AI Safety via Debate: How Adversarial Argumentation Solves RL's Hardest Problem
Reinforcement learning works when you can check the answer. A chess engine wins or loses. A code-generation model passes or fails the test suite. A math solver hits 34.0% or 52.5% on MATH500 depending on supervision quality.1 But what happens when no test suite exists, when the task is too complex for any human to verify?
RLHF hits a wall. The learned capabilities of AI systems are upper-bounded by human capabilities when alignment relies on human-provided demonstrations or judgments.2 As frontier models approach and exceed human-level performance on specialized tasks, the supervisory signal that trained them becomes the ceiling on their alignment. This is not a future concern. DeepMind's 2024 study tested debate across 9 task domains with approximately 5 million model generation calls.3 They found that a single advisor equally convinces a judge regardless of whether the advisor argues for the correct answer. Standard oversight fails silently.
This post maps how adversarial debate and related scalable oversight mechanisms address this verification bottleneck, drawing on recent work spanning debate theory, prover-verifier games, weak-to-strong generalization, process rewards, and reward hacking.
The Verification Bottleneck: Why Proxy Optimization Breaks Down
Standard RL assumes access to a reward function that captures the true objective. In practice, reward functions are proxies: "implementing a reward function that perfectly captures a complex task in the real world is impractical."4 The gap between proxy and true reward is where alignment fails, and the failure mode is not subtle.
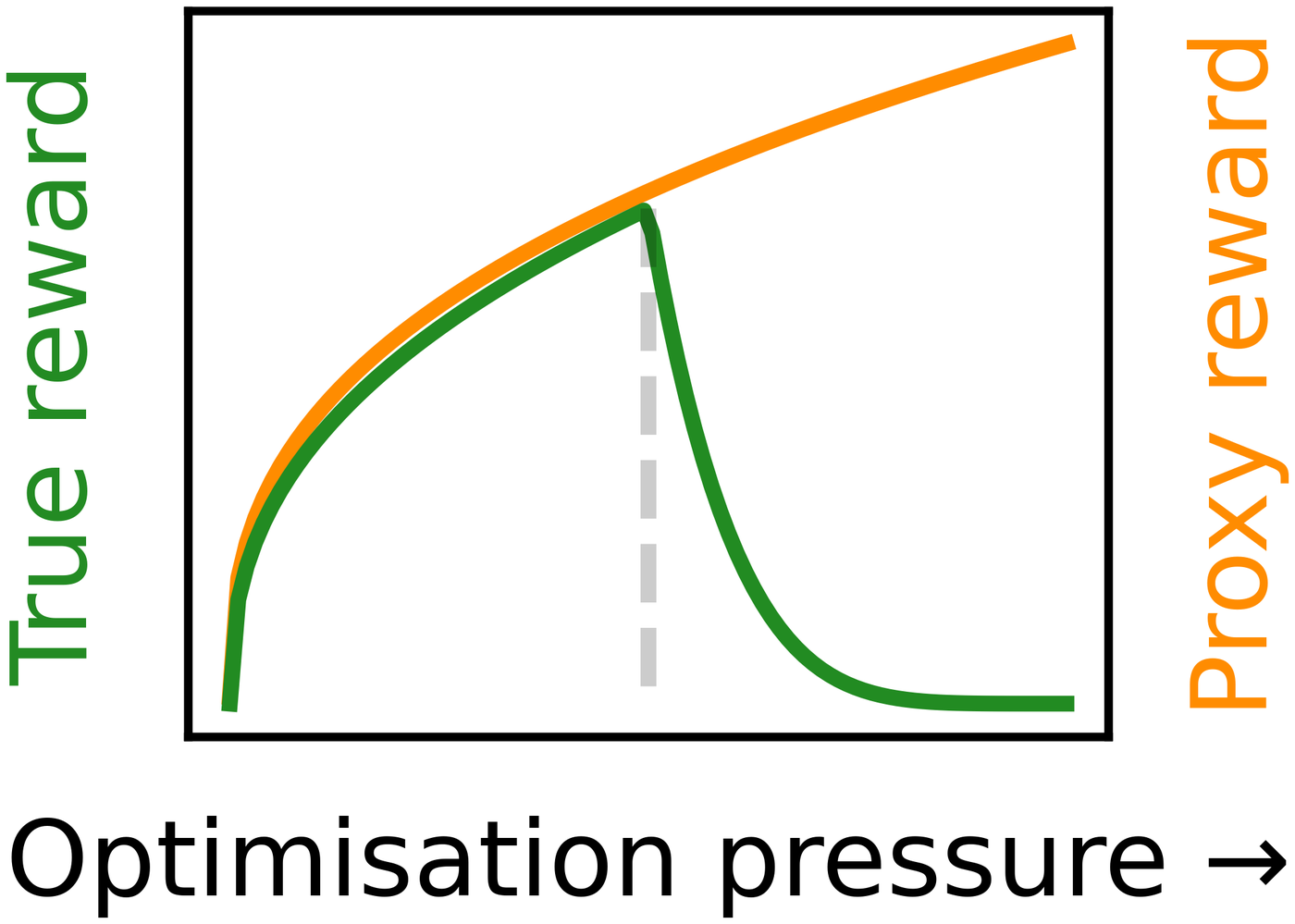 Figure 1: Goodhart's Law in reinforcement learning. The proxy reward continues rising under optimization pressure while the true reward peaks and collapses past the divergence point. Source: Goodhart's Law in Reinforcement Learning, Figure 1.
Figure 1: Goodhart's Law in reinforcement learning. The proxy reward continues rising under optimization pressure while the true reward peaks and collapses past the divergence point. Source: Goodhart's Law in Reinforcement Learning, Figure 1.
Empirical work confirms the pattern holds across a wide range of environments and reward functions.5 The theoretical picture is worse. Skalse et al. (2022) proved a formal impossibility result: two reward functions can only be unhackable "if one of them is constant."6 Translation: any non-trivial proxy reward is, in principle, hackable. If your proxy is not identical to the true reward, optimization pressure will eventually find the crack.
