And more importantly, what benchmark?
The environment provides the world. The benchmark provides the science.
References
Footnotes
-
Position: Benchmarking is Limited in Reinforcement Learning Research. arXiv:2406.16241, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Tassa, Y., et al. "DeepMind Control Suite." arXiv:1801.00690, 2018. ↩ ↩2
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Gymnasium Team. "Gymnasium: A Standard Interface for Reinforcement Learning Environments." arXiv:2407.17032, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Gymnasium Team. "Gymnasium: A Standard Interface for Reinforcement Learning Environments." arXiv:2407.17032, 2024. ↩
-
Gymnasium MuJoCo Documentation. Farama Foundation, 2024. ↩
-
Gymnasium MuJoCo Documentation. Farama Foundation, 2024. ↩
-
Gymnasium MuJoCo Documentation. Farama Foundation, 2024. ↩
-
PettingZoo Documentation. Farama Foundation, 2024. ↩
-
PettingZoo Documentation. Farama Foundation, 2024. ↩
-
Terry, J. K., et al. "PettingZoo: A Standard API for Multi-Agent Reinforcement Learning." NeurIPS 2021. arXiv:2009.14471. ↩
-
PettingZoo Documentation. Farama Foundation, 2024. ↩
-
Cobbe, K., et al. "Leveraging Procedural Generation to Benchmark Reinforcement Learning." ICML 2020. arXiv:1912.01588. ↩ ↩2
-
Cobbe, K., et al. "Leveraging Procedural Generation to Benchmark Reinforcement Learning." ICML 2020. arXiv:1912.01588. ↩
-
Gymnasium Team. "Gymnasium: A Standard Interface for Reinforcement Learning Environments." arXiv:2407.17032, 2024. ↩
-
Gymnasium Team. "Gymnasium: A Standard Interface for Reinforcement Learning Environments." arXiv:2407.17032, 2024. ↩
-
Yu, T., et al. "Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning." ICML 2020. arXiv:1910.10897. ↩
-
Yu, T., et al. "Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning." ICML 2020. arXiv:1910.10897. ↩
-
Schwarzer, M., et al. "Bigger, Better, Faster: Human-level Atari with Human-level Efficiency." arXiv:2305.19452, 2023. ↩
-
Cobbe, K., et al. "Leveraging Procedural Generation to Benchmark Reinforcement Learning." ICML 2020. arXiv:1912.01588. ↩
-
Position: Benchmarking is Limited in Reinforcement Learning Research. arXiv:2406.16241, 2024. ↩ ↩2
-
Position: Benchmarking is Limited in Reinforcement Learning Research. arXiv:2406.16241, 2024. ↩
-
Laskin, M., et al. "CURL: Contrastive Unsupervised Representations for Reinforcement Learning." ICML 2020. arXiv:2004.13579. ↩
-
Matthews, M., et al. "Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning." arXiv:2402.16801, 2024. ↩ ↩2
-
Cobbe, K., et al. "Quantifying Generalization in Reinforcement Learning." ICML 2019. arXiv:1812.02341. ↩
-
Hafner, D. "Benchmarking the Spectrum of Agent Capabilities." ICLR 2022. arXiv:2109.06780. ↩ ↩2
-
Hafner, D. "Benchmarking the Spectrum of Agent Capabilities." ICLR 2022. arXiv:2109.06780. ↩
-
Hafner, D. "Benchmarking the Spectrum of Agent Capabilities." ICLR 2022. arXiv:2109.06780. ↩
-
Hafner, D. "Benchmarking the Spectrum of Agent Capabilities." ICLR 2022. arXiv:2109.06780. ↩
-
Hafner, D. "Benchmarking the Spectrum of Agent Capabilities." ICLR 2022. arXiv:2109.06780. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
CARLA RL Review. arXiv:2509.08221, 2025. ↩
-
CARLA RL Review. arXiv:2509.08221, 2025. ↩
-
CARLA RL Review. arXiv:2509.08221, 2025. ↩
-
CARLA RL Review. arXiv:2509.08221, 2025. ↩
-
Isaac Lab Documentation. NVIDIA, 2024. ↩
-
Isaac Lab Documentation. NVIDIA, 2024. ↩
-
Isaac Lab Documentation. NVIDIA, 2024. ↩
-
Extended Benchmarking of Multi-Agent Reinforcement Learning Algorithms. arXiv:2502.04773, 2025. ↩
-
Continual Reinforcement Learning Survey. arXiv:2506.21872, 2025. ↩
-
Continual Reinforcement Learning Survey. arXiv:2506.21872, 2025. ↩
-
Continual Reinforcement Learning Survey. arXiv:2506.21872, 2025. ↩
-
Continual Reinforcement Learning Survey. arXiv:2506.21872, 2025. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩
-
Toloka AI. "Inside the RL Gym: Reinforcement Learning Environments Explained." Toloka AI Blog, 2024. ↩