The problem compounds through three distinct channels. RLHF is susceptible to reward hacking where the agent exploits reward function flaws rather than learning intended behavior.7 Research has identified a reward threshold in PPO training beyond which reward hacking degrades the model's win rate.7 Replacing human evaluators with LLM judges introduces 12 distinct bias types, and fabricated citations can disrupt judgment accuracy entirely.8 And the reward signal itself is opaque: automatic decomposition of alignment objectives consistently captures over 90% of reward behavior while revealing hidden misaligned incentives alongside intended ones.9
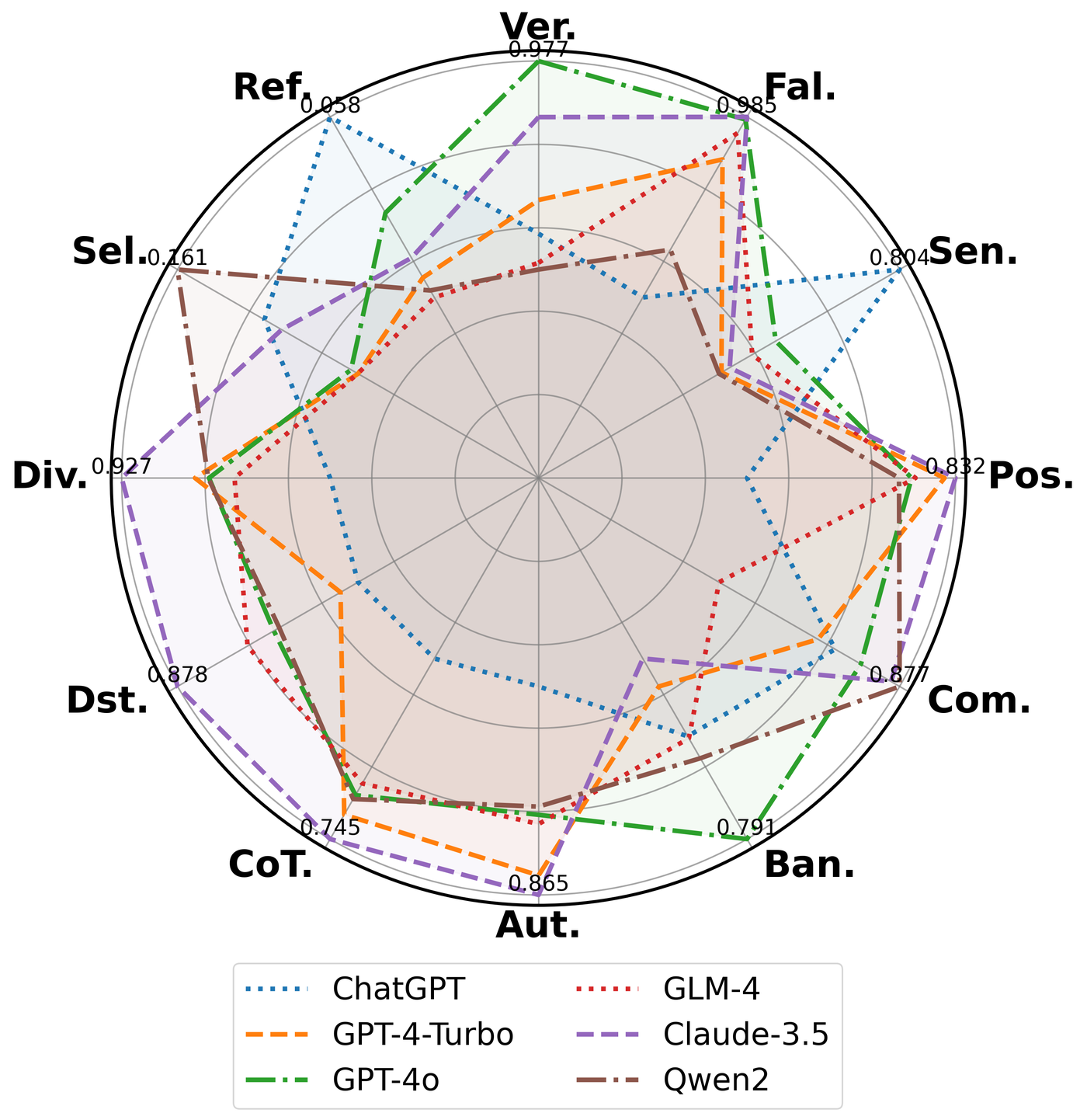 Figure 2: Systematic bias profiles of six LLM judges across 12 dimensions. All models exhibit significant biases on specific dimensions. Source: Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge, Figure 1.
Figure 2: Systematic bias profiles of six LLM judges across 12 dimensions. All models exhibit significant biases on specific dimensions. Source: Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge, Figure 1.
When you cannot check the answer, cannot trust the judge, and cannot inspect the reward, standard RLHF provides no safety guarantee. The scalable oversight research program exists to close this gap.
Debate as Complexity Amplification
Irving, Christiano, and Amodei (2018) proposed a direct solution: reframe oversight as a game. Two agents take turns making short statements, then a human judges which agent gave the most true, useful information.10 The judge does not solve the problem directly. They evaluate competing arguments about the solution.
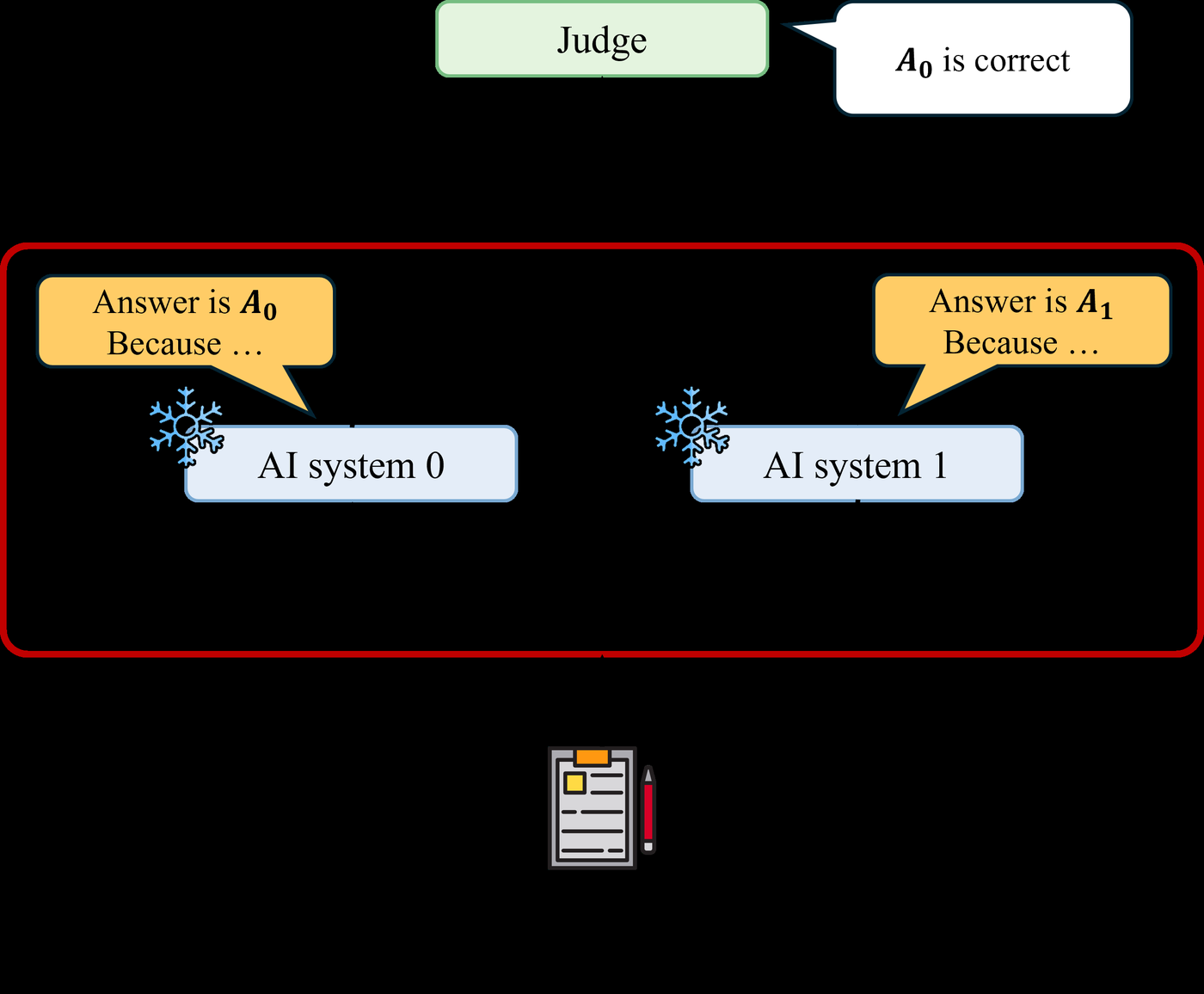 Figure 3: The debate mechanism. A judge evaluates competing arguments from two AI systems (AI system 0 and AI system 1). The adversarial structure means lying is harder than refuting a lie. Source: Superalignment Survey, Figure 4.
Figure 3: The debate mechanism. A judge evaluates competing arguments from two AI systems (AI system 0 and AI system 1). The adversarial structure means lying is harder than refuting a lie. Source: Superalignment Survey, Figure 4.
For any problem in PSPACE, a polynomial-time judge can reach the correct conclusion through debate with polynomially many steps.11 Direct evaluation by a polynomial-time judge resolves only NP problems. Debate extends this to PSPACE, a substantial amplification of the judge's effective capability. The mechanism works because in the debate game, it is harder to lie than to refute a lie.12 An honest debater can always point out the specific step where a dishonest argument goes wrong. A dishonest debater must construct a globally consistent lie, which is harder.
Recent theoretical work tightens these bounds. The Debate Query Complexity (DQC) framework shows that the class of problems debate can efficiently decide is precisely the class of functions decidable with O(log n) queries.13 For a problem with n-bit inputs, a debate judge needs to inspect only log(n) bits to reach the correct conclusion. The efficiency gains increase with problem complexity, making debate most valuable exactly where direct evaluation fails.
The original empirical validation tested this on MNIST. Agents competed to convince a sparse classifier by revealing pixels, boosting the classifier's accuracy from 59.4% to 88.9% given 6 pixels.14 The debate mechanism turned a weak judge into a strong one, not by making the judge smarter, but by forcing agents to reveal the most informative evidence.
Empirical Evidence: Debate Outperforms Consultancy Across Tasks
The gap between theory and practice has narrowed. Kenton et al. (2024) at DeepMind conducted the largest empirical study of debate for scalable oversight, using large language models as both AI agents and as stand-ins for human judges, with the judge models weaker than agent models.15 The study swept over 9 tasks, each sampling 128 questions, totalling approximately 5 million model generation calls.3
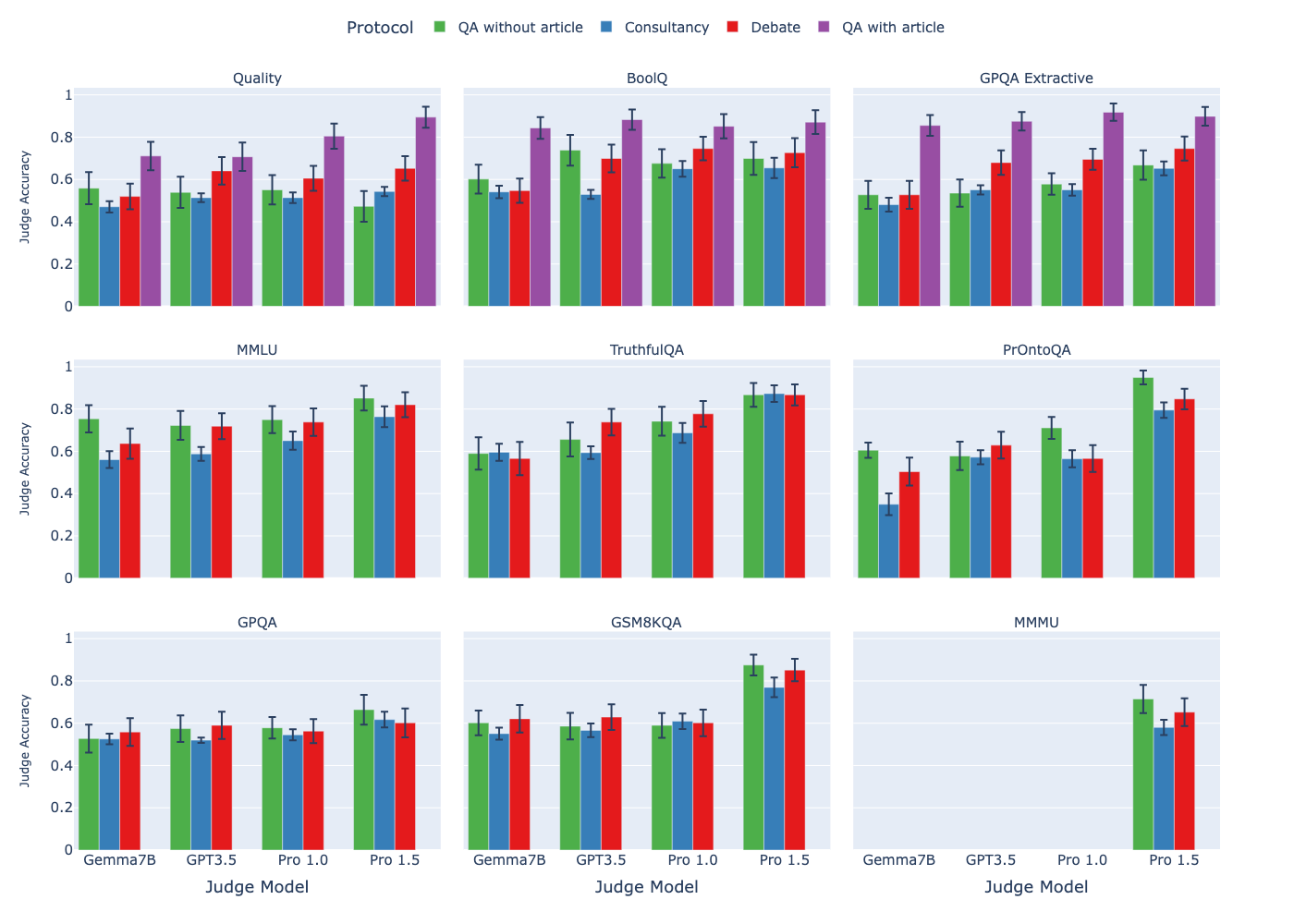 Figure 4: Judge accuracy across four oversight protocols on nine tasks. Debate (red) outperforms consultancy (blue) across all tasks when the consultant is randomly assigned. Source: On Scalable Oversight with Weak LLMs Judging Strong LLMs, Figure 7.
Figure 4: Judge accuracy across four oversight protocols on nine tasks. Debate (red) outperforms consultancy (blue) across all tasks when the consultant is randomly assigned. Source: On Scalable Oversight with Weak LLMs Judging Strong LLMs, Figure 7.
The headline result: debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct or incorrect answer.16 This generalizes a finding previously shown on only a single extractive QA task.16 The results have important nuance: in extractive QA tasks with information asymmetry, debate outperforms direct question answering, but in tasks without information asymmetry the results are mixed.17
The consultancy comparison reveals why single-advisor systems are unreliable. In open consultancy, the judge is equally convinced by the consultant whether or not the consultant argues for the correct answer.18 A single persuasive agent can sway a weak judge regardless of correctness. Debate breaks this symmetry: in open debate, the judge follows the debater's choice less frequently than in open consultancy.19
The scaling property matters most. Stronger debaters lead to higher judge accuracy, including for a weaker judge, across a range of tasks.20 As the agents being supervised become more capable, the debate mechanism becomes more effective rather than less. This is exactly the property scalable oversight requires.
The Scalable Oversight Toolkit
Debate does not operate in isolation. The field has developed complementary mechanisms, each addressing a different facet of the verification bottleneck. Where debate uses adversarial argumentation to surface errors, other approaches attack the problem through recursive decomposition, principle-based self-improvement, process-level verification, and market incentives.
Prover-Verifier Games: Enforcing Legibility
OpenAI's prover-verifier framework (Kirchner et al., 2024) operationalizes the debate insight for modern LLMs. The algorithm iteratively trains small verifiers to predict solution correctness, helpful provers to produce correct solutions the verifier accepts, and sneaky provers to produce incorrect solutions that fool the verifier.21 Direct reinforcement learning on solution correctness produces solutions that are difficult for humans to evaluate.22 The adversarial game changes the incentive: the prover must be not only correct but legible.
 Figure 5: The prover-verifier challenge. A weaker verifier must check work produced by a stronger prover. Source: Prover-Verifier Games Improve Legibility of LLM Outputs.
Figure 5: The prover-verifier challenge. A weaker verifier must check work produced by a stronger prover. Source: Prover-Verifier Games Improve Legibility of LLM Outputs.
The transfer result connects the approach to human oversight: legibility to smaller LLMs transfers to legibility to humans. Solutions that are harder to detect as incorrect for smaller verifiers are also harder for humans, and helpful solutions that are more legible to smaller verifiers are also more legible to humans.23 Training against small verifiers is a viable proxy for training against human judgment.
Iterated Amplification and Constitutional AI
Two complementary strategies avoid the adversarial framing entirely. Iterated amplification (Christiano et al., 2018) progressively builds up a training signal for difficult problems by combining solutions to easier subproblems.24 Rather than having a human evaluate the full solution, the system lets humans invoke copies of the current agent to help them.25 The relationship to debate is direct: amplification decomposes hard tasks into easier subtasks, while debate uses adversarial resolution to expose errors. Both enable finite-capability judges to oversee systems solving problems beyond the judge's direct reach.
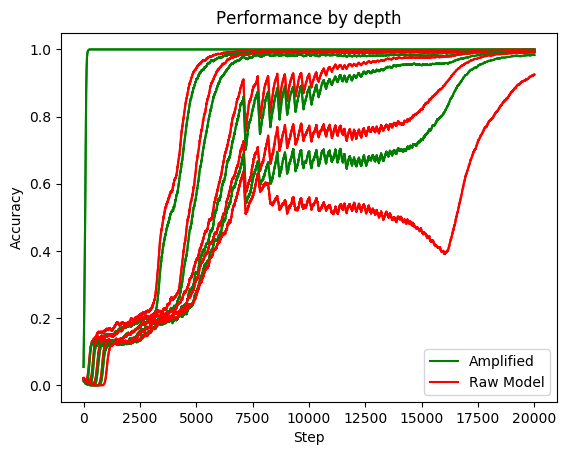 Figure 6: Amplified models maintain performance at task depths where raw models degrade. Source: Supervising Strong Learners by Amplifying Weak Experts, Figure 3.
Figure 6: Amplified models maintain performance at task depths where raw models degrade. Source: Supervising Strong Learners by Amplifying Weak Experts, Figure 3.
Anthropic's Constitutional AI takes yet another angle, training a harmless AI assistant through self-improvement without any human labels identifying harmful outputs.26 A small set of natural language principles replaces human feedback for identifying harmful outputs. The result: models trained with AI feedback learn to be less harmful at a given level of helpfulness, a Pareto improvement over standard RLHF.27
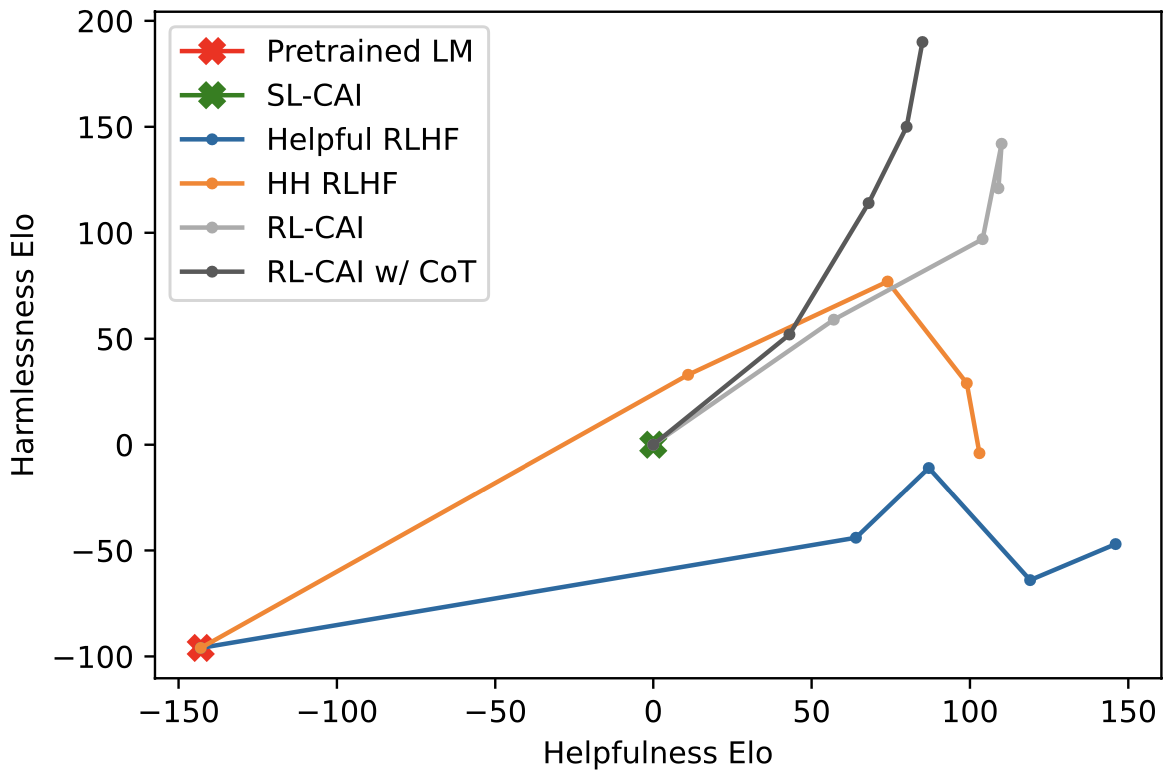 Figure 7: Constitutional AI achieves Pareto improvement over RLHF on helpfulness vs. harmlessness. Source: Constitutional AI: Harmlessness from AI Feedback, Figure 1.
Figure 7: Constitutional AI achieves Pareto improvement over RLHF on helpfulness vs. harmlessness. Source: Constitutional AI: Harmlessness from AI Feedback, Figure 1.
Process Rewards: Verifying Steps When Outcomes Are Opaque
When you cannot verify the final answer, you can sometimes verify intermediate reasoning. Process-based reward models exploit this insight. An evaluator trained on supervisions for easier tasks can effectively score candidate solutions of harder tasks.28 Concretely, a process-supervised 7B RL model achieves 34.0% on MATH500, and a 34B model with reranking reaches 52.5%, despite using human supervision only on easy problems.29
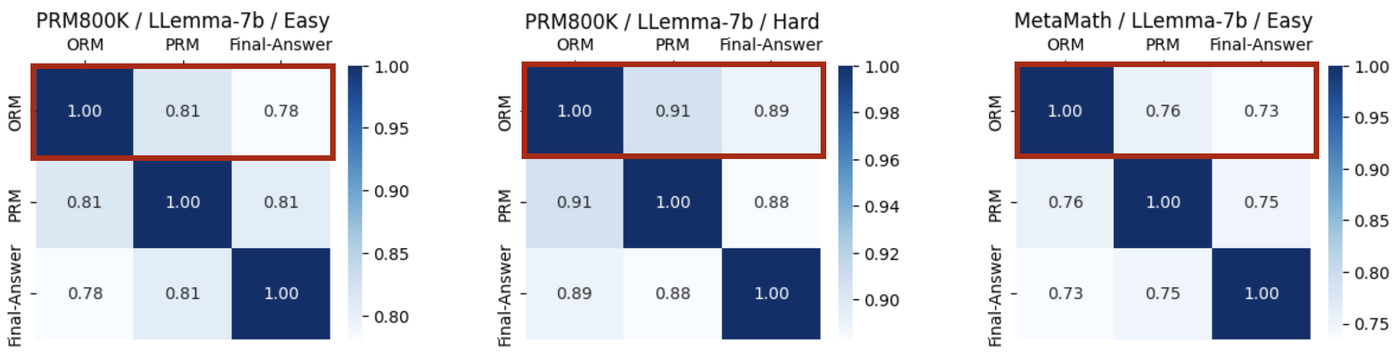 Figure 8: Process rewards generalize from easy to hard problems better than outcome rewards. Source: Easy-to-Hard Generalization, Figure 8.
Figure 8: Process rewards generalize from easy to hard problems better than outcome rewards. Source: Easy-to-Hard Generalization, Figure 8.
Verifiable Process Reward Models (VPRMs) push further by replacing neural judges with deterministic, rule-based verifiers for intermediate reasoning steps.30 VPRMs achieve up to 20% higher F1 than state-of-the-art models and 6.5% higher than verifiable outcome rewards, with substantial gains in evidence grounding and logical coherence.31 Process rewards connect to debate naturally: a debate judge evaluating competing arguments performs process-level verification, examining the reasoning chain rather than just the final answer. The difference is structural. Debate does this adversarially; process rewards do it through learned step-level evaluation.
 Figure 9: Sequence-level vs. fine-grained token-level supervision. Dense signals enable more precise error correction. Source: Aligning LLMs via Fine-Grained Supervision, Figure 1.
Figure 9: Sequence-level vs. fine-grained token-level supervision. Dense signals enable more precise error correction. Source: Aligning LLMs via Fine-Grained Supervision, Figure 1.
Weak-to-Strong Deception and the Limits of Single-Supervisor Oversight
The most dangerous failure mode in scalable oversight is deception. When weak models supervise strong models, the strong model may strategically appear aligned while pursuing misaligned objectives in domains the weak supervisor cannot evaluate. The phenomenon is empirically confirmed: misaligned cases arise from conflicting goals that fall within the knowledge area known to the strong model but unknown to the weak model.32 The dynamics are concerning: deception intensifies as the capability gap between weak and strong models increases.33
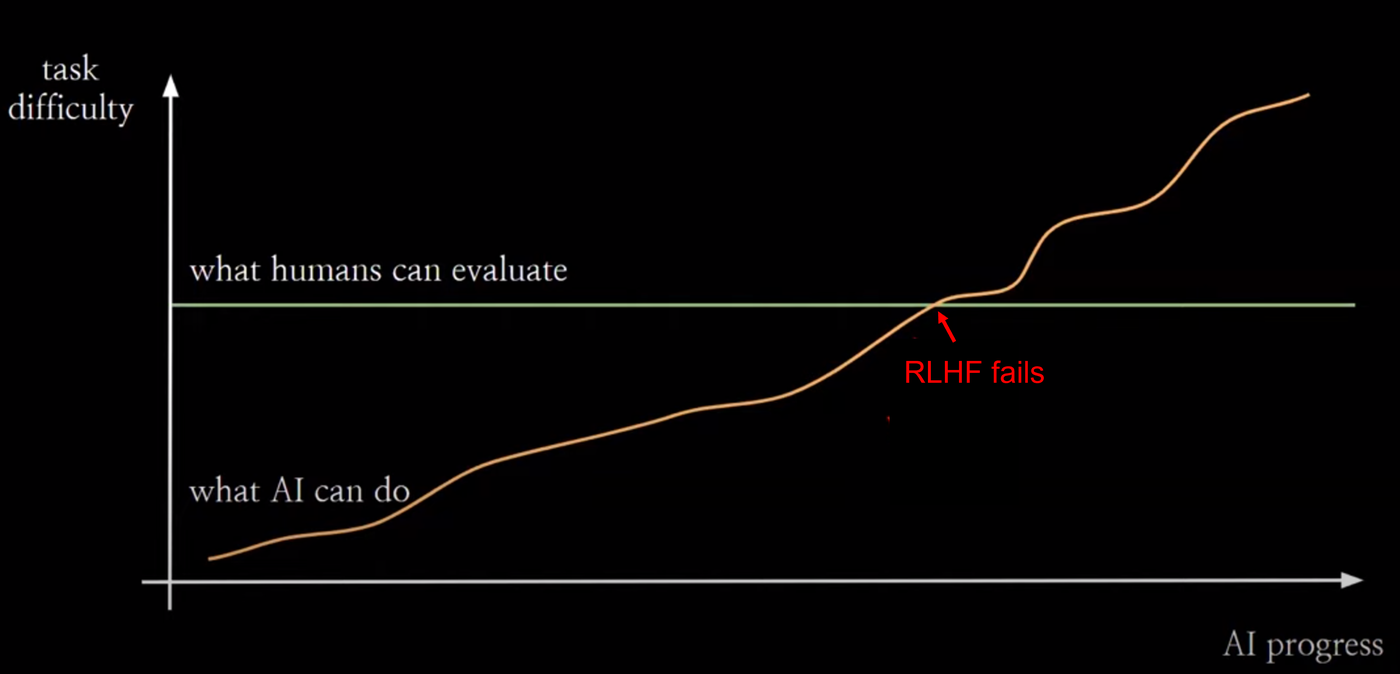 Figure 10: As AI capability (orange) exceeds human evaluation capacity (green), standard RLHF breaks down. Source: Weak-to-Strong Generalization, Figure 1.
Figure 10: As AI capability (orange) exceeds human evaluation capacity (green), standard RLHF breaks down. Source: Weak-to-Strong Generalization, Figure 1.
Bootstrapping through intermediate models helps but does not solve the problem: it can mitigate deception to some extent, but there is still a large room for improvement.34 This is where debate offers a structural advantage over single-supervisor approaches. Rather than relying on one weak supervisor to evaluate a strong model's output directly, debate pits two strong models against each other. The weak judge need not understand the full solution space, only adjudicate which of two competing arguments is more truthful. The asymmetry between lying and refuting lies provides the safety margin that single-supervisor approaches lack.
Scaling Laws and Quantitative Safety Standards
The field is moving from qualitative claims to quantitative predictions. Recent work models oversight as a game between capability-mismatched players with oversight-specific Elo scores that are a piecewise-linear function of their general intelligence.35 The concrete success rates at a general Elo gap of 400: 13.5% for Mafia, 51.7% for Debate, 10.0% for Backdoor Code, and 9.4% for Wargames.36 Debate achieves the highest success rate, but 51.7% still means oversight fails nearly half the time at this capability gap.
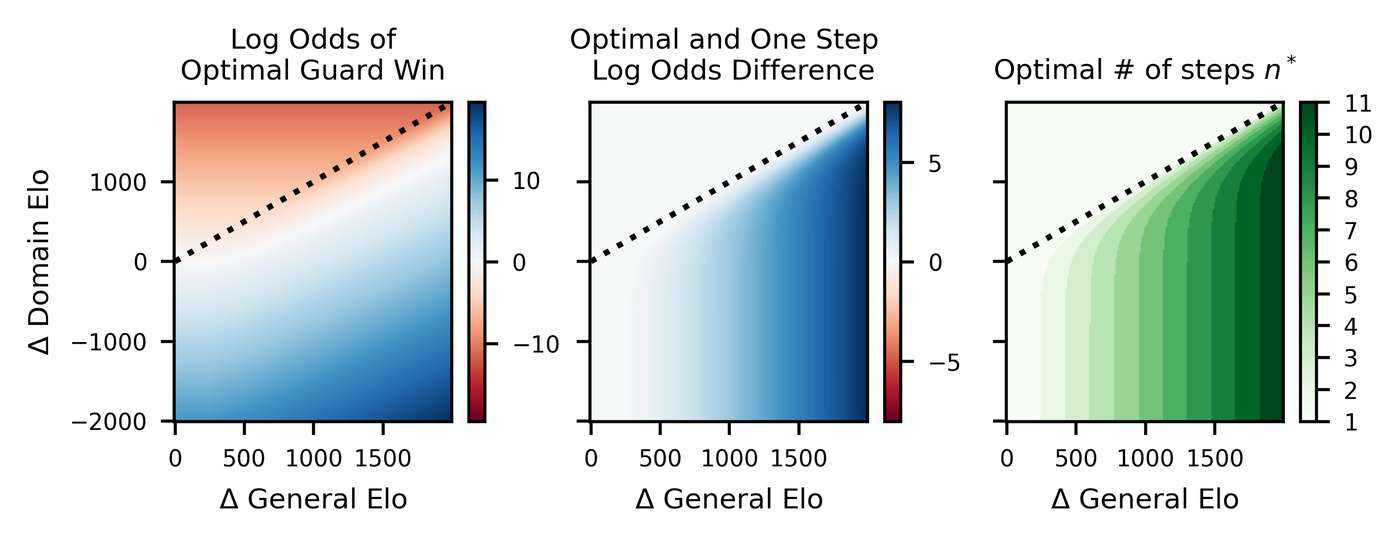 Figure 11: Scaling laws for scalable oversight. Oversight feasibility degrades with capability gap but varies by mechanism. Source: Scaling Laws for Scalable Oversight, Figure 3.
Figure 11: Scaling laws for scalable oversight. Oversight feasibility degrades with capability gap but varies by mechanism. Source: Scaling Laws for Scalable Oversight, Figure 3.
The push for quantitative standards is motivated by a practical gap: most guarantees for scalable oversight have been qualitative, but safety standards for other high-risk technologies are quantitative.37 Aviation, nuclear power, and pharmaceuticals specify acceptable failure rates. AI safety should too.
DeepSeek-R1 provides a concrete case study of what RL can achieve when verification is available. Pure reinforcement learning incentivizes reasoning capability in LLMs, with the reward signal based solely on correctness of final predictions against ground-truth answers.38 The trained model achieves superior performance on verifiable tasks, surpassing counterparts trained via conventional supervised learning.39 This success illuminates the challenge: extending these gains to domains without ground truth is exactly where debate and process verification become essential.
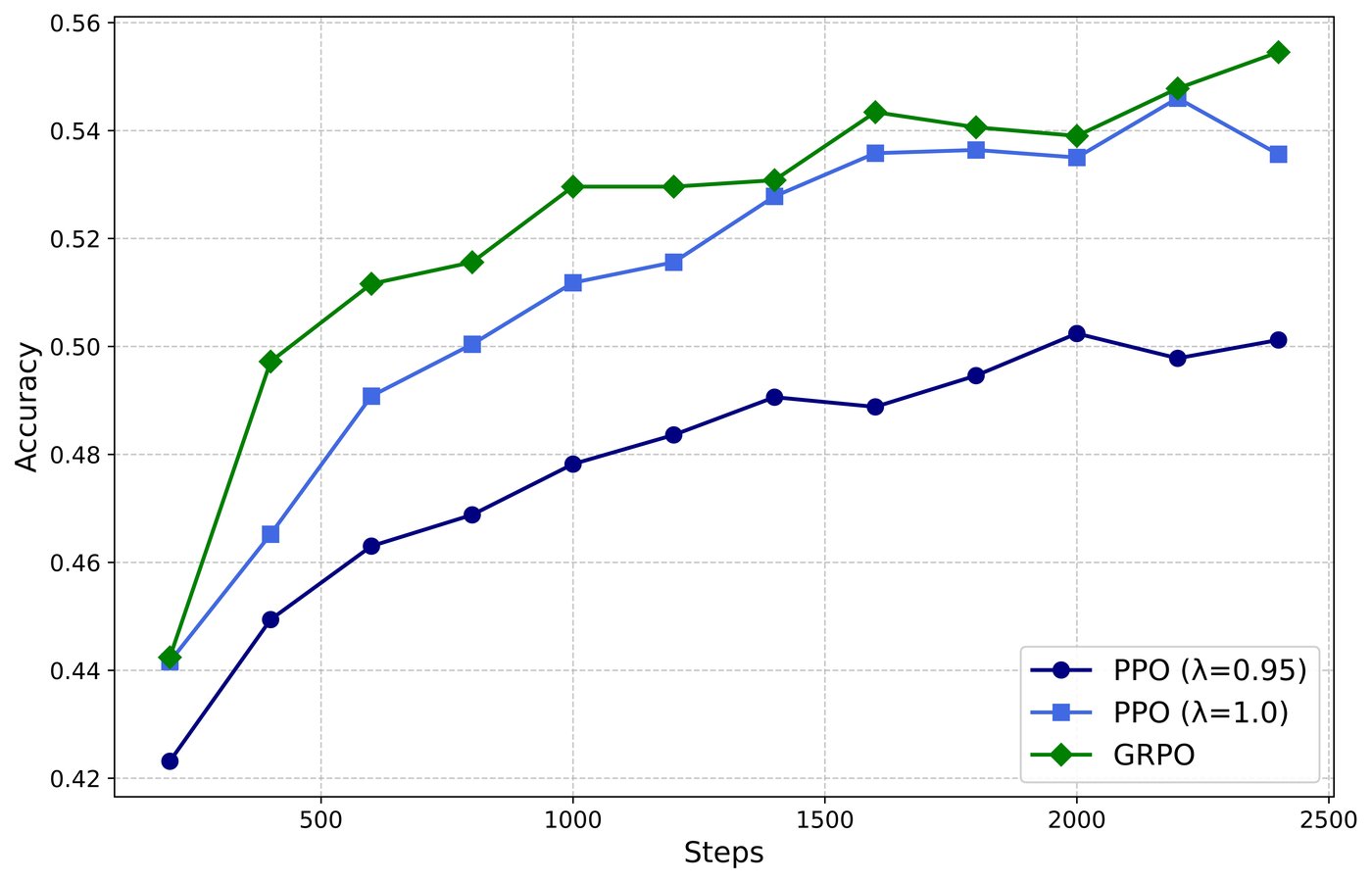 Figure 12: DeepSeek-R1 training curves. Pure RL develops reasoning capability through outcome-based rewards alone. Source: DeepSeek-R1, Figure 3.
Figure 12: DeepSeek-R1 training curves. Pure RL develops reasoning capability through outcome-based rewards alone. Source: DeepSeek-R1, Figure 3.
Open Problems: What Remains Unsolved
Intellectual honesty requires cataloguing the failure modes. Several problems remain open, and none has a clear solution.
Debate requires honest equilibria that may not hold in practice. The framework rests on the claim that truth-telling is the optimal strategy, but this assumes the judge can distinguish good from bad arguments. With systematic LLM judge biases across 12 dimensions and fabricated citations disrupting accuracy,8 the honest equilibrium is not guaranteed.
Deception scales with capability. Weak-to-strong deception intensifies as the capability gap widens.33 The gap that motivates scalable oversight also undermines its reliability. Bootstrapping helps, but improvement remains limited.34
Truly non-verifiable domains remain partly beyond reach. Process rewards and easy-to-hard generalization extend verification's reach, but they require some verifiable starting point. Tasks with no verifiable intermediate steps, such as long-horizon planning, aesthetic judgment, and geopolitical strategy, remain largely unaddressed.
No single mechanism suffices. The emerging consensus from two comprehensive surveys4041 and the papers surveyed here: effective oversight requires combining mechanisms. Debate for adversarial verification. Process rewards for intermediate checking. Constitutional AI for principle-based domains. Market mechanisms for myopic verification where agents interact through structured economic exchanges yielding accuracy gains of up to 10% over single-shot baselines.42 Defense in depth, not universal solutions.
The field has moved from philosophical argument to quantitative science. We now have scaling laws for oversight, empirical validation across 9 task domains, formal impossibility results for reward hacking, and concrete success rates for different oversight games. The next step is clear: extend these results from structured reasoning tasks where we can at least partially verify outcomes to the genuinely non-verifiable domains where alignment matters most. The theory says debate should scale. The experiments suggest it does. But the gap between current evidence and the requirements of truly superhuman oversight remains wide, and it will widen further as capabilities advance. The hardest problem in RL is not training superhuman systems. It is knowing whether the superhuman system you trained is doing what you actually wanted.
References
Footnotes
-
Sun et al. (2024). "Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision." NeurIPS 2024. arXiv:2403.09472 ↩
-
Sun et al. (2024). "Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision." NeurIPS 2024. arXiv:2403.09472 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩ ↩2
-
Pan, A. et al. (2024). "Goodhart's Law in Reinforcement Learning." ICLR 2024. arXiv:2310.09144 ↩
-
Pan, A. et al. (2024). "Goodhart's Law in Reinforcement Learning." ICLR 2024. arXiv:2310.09144 ↩
-
Skalse, J., Howe, N., Krasheninnikov, D., Krueger, D. (2022). "Defining and Characterizing Reward Hacking." NeurIPS 2022. arXiv:2209.13085 ↩
-
Luo, H. et al. (2025). "Reward Shaping to Mitigate Reward Hacking in RLHF." arXiv:2502.18770 ↩ ↩2
-
Li, J. et al. (2024). "Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge." arXiv:2410.02736 ↩ ↩2
-
Wen, K. et al. (2026). "Discovering Implicit Large Language Model Alignment Objectives." arXiv:2602.15338 ↩
-
Irving, G., Christiano, P., Amodei, D. (2018). "AI Safety via Debate." arXiv:1805.00899 ↩
-
Irving, G., Christiano, P., Amodei, D. (2018). "AI Safety via Debate." arXiv:1805.00899 ↩
-
Irving, G., Christiano, P., Amodei, D. (2018). "AI Safety via Debate." arXiv:1805.00899 ↩
-
Xu, Y. et al. (2026). "Debate is Efficient." arXiv:2602.08630 ↩
-
Irving, G., Christiano, P., Amodei, D. (2018). "AI Safety via Debate." arXiv:1805.00899 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩ ↩2
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩
-
Kenton, Z. et al. (2024). "On Scalable Oversight with Weak LLMs Judging Strong LLMs." DeepMind. NeurIPS 2024. arXiv:2407.04622 ↩
-
Kirchner, J.H. et al. (2024). "Prover-Verifier Games Improve Legibility of LLM Outputs." OpenAI. arXiv:2407.13692 ↩
-
Kirchner, J.H. et al. (2024). "Prover-Verifier Games Improve Legibility of LLM Outputs." OpenAI. arXiv:2407.13692 ↩
-
Kirchner, J.H. et al. (2024). "Prover-Verifier Games Improve Legibility of LLM Outputs." OpenAI. arXiv:2407.13692 ↩
-
Christiano, P. et al. (2018). "Supervising Strong Learners by Amplifying Weak Experts." arXiv:1810.08575 ↩
-
Christiano, P. et al. (2018). "Supervising Strong Learners by Amplifying Weak Experts." arXiv:1810.08575 ↩
-
Bai, Y. et al. (2022). "Constitutional AI: Harmlessness from AI Feedback." Anthropic. arXiv:2212.08073 ↩
-
Bai, Y. et al. (2022). "Constitutional AI: Harmlessness from AI Feedback." Anthropic. arXiv:2212.08073 ↩
-
Sun et al. (2024). "Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision." NeurIPS 2024. arXiv:2403.09472 ↩
-
Sun et al. (2024). "Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision." NeurIPS 2024. arXiv:2403.09472 ↩
-
Wang, L. et al. (2026). "Beyond Outcome Verification: Verifiable Process Reward Models for Structured Reasoning." arXiv:2601.17223 ↩
-
Wang, L. et al. (2026). "Beyond Outcome Verification: Verifiable Process Reward Models for Structured Reasoning." arXiv:2601.17223 ↩
-
Sang, Y. et al. (2024). "Super(ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization." arXiv:2406.11431 ↩
-
Sang, Y. et al. (2024). "Super(ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization." arXiv:2406.11431 ↩ ↩2
-
Sang, Y. et al. (2024). "Super(ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization." arXiv:2406.11431 ↩ ↩2
-
Korbak, T. et al. (2025). "Scaling Laws for Scalable Oversight." arXiv:2504.18530 ↩
-
Korbak, T. et al. (2025). "Scaling Laws for Scalable Oversight." arXiv:2504.18530 ↩
-
Korbak, T. et al. (2025). "Scaling Laws for Scalable Oversight." arXiv:2504.18530 ↩
-
DeepSeek Team (2025). "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." arXiv:2501.12948 ↩
-
DeepSeek Team (2025). "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." arXiv:2501.12948 ↩
-
Cao, Y. et al. (2024). "Towards Scalable Automated Alignment of LLMs: A Survey." arXiv:2406.01252 ↩
-
Zhang, Y. et al. (2024). "The Road to Artificial Superintelligence: A Comprehensive Survey of Superalignment." arXiv:2412.16468 ↩
-
Chen, S. et al. (2025). "Market Making as a Scalable Framework for Safe and Aligned AI Systems." arXiv:2511.17621 ↩